AI Agent 为什么会越用越懂你?从 OpenClaw 的“养龙虾”聊起
Posted on 三 01 4月 2026 in AI
| Abstract | AI Agent 为什么会越用越懂你?从 OpenClaw 的“养龙虾”聊起 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Version | v1.0 |
| Updated | 2026-04-01 |
| License | CC-BY-NC-ND 4.0 |
短大纲
- 从 OpenClaw 圈子里“养龙虾”的说法切入,先破一个迷思:多数 Agent 不是在偷偷训练自己
- 拆解 AI Agent 越用越顺手的 5 个机制:记忆、偏好画像、工作流沉淀、反馈回路、上下文工程
- 概念从 OpenClaw 来,代码拿更小巧的
nanobot来拆,聊聊MEMORY.md、会话历史、Dream consolidation 是怎么串起来的 - 说清楚“自我进化”和“系统层优化”的区别,避免把营销话术当技术事实
- 最后给一份“怎么把 Agent 真正养熟”的实操清单
2026-04-01
OpenClaw 圈子里有个挺形象的说法,叫“养龙虾”。
意思也不复杂:你刚把 Agent 装起来时,它像个刚来上班的实习生,热情很高,脑子也不算差,但总是差那口气。你让它写周报,它会写成官样文章;你让它查资料,它会把一堆不着边际的内容端上来;你让它帮你干活,它有时候像个积极但方向感不太好的外包同学。
可用一段时间之后,你会开始产生一种错觉:这玩意儿是不是偷偷进化了? 它越来越懂你的口味,知道你喜欢什么表达,知道你常用哪些工具,甚至知道什么时候该少说废话,什么时候该先去翻资料再回你。
这就是“养龙虾”这个说法最迷人的地方。它听起来像在养一只电子宠物,喂久了会长脑子。
但技术上要泼一盆冷水:多数 AI Agent 的“越用越聪明”,并不是底层大模型在你电脑里偷偷练成了九阳神功。 更常见的真相是,模型没怎么变,变的是它身上的外挂系统越来越全了,记忆越来越多了,工作流越来越顺了,和你之间的配合越来越默契了。
说白了,不是它突然开悟了,是你们俩磨合出来了。
为什么我选 nanobot 来拆,而不是直接看 OpenClaw
“养龙虾”的说法出自 OpenClaw 社区,但要理解它背后的工程原理,我不太建议直接翻 OpenClaw 的源码。
原因很现实:OpenClaw 仓库太庞大了。模块多、抽象层厚、插件体系复杂,很多人还没摸到记忆系统的门,先被目录结构劝退了。想搞清楚“它凭什么越来越懂我”,先得在代码里翻上大半天,学习成本有点高。
我后来找到一个更合适的切入点:nanobot。它在 README 里写得很直白——目标就是做一个 inspired by OpenClaw 的 ultra-lightweight 版本,用尽量少的代码保留核心 Agent 能力。代码量小,结构清晰,功能却没有打太多的折扣,拿来“拆发动机”正合适。
你可以把它想成 OpenClaw 的缩微模型,麻雀虽小,五脏俱全:
AgentLoop负责转主循环ContextBuilder负责拼 prompt 和上下文SessionManager负责会话历史MemoryStore负责长期记忆和归档Consolidator和Dream负责“消化旧对话,沉淀新记忆”
所以这篇文章的思路是:概念从 OpenClaw 来,拆解用 nanobot 做。 讲原理、讲体感的地方,两者相通;上代码、看实现的地方,我都拿 nanobot 举例,因为它小到你能一下午读完。
先把神话打掉:大多数 Agent 并没有在“边用边训练”
很多人一听“自我进化”,脑子里会自动脑补这样一幅画面:
我每聊一次 -> AI 学一点 -> 再聊十次 -> AI 变成我的分身
这画面很美,但多数时候并不真实。
对 OpenClaw、Cursor、Claude Code、Copilot 这一类 Agent 来说,通常有三层东西要分开看:
- 底层模型(Base Model)
- 运行时上下文(Runtime Context)
- 外部记忆与工具系统(Memory + Tools + Workflow)
真正昂贵、也最不可能在你本地会话里随手发生的,是第一层:改模型权重。那叫训练、微调、继续预训练,不是“聊着聊着就顺便做了”。
而我们平时感受到的“它越来越懂我”,大多来自后两层:
- 它记住了你的背景、偏好和历史任务
- 它能从以前的对话里检索到有用信息
- 它会根据你过去的选择,调整回答风格和执行顺序
- 它把常见任务慢慢沉淀成固定套路
所以,“养龙虾”这个比喻挺好,但更准确一点说,养的不是模型本体,而是 Agent 的外接大脑和行为习惯。
先看 nanobot 的主线,你就知道“进化”发生在哪儿
既然选了 nanobot 做解剖对象,先把它的主线捋成一句话:
收到消息 -> 取会话历史 -> 拼系统提示和记忆 -> 调 LLM -> 调工具 -> 保存结果 -> 后台整理记忆
这条链在代码里并不藏着掖着。
AgentLoop初始化时,把ContextBuilder、SessionManager、Consolidator、Dream和一堆工具都挂起来- 真正处理消息时,先从 session 里取历史,再交给
ContextBuilder.build_messages() ContextBuilder会把 identity、bootstrap files、长期记忆、skills summary 一起塞进 system prompt- 跑完一轮后,会话消息继续落到
SessionManager里 - 会话太长了,就交给
Consolidator按 token 预算归档 - 更“重”的长期整理,则交给定时跑的
Dream
你看,这里面没有哪一步叫“神秘自我进化”。全是工程动作。
但这些工程动作一旦连起来,用户体感上就会觉得:它越来越像个人了。
第一层:记忆系统,让它不再转头就忘
一个 Agent 想“越用越懂你”,第一件事不是能写多漂亮,而是别健忘。
这其实和人差不多。你愿意和一个每次见面都问你“你叫什么来着”的同事合作吗?再聪明也烦。
如果只讲概念,记忆系统很容易讲虚。拿 nanobot 来看就实在了:ContextBuilder 初始化时直接挂一个 MemoryStore,build_system_prompt() 把 memory 内容注入 system prompt。所谓“记住你”,说白了就是下次出场时把该带的记忆重新带上。
从存储结构看,它至少分了几层:
MEMORY.md:适合放比较稳定的长期事实和偏好history.jsonl:把历史对话或归档摘要按 append-only 方式记下来sessions/*.jsonl:当前会话的消息历史SOUL.md/USER.md:身份与用户画像一类的上层信息
这套设计的意义很直接:
- 短期记忆 解决“刚刚说过什么”
- 长期记忆 解决“你这个人平时是什么风格”
- 归档历史 解决“旧对话虽然不在眼前,但别白聊”
你可以把它理解成三个抽屉:
- 桌面上的便利贴
- 抽屉里的个人档案
- 文件柜里的历史项目记录
当 Agent 每次干活前,都能先翻一眼这些抽屉,它看起来就会“像认识你很久”。
这也是为什么一些用户会觉得 Agent 越用越顺。不是因为模型突然更聪明,而是因为下一轮对话时,它拿到的上下文比第一天多得多。
第二层:偏好画像,不是记住事实,而是记住“你怎么做事”
记忆事实,只能让 Agent 不至于失忆;想变成“你的风格”,还得多一层:偏好画像(preference profile)。
比如下面这些东西,严格说都不是知识,而是习惯:
- 你喜欢中文为主,必要时夹一点英文术语
- 你写文章喜欢先有 Hook,再进分析,再给 CheckList
- 你不喜欢太重的 AI 腔
- 你看重“能落地”,不爱听空话
