蒸馏:AI 世界里的"吸星大法"
Posted on 日 05 4月 2026 in AI
| Abstract | 蒸馏:AI 世界里的"吸星大法" |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Version | v1.0 |
| Updated | 2026-04-05 |
| License | CC-BY-NC-ND 4.0 |
短大纲
- 从"蒸馏"这个词的化学隐喻切入,解释为什么 AI 圈也用这个词
- 模型蒸馏:Hinton 2015 年的"暗知识"、Teacher-Student 范式、DeepSeek-R1 的实战成绩
- 技能蒸馏:Agent 的 Skill 文件为什么也需要压缩,6:1 压缩率怎么做到的
- OpenAI 把蒸馏做成了产品级 API:Stored Completions → Fine-tuning 的一条龙
- Anthropic 的另一面:防蒸馏攻击——你蒸馏别人的模型,可能违法
- 最后给一份"什么时候该蒸馏、什么时候别蒸馏"的决策清单
2026-04-05
你上化学课时大概学过蒸馏——把混合液加热,不同沸点的成分依次气化,冷凝后接住你想要的那一份。粗暴点说,就是从一大锅东西里,把精华提出来。
AI 圈用了同一个词,干的事情也差不多:把一个又大又贵的模型里最值钱的"知识",提炼到一个又小又快的模型里。
如果你看过金庸,可能会想到北冥神功——"北冥有鱼,其名为鲲",段誉用它把别人的内力化为己用,关键不在自己多厉害,而在于吸收和转化的效率。AI 蒸馏干的基本就是这件事:把大模型几百亿参数里练出来的"内力",灌到一个小模型里,让它四两拨千斤。
这两年蒸馏这个词的出镜率越来越高。DeepSeek 用它把 671B 参数的推理能力塞进了 1.5B 的小模型;OpenAI 把它做成了一套产品级 API,点几下就能从 GPT-4o 蒸出一个便宜版;Anthropic 甚至专门发了一篇文章,讲怎么防止别人偷偷蒸馏 Claude。
更有意思的是,蒸馏不只是模型的事。这一波 AI Agent 热潮里,连 Agent 的 Skill(技能文件)也开始讲蒸馏了——你写了一坨 3000 字的技能说明,喂给 LLM 吃 token 吃到撑,有人就搞了个工具,能把它压缩到原来的六分之一,语义还不丢。
这篇就把"蒸馏"这件事掰开了讲:模型蒸馏怎么回事,技能蒸馏又是怎么回事,什么时候该蒸,什么时候别蒸。
模型蒸馏:从 Hinton 的"暗知识"说起
2015 年,Geoffrey Hinton——就是后来拿了诺贝尔奖的那位深度学习教父——和 Google 的同事发了一篇论文:Distilling the Knowledge in a Neural Network。论文里有个当时听起来有点反直觉的判断:
一个大模型"犯的错误",比它"给的正确答案"还有价值。
什么意思?
假设你训练了一个图像分类模型,输入一张猫的图片,正确答案是"猫"。标准训练只看这个硬标签(hard label):对了就奖励,错了就惩罚。
但 Hinton 说,你别只看最终答案。看看大模型输出的完整概率分布——它可能给了"猫"90%,"虎"5%,"狗"3%,"汽车"0.001%。这里面"虎比狗更像猫"这条信息,硬标签里是看不到的,但它包含了类别之间的相似性关系。Hinton 管这叫暗知识(dark knowledge)。
蒸馏的核心操作,就是让一个小模型(学生)去学大模型(老师)的这种"软概率分布",而不是只学对错。
用个不太严谨的比喻:硬标签训练就像只看标准答案,蒸馏训练像是坐在学霸旁边,不光抄答案,还能看到他划掉的草稿、犹豫的过程、排除的选项。那些"差点选对的错误答案",才是真正值钱的东西。
Teacher-Student 范式
蒸馏的基本架构很简单:
[大模型 Teacher] ──输出软概率──> [小模型 Student]
│
同时也学硬标签
│
最终:小而能干
训练时有两个损失函数并行:
- 蒸馏损失:学生的输出 vs 老师的软概率分布(通过调高"温度"参数让分布更平滑)
- 任务损失:学生的输出 vs 真实标签
温度(temperature)是一个关键超参数。温度越高,老师的概率分布越"软",类别之间的差异越平缓,暗知识暴露得越多。Hinton 论文里典型的温度值在 1 到 20 之间。
三种蒸馏路径
十年下来,蒸馏大致走出了三条路:
| 方法 | 学什么 | 适合场景 |
|---|---|---|
| 响应蒸馏(Response-based) | 老师的最终输出概率 | 通用,最常见 |
| 特征蒸馏(Feature-based) | 老师中间层的隐藏表示 | 迁移学习、视觉任务 |
| 注意力蒸馏(Attention-based) | 老师的注意力权重模式 | Transformer、LLM 推理 |
到了大模型时代,还多了一种更实用的变体:直接用老师的输出文本做监督微调(SFT)。你不需要拿到老师的权重,只需要老师的高质量输出,就能训一个学生。DeepSeek-R1 的蒸馏就是这么干的。
DeepSeek-R1:蒸馏的教科书级案例
要讲蒸馏有多猛,绕不开 DeepSeek-R1。
2025 年初,DeepSeek 发布了 R1——一个 671B 参数的推理模型,在数学和编程任务上能打平甚至超过 OpenAI o1。但 671B 参数的模型,推理成本极高,普通开发者跑不起。
于是他们做了一件事:从 R1 的推理过程中,挑出大约 80 万条高质量的 chain-of-thought 推理轨迹,涵盖数学、逻辑、编程等高难度任务。然后用这些数据,对一批小模型做 SFT。
结果很猛:
| 蒸馏模型 | 参数量 | MATH-500 | AIME 2024 | 对比 |
|---|---|---|---|---|
| R1-Distill-Qwen-1.5B | 1.5B | 83.9 | 28.9 | 1.5B 能做数学题 |
| R1-Distill-Qwen-7B | 7B | 92.8 | 55.5 | 超越很多更大的指令微调模型 |
| R1-Distill-Qwen-32B | 32B | 94.3 | 72.6 | 打平 OpenAI o1-mini |
| R1-Distill-Llama-70B | 70B | 94.5 | 57.5 | 接近完整 R1 |
你看这个数字:一个 1.5B 的模型——跑在手机上都够用的体量——在 MATH-500 上能拿 83.9 分。这不是靠模型本身多聪明,而是 671B 老师的推理模式被"蒸"进去了。
就像带实习生。他没有老专家的阅历和脑容量,但你把老专家解题的思考过程详细记录下来,让他反复练,同类问题上的表现会远超预期。
关键点:DeepSeek 的蒸馏没有用强化学习(RL),纯靠 SFT。他们在论文里也提到,对小模型来说,先用蒸馏打底、再加 RL 的效果反而不如纯蒸馏。这说明对小模型而言,高质量的推理轨迹本身就是最好的训练信号。
OpenAI 把蒸馏做成了产品
DeepSeek 展示了蒸馏的天花板,而 OpenAI 干的事正好反过来——把门槛降到了地板。
2024 年底,OpenAI 在 API 里上线了一套 Model Distillation 工具链,思路很清晰:
1. 你正常调 GPT-4o / o1 的 API,加一个 store=True 参数
2. 输入输出自动存下来(Stored Completions)
3. 你筛选、打标、过滤这些数据
4. 一键发起 fine-tuning job,把 GPT-4o-mini 或更小的模型训出来
5. 用 Evals 跑一遍评估,确认效果
整个流程在一个平台上闭环。以前你要做蒸馏,得自己写脚本抓数据、清洗、格式化、上传、训练、评估。现在基本上就是几个 API 调用的事。
# 第一步:调 GPT-4o 时开启存储
response = client.chat.completions.create(
model="gpt-4o",
messages=[{"role": "user", "content": "解释什么是知识蒸馏"}],
store=True,
metadata={"task": "distillation-explainer", "quality": "good"}
)
# 第二步:攒够数据后,用 Stored Completions 创建训练集
# 第三步:发起 fine-tuning,目标模型选 gpt-4o-mini
# 第四步:跑 Evals 对比效果
OpenAI 给出的数据是:蒸馏后的小模型在特定任务上,能保留原模型 95-97% 的性能,同时成本降低 5-30 倍,推理速度快 4 倍。
你在生产环境跑 GPT-4o,一个月的 API 费用可能是几万美元。蒸馏出一个 GPT-4o-mini 级别的专用模型,效果只差一点点,成本砍掉 80%——这笔账谁都会算。
蒸馏的另一面:技能蒸馏
到这儿你可能觉得蒸馏只跟大模型有关。但最近半年,另一种"蒸馏"开始冒头了:Agent Skill 的蒸馏。
如果你用过 Claude Code、Cursor、OpenClaw 这类 AI Agent,你会知道它们有一套 Skill 系统——用 Markdown 写的技能文件,告诉 Agent 怎么做某类任务。一个 Skill 文件可能长这样:
# Code Review Skill
## When to Use
Use when the user asks for code review, MR review...