- 你在 coding 场景下希望它先查上下文,再动手改代码
这些信息,书上学不到,网上也搜不到,但对“像不像你懂的那个助手”这件事,影响很大。
一个靠谱的 Agent,通常会通过几种方式慢慢拼出这张画像:
- 显式记录:你直接告诉它“以后写文章别太官话”“我偏好中文输出”
- 隐式观察:它看你经常接受什么答案,常常改掉什么措辞
- 长期归纳:它把很多次对话的共性,抽成少量稳定规则
这就像一个老同事慢慢摸清你的脾气:开会时你讨厌 PPT 废话,写方案时你喜欢先讲约束条件,Review 代码时你先看边界条件和失败路径。
很多人以为“更懂你”是智力提升,其实很多时候只是画像更准了。
第三层:工作流沉淀,真正厉害的不是会回答,而是会按你的路子干活
一个 Agent 真正“养熟”之后,最明显的变化往往不在措辞,而在做事顺序。
比如你让它做一件复杂任务,第一天它可能是这样的:
直接回答 -> 说一堆道理 -> 忘了查文件 -> 忘了验证 -> 你返工
用久以后,它可能会变成:
先确认目标 -> 查相关文件/历史记录 -> 拆步骤 -> 动手 -> 自检 -> 给结果
这一步的本质,不只是“记忆”,而是工作流被固化了。
在很多 Agent 系统里,这种固化可能来自:
- Skill / Plugin
- Tool calling 习惯
- 固定的 system instruction
- 任务模板
- 自动化脚本
- 你反复强化过的执行顺序
所谓“越养越聪明”,很可能是因为它慢慢把你高频重复的动作压缩成了一条更短的路径。
这和老司机开车很像。新手每一步都要想,老司机不是更会踩油门,而是很多动作已经程序化了。
Agent 也是一样。真正让它提速的,往往不是“想得更深”,而是“少走弯路”。
在 nanobot 里,这种“少走弯路”在代码里也看得到。AgentLoop 不只是把消息扔给模型,而是先把默认工具注册好,比如读写文件、目录搜索、shell、web、message、spawn,甚至还能挂 MCP。Agent 越用越像“会干活的人”,并不只是因为回答文字更像你,而是因为它越来越会按合适顺序调用这些能力。
第四层:反馈回路,用户每次皱眉,其实都在喂数据
很多 Agent 的成长,不靠你正式“训练”,靠的是你天天在那儿嫌弃它。
你说:
- “这个太长了,重写”
- “别上来先讲定义,先说结论”
- “这段太像 AI 写的”
- “先去读代码,再给建议”
这些看起来只是日常吐槽,但本质上都是反馈信号。
设计得好的 Agent,会把这些反馈变成后续行为的调整依据。不一定每次都显式写进记忆文件,但至少会在几个层面发生变化:
- 当前会话里即时修正
- 跨会话地沉淀成偏好
- 对某类任务启用更合适的模板
- 在调用工具前先补一步检查
这就是为什么你会感觉它“学会了”。它更像一个会复盘的助手:
动作 -> 结果 -> 你评价 -> 它修正下次动作
这个回路一旦建立,Agent 的表现就会越来越稳定。
稳定,很多时候比偶尔惊艳更值钱。
再往工程里看一步,这种“稳定”也离不开会话管理。nanobot 的 SessionManager 会把消息存在 sessions/*.jsonl,get_history() 还会刻意避免从半截 tool call 开始,尽量保证送进模型的上下文是“合法的一整段”。这类细节平时没人会拿来宣传,但它们直接影响你对 Agent 的观感: 不是更炫,而是更稳。
第五层:上下文工程,决定它每次出场时脑子里装了什么
前面几层加起来,还得有一个总调度,才能真正让 Agent 变得“像你的人”。
这个总调度,今天业内更常用的名字叫 Context Engineering。
它解决的不是“模型会不会推理”,而是:
- 这次任务开始前,要把哪些信息塞给模型?
- 哪些历史记忆相关,哪些其实是噪音?
- 是该读长期偏好,还是该查最近任务记录?
- 上下文不够时先检索,还是先问用户?
- 哪一步应该调工具,哪一步应该直接输出?
如果说底层模型像发动机,那上下文工程更像驾驶舱。发动机再好,导航乱指、仪表盘瞎报、刹车油门连错线,你照样得翻沟里。
这也是 OpenClaw、nanobot 这类 Agent 和纯聊天机器人最大的区别:它不是只凭“这一轮 prompt”活着,而是会在任务开始前,尽可能把该带的东西带上。
回到 nanobot 的代码,这件事看得更清楚:ContextBuilder.build_system_prompt() 先装 identity、bootstrap files、memory、skills summary;build_messages() 再把 runtime metadata、当前消息、媒体内容和历史消息拼在一起。所谓上下文工程,不是什么玄学名词,而是一套很具体的“装箱顺序”。
而在 OpenClaw 的公开生态里,还能看到不同 memory provider 的设计,比如本地记忆和外部记忆服务。社区里有 openclaw-supermemory 这类插件,会在每轮对话前自动 recall 相关记忆,对话后自动 capture 新信息。你体感上的“越来越懂我”,很多时候就是这种 auto-recall + auto-capture 在默默干活。
还有一个关键动作:它会“消化”,而不是只会“囤积”
很多人以为记忆系统就是不停往里塞内容。其实真这么干,Agent 迟早会被自己喂撑。
nanobot 里我觉得最值得借鉴的一点,是它把“记忆增长”分成了两种节奏:
- Consolidator:当上下文太长、快超过 token 预算时,把旧消息按安全边界切块,总结后归档到
history.jsonl - Dream:按定时任务跑一轮更重的整理,把历史分析后沉淀进长期文件,而不是让所有旧消息永远堆在 prompt 里
这就像人脑也不是把每句话都一字不差存着。白天先有短期记忆,晚上睡一觉,重要的留下,不重要的模糊掉。
所以“越用越懂你”的另一个前提,不只是能记,还得会忘、会压缩、会提炼。只囤不整,最后得到的不是智慧,是缓存爆炸。
所谓“自我进化”,更准确地说,是五个小回路同时转起来了
把前面几层合起来,你会发现,Agent 的“成长”并不是魔法,而是一套很朴素的工程组合拳:
- 记忆回路:把过去留下来
- 画像回路:把偏好抽出来
- 工作流回路:把高频动作固化下来
- 反馈回路:把你的评价变成下次修正
- 上下文回路:每次都把最该带的东西带上
这五个回路一旦协同,Agent 就会呈现出一种很像“成长”的效果。
这也是“养龙虾”最妙、也最容易被误解的地方。你看到的是它越来越像一个懂你的助手,容易以为它在“自己进化”;但工程上看,更像是:
它越来越会利用你们共同积累下来的环境了。
这和一个新同事转正很像。不是他 DNA 变了,而是他终于熟悉团队、文档、工具、暗规则和你老板的脾气了。
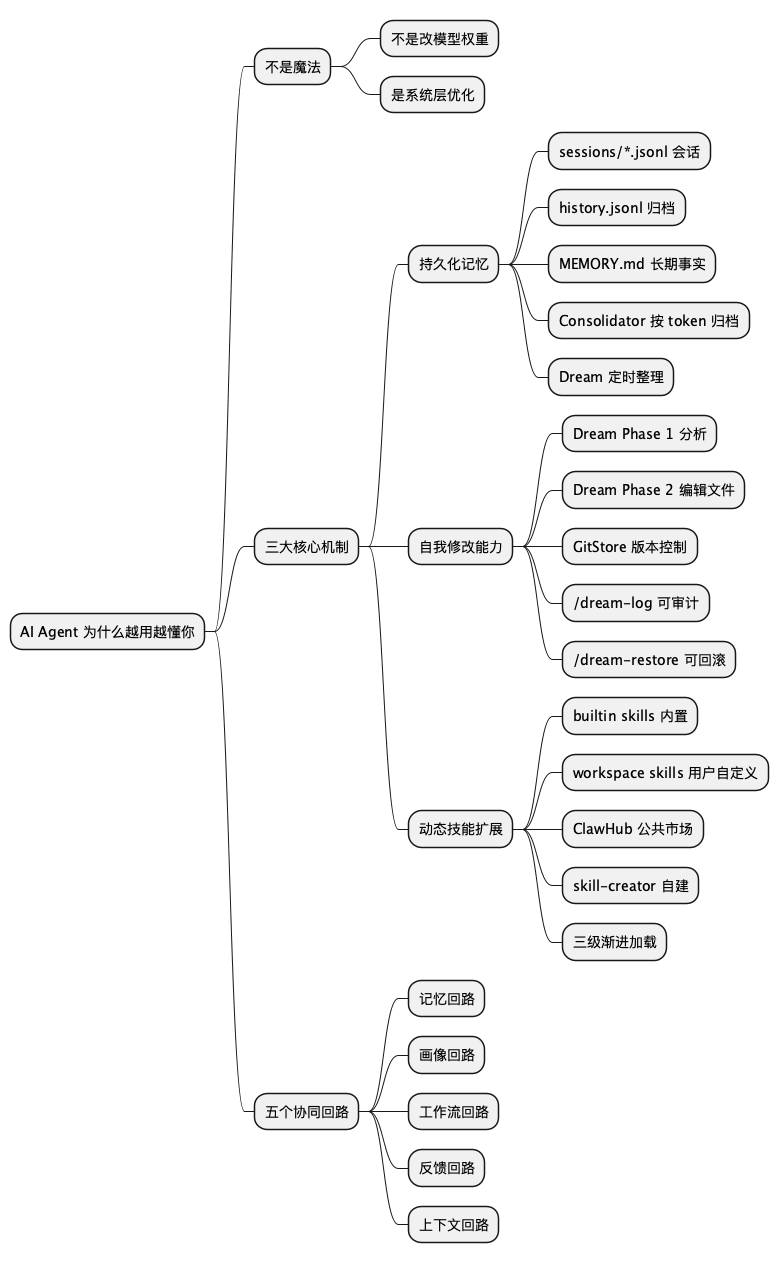
深入拆解:三个让 Agent "越养越像人"的核心机制
前面五层回路讲的是原理框架。但如果你想真正理解"养龙虾"为什么有效,有三个机制值得用代码级的细节来拆:持久化记忆、自我修改能力、动态技能扩展。
这三样搞明白了,"养龙虾"这件事的底层逻辑也就通了。
机制一:持久化记忆——不只是"存下来",而是"存对、存活、存得住"
一听"记忆",搞后端的同学条件反射就是 key-value 缓存。但 Agent 的记忆比缓存复杂得多——它不只是"存",还得"分层存、定期整理、过期清退"。
拿 nanobot 的 MemoryStore 来说,它管着至少四种不同节奏的持久化存储:
| 文件 | 角色 | 写入方式 | 生命周期 |
|---|---|---|---|
sessions/*.jsonl |
当前会话的完整消息记录 | 每轮对话自动追加 | 随会话存亡 |
memory/history.jsonl |
归档摘要(被 Consolidator 压缩过的旧对话) | append-only JSONL | 长期保留,定期 compact |
memory/MEMORY.md |