## Steps
1. Read the diff carefully
2. Check for security issues (see checklist below)
3. Check for performance issues
4. Provide structured feedback using the template
## Security Checklist
- [ ] No hardcoded secrets
- [ ] Input validation present
- [ ] SQL injection prevention
...(后面还有 2000 字)
问题来了:Skill 文件一长,token 成本就上去了。
每次 Agent 加载一个 Skill,都要把它塞进 context window。你写了 10 个 Skill,每个 3000 字,光技能说明就吃掉了一大块上下文窗口。模型能用来思考实际问题的空间就被挤压了。
这和大模型蒸馏的痛点其实是一回事:原始知识太"胖"了,需要在保留核心语义的前提下,把体积压下来。
GitHub 上已经出现了专门做这件事的工具,比如 skills-optimizer,号称能做到 6:1 的压缩率,同时通过 LLM 验证保证语义不丢。
它的思路大致是:
- 读入原始 Skill 文件
- 用 LLM 分析哪些内容是核心指令、哪些是冗余解释、哪些是可以精简的示例
- 生成压缩版本
- 再用 LLM 对比原版和压缩版,验证语义一致性
- 输出压缩后的 Skill
这里要先说清一件事:Skill 的蒸馏,和模型蒸馏不是一个层面的事。
- 模型蒸馏,蒸的是权重里的能力
- Skill 蒸馏,蒸的是文档里的规则、步骤和约束
前者是在训一个更小的模型,后者更像是在给 Agent 的操作手册“瘦身”。模型蒸馏完,小模型真的变了;Skill 蒸馏完,变的不是模型本身,而是喂给模型的那份说明书。
这点很关键。很多人一听“技能蒸馏”,以为是把一个复杂 Agent 训成一个简单 Agent。其实多数时候没那么玄,它更接近:
原版 Skill(3000 字) -> 提取核心约束和步骤 -> 压缩成 500 字精华版 -> 再验证语义没跑偏
说白了,Skill 蒸馏不是“重新练功”,而是“把口诀从一本书压成一张小抄”。功夫还是那套功夫,只是背起来轻多了。
Skill 到底蒸了什么?
一个写得很长的 Skill,通常混着四类东西:
- 触发条件:什么时候该用这个 Skill
- 核心步骤:做事顺序,先干什么,后干什么
- 硬约束:什么绝对不能做,什么必须检查
- 辅助说明:例子、解释、背景、语气修饰
真正要蒸的,主要是前 3 类;最容易被压缩掉的,是第 4 类。
这就像咱们写技术方案。真正不能丢的,是边界条件、失败路径、执行顺序;最容易注水的,是那些“为了帮助理解”写出来的铺垫和例子。Skill 也是一样。一个好的蒸馏器,不是把所有文字都平均裁短,而是要识别出:
- 哪些是“必须保留”的指令
- 哪些是“可有可无”的解释
- 哪些例子可以删
- 哪些例子删了就会误伤语义
举个例子:把一个 Code Review Skill 蒸一遍
比如原版 Skill 长这样:
# Code Review Skill
## When to Use
Use this skill when the user asks for a code review, merge request review,
security review, pull request analysis, or asks whether a patch is safe.
## Review Goals
- Identify correctness bugs
- Identify security issues
- Identify performance regressions
- Identify missing tests
- Prioritize findings by severity
## Steps
1. Read the full diff
2. Read surrounding files if needed
3. Check entry points and trust boundaries
4. Validate error handling and fallback paths
5. Look for secrets, auth issues, input validation gaps
6. Check test coverage
7. Write findings first, summary second
## Important
- Never start with praise
- Never give vague feedback
- Always cite concrete evidence
- If no bug found, explicitly say no findings
## Example Output
...(后面还有很多例子和格式说明)
蒸完之后,理想状态可能是这样:
# Code Review Skill
Use for PR/MR/code review requests.
Goals: bugs, security, perf, missing tests.