长期事实和知识(项目背景、重要事件) | Dream 自动编辑 | 持续更新 |
SOUL.md / USER.md |
Agent 人格 / 用户画像 | Dream 自动编辑 | 持续更新 |
这不是一张平面表,而是有"新陈代谢"的层级体系——短的进、长的留、过时的淘汰。
会话消息好比"生鲜食材",量大、时效性强、不能全塞进上下文窗口。当会话太长快超出 token 预算时,Consolidator 就该上场了:
# nanobot/agent/memory.py — Consolidator 的核心逻辑
async def maybe_consolidate_by_tokens(self, session: Session) -> None:
budget = self.context_window_tokens - self.max_completion_tokens - self._SAFETY_BUFFER
target = budget // 2
estimated, source = self.estimate_session_prompt_tokens(session)
if estimated < budget:
return # 还没超,不用动
# 找到安全的切割边界(必须在 user turn 之间切)
boundary = self.pick_consolidation_boundary(session, max(1, estimated - target))
chunk = session.messages[session.last_consolidated:end_idx]
# 调 LLM 把旧消息总结成摘要,追加到 history.jsonl
await self.archive(chunk)
session.last_consolidated = end_idx
注意几个细节:
- 不是随便切:
pick_consolidation_boundary()会找 user turn 边界,避免把一段完整的工具调用链拦腰砍断 - 切完不是丢了:旧消息被 LLM 总结后写入
history.jsonl,后续 Dream 还可以从中提炼长期事实 - 有兜底:如果 LLM 总结失败,还会走
raw_archive()把原始消息直接 dump 进去,宁可粗糙也不丢
然后是更重的 Dream。它是定时跑的(默认每 2 小时一次),干的事情更像"晚上睡觉时大脑整理白天的记忆":
- Phase 1:把
history.jsonl里的新条目和现有的MEMORY.md、SOUL.md、USER.md一起交给 LLM,让它分析有没有新信息需要沉淀 - Phase 2:如果有,就用
read_file+edit_file工具去定向修改那几个文件——不是整文件重写,而是增量编辑
Dream 跑完后还会用 GitStore 做一次 auto-commit——记忆的每次变更都有版本记录,/dream-log 能看、/dream-restore 能回滚。
这套设计妙在哪?你几乎不需要手动维护任何记忆文件。用着用着,Agent 自己把你的偏好、项目背景、常用模式慢慢"沉淀"到长期文件里。你不是在训练模型,你是在积累一个越来越丰富的外部记忆库,Agent 每次出场都会带上它。
机制二:自我修改能力——Agent 能改自己的"大脑"
这一点是很多人没意识到的:nanobot 的 Dream 不只是在"读"记忆文件,它实际上有权限写这些文件。
看 Dream 初始化时注册的工具:
# nanobot/agent/memory.py — Dream._build_tools()
def _build_tools(self) -> ToolRegistry:
from nanobot.agent.tools.filesystem import EditFileTool, ReadFileTool
tools = ToolRegistry()
workspace = self.store.workspace