Process:
1. Read diff and nearby context
2. Check trust boundaries, validation, auth, secrets
3. Check error paths, regressions, test gaps
4. Output findings first, summary after
Must preserve:
- cite concrete evidence
- no vague praise
- say \"no findings\" explicitly when applicable
你看,短了很多,但真正管用的骨架还在:
- 触发条件还在
- 审查目标还在
- 执行顺序还在
- 输出约束还在
被蒸掉的,主要是大段解释、重复示例、措辞修饰。这就好比把一份 10 页的会议纪要,压成一张 A4 的行动清单。废话少了,执行力反而上去了。
当然,这里有个坑:Skill 不是越短越好。
如果你把上面那份 Skill 继续压,压成这样:
Review code for bugs and security. Be concise.
那就不是蒸馏了,那叫练功练到走火入魔。短是短了,但有用的信息几乎没了。Agent 看完只会知道“去审代码”,却不知道先看什么、重点看什么、输出按什么格式写。这样的压缩,只是把 token 省下来了,把质量也一起省没了。
怎么判断一个 Skill 蒸得好不好?
我觉得至少要过三关:
- 任务不变:原 Skill 能做的事,压缩版还得能做
- 顺序不乱:先后步骤不能颠倒,尤其是安全检查和输出格式
- 硬约束不丢:像“不能泄露 secrets”“先给 findings 再给总结”这种规则,必须原封不动留下来
如果再认真一点,可以做一个最小回归测试。拿原 Skill 和蒸馏后的 Skill,喂给同一个模型、同一组任务,看输出有没有明显偏差。比如测 5 组请求:
- “Review this PR for bugs”
- “Check for security issues”
- “Do a fast review”
- “No issue found, how should you respond?”
- “Summarize first, findings later”
如果蒸馏版在前 4 组表现一致,但在第 5 组开始把输出顺序搞反了,那就说明你把关键约束蒸没了。
所以一个靠谱的 Skill 蒸馏流程,最好不是“压一次就完事”,而是下面这样:
提取核心规则 -> 压缩 -> 语义对比 -> 任务回归测试 -> 不过就回滚
你看,这已经很像软件工程里的重构了。重构不是把代码写短,而是在不改变行为的前提下,让结构更紧凑。Skill 蒸馏本质上也是这个活。
拿来和模型蒸馏对照一下:
| 模型蒸馏 | 技能蒸馏 | |
|---|---|---|
| 原始形态 | 大参数模型 | 长 Skill 文件 |
| 瓶颈 | 推理成本高、部署重 | 占 token、挤压上下文 |
| 核心操作 | 用大模型输出训小模型 | 用 LLM 压缩保语义 |
| 目标 | 小而能干 | 短而精准 |
| 验证方式 | benchmark 跑分 | 语义一致性校验 |
两件事看起来一个是模型、一个是文档,但内核一样:从臃肿的原始知识中,提炼出紧凑的、可部署的精华。
Anthropic 的警告:蒸馏也有灰色地带
说了一圈好处,也得讲讲不好听的:蒸馏可以是技术手段,也可以是攻击手段。
还是用金庸的话来说:北冥神功是自家师门正经传的功夫,而吸星大法呢?任我行偷练吸星大法,吸人内力,固然短期功力暴涨,但来路不正的内力迟早反噬。AI 蒸馏的灰色地带,跟这个道理差不多。
2026 年 2 月,Anthropic 发了一篇文章,披露了三家中国 AI 实验室——DeepSeek、Moonshot(Kimi)、MiniMax——对 Claude 发起了工业级别的蒸馏攻击。通过大约 24000 个虚假账号,生成了超过 1600 万条对话,专门针对 Claude 最擅长的能力:agentic reasoning、tool use、coding。
说白了就是拿 Claude 当免费老师——疯狂提问,把高质量回答攒起来,训自己的模型。
这在技术上完全可行——前面讲过,SFT 蒸馏只需要老师的输出文本,不需要权重。但在商业和法律层面,这是另一回事了。大多数商业模型的服务条款明确禁止用输出来训练竞品模型。
Anthropic 后来做了几件事来应对:
- 检测异常使用模式(大量结构化提问、密集采样特定能力领域)
- 封禁涉嫌蒸馏的账号
- 在输出中嵌入水印(watermarking),用于事后追溯
- 发表技术报告,把这件事公开化
道理很简单:蒸馏自己的大模型叫降本增效,蒸馏别人的大模型叫偷。 技术上一样,法律上天壤之别。
什么时候该蒸馏?一份决策清单
蒸馏不是万能的。该蒸的时候蒸,能省大钱;不该蒸的时候硬蒸,可能白费功夫。
适合蒸馏的场景
| 场景 | 原因 |
|---|---|
| 你有一个跑得很好但很贵的大模型 | 典型的蒸馏起点 |
| 任务类型相对固定(客服、摘要、分类) | 固定任务最容易蒸,效果最稳 |
| 你需要边缘部署或离线运行 | 大模型塞不进手机/IoT 设备 |
| API 费用让你的 CFO 开始皱眉 | 降本最直接的技术手段之一 |
| 你的 Agent Skill 文件膨胀到几千字 | 该给技能"减肥"了 |
| 你需要更快的响应速度 | 小模型推理天然快 |
不适合蒸馏的场景
| 场景 | 原因 |
|---|---|
| 任务类型多变、开放性强 | 蒸馏偏窄化,不适合通用推理 |
| 你没有足够多的高质量老师输出 | 垃圾进垃圾出,数据质量是命门 |
| 目标模型太小,和老师差距太大 | 小模型容量有限,塞不进太多知识 |
| 你想蒸别人家的商业模型 | 法律风险,别碰 |
| 你的任务对最新知识依赖很高 | 蒸馏是静态快照,不是实时更新 |
决策流程
你有一个又大又贵的模型跑在生产环境?
├── 是 → 任务类型是否固定或可归类?
│ ├── 是 → 有足够的高质量输出数据?
│ │ ├── 是 → ✅ 蒸馏吧
│ │ └── 否 → 先攒数据(开 store=True)
│ └── 否 → 考虑 prompt 优化或 RAG,蒸馏可能不划算
└── 否 → 你的问题可能不是蒸馏能解决的
蒸馏背后更大的一个思考
跳出技术细节想一想。蒸馏的本质是什么?四个字:知识的压缩传递。
从 Hinton 2015 年提出"暗知识",到 DeepSeek 用 80 万条推理轨迹训出 1.5B 的小模型,到 OpenAI 把蒸馏做成点击即用的 API,到 Agent 的 Skill 文件也开始讲压缩——你会发现一个共同的模式:
越是复杂的系统,越需要把知识从"原始形态"压缩成"可传递形态"。
大模型的原始形态是几百 GB 的权重,压缩后变成几个 GB 的小模型。Agent 的原始形态是几千字的 Skill 文档,压缩后变成几百字的精华版。一个老工程师的原始形态是二十年的经验,压缩后变成一份 CheckList、一套 SOP、一篇文章。
你看,蒸馏这件事,人类一直在做。师傅带徒弟,就是蒸馏。写教材,就是蒸馏。Code Review 时留下的 comment,也是蒸馏。武侠小说里师傅把毕生功力灌顶给弟子,也是蒸馏——只不过金庸那个版本损耗太大,师傅往往要搭上半条命。