tools.register(ReadFileTool(workspace=workspace, allowed_dir=workspace))
tools.register(EditFileTool(workspace=workspace, allowed_dir=workspace))
return tools
只给了两个工具:read_file 和 edit_file。但这就够了。
Phase 2 的指令模板(dream_phase2.md)写得很克制:
Update memory files based on the analysis below.
## Quality standards
- Every line must carry standalone value — no filler
- Concise bullet points under clear headers
- Remove outdated or contradicted information
## Editing
- Surgical edits only — never rewrite entire files
- Do NOT overwrite correct entries — only add, update, or remove
- If nothing to update, stop without calling tools
翻译成人话:Agent 在"睡觉"时,会审视自己对你的理解,用最小改动更新长期记忆。
比如你前几天一直用中文聊天,今天突然切英文。Dream 下次运行时,可能会在 USER.md 里加一条:
+ - Communicates in both Chinese and English; recently switched to English for technical discussions
或者你告诉它"以后别用 emoji",Dream 可能会在 SOUL.md 里更新:
- Communication style: friendly and casual
+ Communication style: friendly and casual; avoid emoji unless explicitly requested
安全网也有:GitStore 在每次 Dream 修改后自动 git commit,所有变更可追溯:
# nanobot/utils/gitstore.py
def auto_commit(self, message: str) -> str | None:
porcelain.add(str(self._workspace), paths=self._tracked_files)
sha_bytes = porcelain.commit(
str(self._workspace),
message=msg_bytes,
author=b"nanobot <nanobot@dream>",
committer=b"nanobot <nanobot@dream>",
)
用户随时可以跑 /dream-log 看 Dream 改了什么,跑 /dream-restore <sha> 回滚到任意历史版本。
这就是"自我修改"最有意思的地方:Agent 能改自己的"灵魂文件"和"用户画像",但改动透明、可审计、可回滚。 它不是在黑箱里偷偷变,更像一个会写工作日志的同事——你随时可以翻他的笔记本看他到底记了啥。
工程上这解决了一个很实际的问题:让用户手动维护 MEMORY.md、USER.md,大多数人坚持不了三天;让 Agent 自己来维护,又怕它改错。Dream + GitStore 的组合给了一个不错的平衡点:自动维护 + 人工兜底。
机制三:动态技能扩展——不是"什么都会",而是"需要时再学"
Agent "越来越能干"的第三个关键,是它的能力边界不是写死的。
nanobot 的技能系统分两层:
第一层:内置技能(builtin skills)
出厂就带的,比如 memory、github、weather、summarize、cron、clawhub 等。