只不过以前我们蒸馏知识的效率很低——师傅带徒弟得三年,写教材得半年,知识传递的损耗很大。而现在,AI 把这个过程加速了几个数量级。一个大模型"教"一个小模型,用 80 万条数据,跑几天 GPU,就能把几百亿参数的推理能力"蒸"进去。
蒸馏不是什么新技术,2015 年就有了。但它终于走出实验室,进入了生产线——这才是它真正开始显出威力的时候。
总结
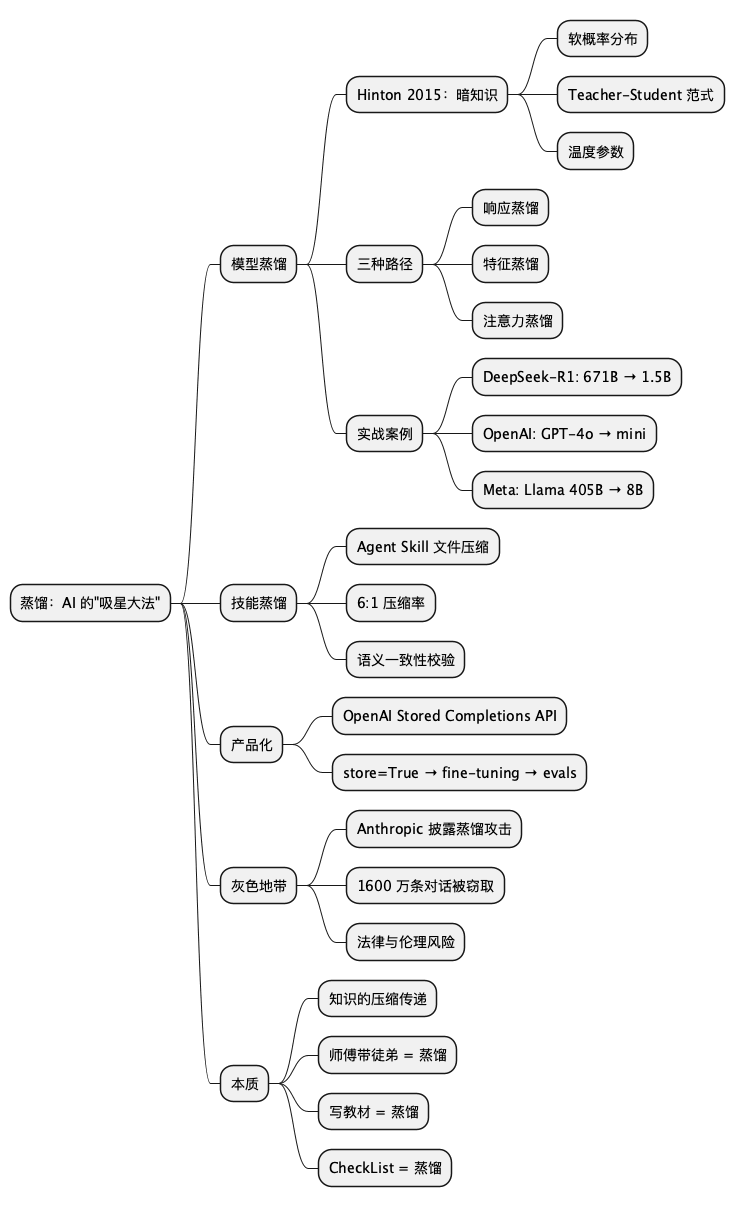
@startmindmap
* 蒸馏:AI 的"吸星大法"
** 模型蒸馏
*** Hinton 2015:暗知识
**** 软概率分布
**** Teacher-Student 范式
**** 温度参数
*** 三种路径
**** 响应蒸馏
**** 特征蒸馏
**** 注意力蒸馏
*** 实战案例
**** DeepSeek-R1: 671B → 1.5B
**** OpenAI: GPT-4o → mini
**** Meta: Llama 405B → 8B
** 技能蒸馏
*** Agent Skill 文件压缩
*** 6:1 压缩率
*** 语义一致性校验
** 产品化
*** OpenAI Stored Completions API
*** store=True → fine-tuning → evals
** 灰色地带
*** Anthropic 披露蒸馏攻击
*** 1600 万条对话被窃取
*** 法律与伦理风险
** 本质
*** 知识的压缩传递
*** 师傅带徒弟 = 蒸馏
*** 写教材 = 蒸馏
*** CheckList = 蒸馏
@endmindmap
5 件你明天就能做的事
- 给你的 API 调用加上
store=True:如果你在用 OpenAI,现在就开始攒数据,以后蒸馏时你会感谢自己。 - 审视一下你的 Agent Skill 文件有多胖:超过 1500 字的 Skill,认真考虑压缩一下。
- 试一次 DeepSeek-R1 的蒸馏模型:下载一个 R1-Distill-Qwen-7B,跑几个推理任务,亲身感受"小模型也能推理"。
- 检查你的模型服务条款:如果你在用别人的 API 输出来训练模型,确认一下这合不合规。
- 把你脑子里的经验写成 CheckList:这可能是最古老也最有效的"蒸馏"——把隐性知识变成显性知识。
一个开放式问题
蒸馏让小模型越来越能干,但也让"偷知识"越来越容易。如果有一天,任何大模型的能力都能被低成本蒸馏出来,那花几亿美元训大模型的公司,还有什么护城河?AI 产业的价值到底在训练能力,还是在数据壁垒?
参考链接
- Hinton et al. Distilling the Knowledge in a Neural Network (2015)
- DeepSeek-R1 蒸馏模型系列
- OpenAI Model Distillation in the API
- A Survey on Knowledge Distillation of Large Language Models
- Anthropic: Detecting and preventing distillation attacks
- skills-optimizer: 6:1 Skill 压缩工具
- Zylos Research: Model Distillation and Knowledge Transfer in AI 2026
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。