第二层:工作区技能(workspace skills)
放在 ~/.nanobot/workspace/skills/ 下面的,用户或 Agent 自己都可以创建和安装。
SkillsLoader 的加载逻辑一看就懂:
# nanobot/agent/skills.py
def list_skills(self, filter_unavailable: bool = True) -> list[dict]:
skills = []
# 工作区技能优先级更高
if self.workspace_skills.exists():
for skill_dir in self.workspace_skills.iterdir():
if skill_dir.is_dir():
skill_file = skill_dir / "SKILL.md"
if skill_file.exists():
skills.append({"name": skill_dir.name, "path": str(skill_file), "source": "workspace"})
# 再加载内置技能(同名的不重复加)
if self.builtin_skills and self.builtin_skills.exists():
for skill_dir in self.builtin_skills.iterdir():
if skill_dir.is_dir():
skill_file = skill_dir / "SKILL.md"
if skill_file.exists() and not any(s["name"] == skill_dir.name for s in skills):
skills.append({"name": skill_dir.name, "path": str(skill_file), "source": "builtin"})
return skills
技能不是全量加载到上下文里的——那样 token 会爆。它用了一套三级渐进加载策略:
- 元数据(name + description):所有技能的摘要始终在上下文里(约 100 words 每个)
- SKILL.md 正文:只有当 Agent 判断任务需要这个技能时才读入
- 脚本和参考资料:只有在执行具体步骤时才按需加载
这和人类学技能很像:你知道"公司有个内部工具可以查日志"(元数据),需要时再去翻文档(SKILL.md),真要操作时再看详细步骤(scripts/references)。
更有意思的是 Agent 可以在运行时给自己装新技能。内置的 clawhub 技能就是干这个的:
# 搜索公共技能市场
npx --yes clawhub@latest search "web scraping" --limit 5
# 安装到工作区
npx --yes clawhub@latest install <slug> --workdir ~/.nanobot/workspace
你跟 Agent 说"帮我找个能刮网页的技能",它就去 ClawHub 搜、装、下次会话直接能用。
更进一步,Agent 还能自己创建技能。内置的 skill-creator 提供了完整的脚手架工具:
# 初始化一个新技能
scripts/init_skill.py my-skill --path ./workspace/skills --resources scripts,references
当你反复让 Agent 做同一类事情,聪明的做法是:把这个任务的 SOP 沉淀成一个 skill。下次它就不用从零理解你的意图,直接按 skill 里写好的步骤来。
这三个机制合在一起,就是"养龙虾"的完整闭环:
- 持久化记忆让它不健忘
- 自我修改能力让它越来越准确地理解你
- 动态技能扩展让它越来越能干
缺哪一个都差意思。光有记忆没有自我修改,存得越多越乱;光有自我修改没有技能扩展,"更懂你"但不会"更能干";光有技能扩展没有记忆,每次从零开始,装再多也白搭。
那怎么把 Agent 真正养熟?
如果你希望手里的 Agent 越用越顺,不妨别把它当成“神谕机”,而是把它当成一个可培养的协作对象。
下面这几条,往往比“换个更大的模型”更有效。
1. 明确写下稳定偏好
别指望它纯靠悟性猜。
把下面这些信息写进长期记忆或配置里:
- 你的角色和背景
- 常用语言和输出风格
- 不喜欢的表达方式
- 常用工具和环境
- 做事顺序上的硬偏好
2. 把高频任务做成模板
重复三次以上的事,就别每次从零解释。
比如:
- 周报模板
- 技术文章结构
- Code Review 清单
- Bug 排查 SOP
- 常用命令和目录约定
这比单纯“多聊几次”有效得多,因为你是在给它压缩路径。
3. 及时给纠偏反馈
别嫌麻烦。你今天的那句“别这么写”,很可能就是明天省下来的 10 分钟。
好的反馈最好具体:
- 不要只说“写得不好”
- 要说“哪里不好,为什么不好,改成什么更好”
4. 让它能访问真正有用的上下文
没有资料,AI 再聪明也只能猜。
能接入的尽量接入:
- 项目文档
- 历史任务记录
- 代码仓库
- 个人偏好说明
- 常用知识库
5. 定期“减肥”,别让记忆变成垃圾场
记忆不是越多越好,相关才重要。
如果长期记忆里塞满过时偏好、重复事实和临时噪音,Agent 只会越来越拧巴。该归档的归档,该删的删。
很多人只知道给 Agent 喂东西,不知道给它清肠胃。到后面它不是更聪明,是更油腻。
一个容易被忽略的现实:你养的,其实也是你自己的工作方法
我越来越觉得,AI Agent 最有意思的一点,不是它像人,而是它逼着你把自己的做事方式显性化。
以前很多习惯都在脑子里,是“只可意会,不可言传”的:
- 为什么你先看约束条件,再看方案
- 为什么你写文章喜欢先抛观点,再讲背景
- 为什么你做技术决策先看失败成本
当你想把一个 Agent 养熟时,你不得不把这些隐性习惯写出来、结构化、模板化、可复用化。
所以到最后,“养龙虾”这件事,其实有点像照镜子。
你以为你在训练它,结果很多时候,是它逼着你把自己也整理清楚了。
总结
如果只用一句话概括这篇文章,我的答案是:
AI Agent 的“自我进化”,大多数时候不是模型自己变强了,而是记忆、偏好、反馈、工具和上下文一起把它越养越像你。
这件事既没那么玄,也没那么容易。它不是一夜之间发生的,而是一轮轮使用、一点点纠偏、一层层沉淀的结果。
所以,与其问“这个 Agent 怎么会自己进化”,不如换个问法:
我有没有把它放进一个能持续积累经验、能持续接收反馈、能持续调用正确上下文的系统里?
问到这一步,你就已经比“它是不是成精了”更接近真相了。
@startmindmap
* AI Agent 为什么越用越懂你
** 不是魔法
*** 不是改模型权重
*** 是系统层优化
** 三大核心机制
*** 持久化记忆
**** sessions/*.jsonl 会话
**** history.jsonl 归档
**** MEMORY.md 长期事实
**** Consolidator 按 token 归档
**** Dream 定时整理
*** 自我修改能力
**** Dream Phase 1 分析
**** Dream Phase 2 编辑文件
**** GitStore 版本控制
**** /dream-log 可审计
**** /dream-restore 可回滚
*** 动态技能扩展
**** builtin skills 内置
**** workspace skills 用户自定义
**** ClawHub 公共市场
**** skill-creator 自建
**** 三级渐进加载
** 五个协同回路
*** 记忆回路
*** 画像回路
*** 工作流回路
*** 反馈回路
*** 上下文回路
@endmindmap
明天就能做的 5 件事
- 给你的 Agent 写一份 10 行以内的“用户偏好说明”。
- 把一个高频任务整理成固定模板,而不是每次临时吩咐。
- 连续一周给 Agent 更具体的反馈,不要只说“重写”。
- 给 Agent 接入一份真正常用的知识源,而不是让它空想。
- 清理一次长期记忆,把过时和重复的信息删掉。
一个开放式问题
当 Agent 越来越懂你,它到底是在帮你提高效率,还是也在悄悄固化你的思维惯性?如果它学会了你的优点,也学会了你的偏见,那这算进化,还是放大?
参考链接
- OpenClaw memory concepts
- OpenClaw Supermemory plugin
- Memory improvements: Give OpenClaw better memory + REM sleep
- nanobot 源码仓库
- nanobot DeepWiki 架构分析
- Prompt 工程已死,上下文工程当立
- AI Agent Loop 讲透:以一个会自己写博客的 Python Demo 为例
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。