AI 不只是 LLM 和 NLP
Posted on 一 11 5月 2026 in AI
| Abstract | AI 不只是 LLM 和 NLP |
|---|---|
| Authors | Walter Fan |
| Category | AI |
| Status | v1.0 |
| Updated | 2026-05-11 |
| License | CC-BY-NC-ND 4.0 |
AI 不只是 LLM 和 NLP
一、"AI" 已经被 LLM 劫持了
有一天我在公司内部群看到一条消息,大意是:"我们要在 Q3 上线 AI 功能,谁来负责?"
群里迅速有人回应:"我来!我用过 ChatGPT,也调过 Claude 的 API。"
我盯着这条消息看了几秒。没有人觉得哪里不对劲。
但我觉得不对劲。不是说那个同学能力不行——LLM API 调用确实是落地"AI 功能"的主流路径之一。问题是:那条消息里的"AI",在大多数人脑袋里,已经默默地等号变成了 LLM。
这个置换是什么时候发生的?
大概是 GPT-3 之后,特别是 ChatGPT 横空出世的那个冬天。LLM 以一种极其直观、门槛极低的方式,让普通人第一次真正"摸到"了 AI。这是好事。但它带来了一个副作用:让人觉得 AI = 大语言模型 = 文字接龙的高级版。
这种认知偏差不是小事。它会导致你在解决问题时,把所有钉子都当成能用 LLM 这把锤子敲的样子,然后很困惑地发现:有些钉子根本敲不进去。
二、AI 的全景图:比你想象的大得多
先来看一张真实的地图。
人工智能作为一个研究领域,从 1950 年代就开始了。几十年下来,沉淀出的子领域大概长这样:
人工智能 (AI)
├── 机器学习 (Machine Learning)
│ ├── 监督学习 (Supervised Learning)
│ ├── 无监督学习 (Unsupervised Learning)
│ ├── 半监督学习 (Semi-supervised Learning)
│ └── 强化学习 (Reinforcement Learning)
├── 深度学习 (Deep Learning)
│ ├── 卷积神经网络 CNN (计算机视觉)
│ ├── 循环神经网络 RNN / Transformer (序列建模)
│ └── 生成对抗网络 GAN / Diffusion (生成式)
├── 自然语言处理 (NLP)
│ ├── 传统 NLP (规则/统计方法)
│ └── 大语言模型 LLM (当前主流)
├── 计算机视觉 (Computer Vision)
│ ├── 图像分类 / 目标检测
│ ├── 图像分割
│ └── 多模态视觉语言
├── 推荐系统 (Recommendation System)
├── 知识图谱 (Knowledge Graph)
├── 机器人与自动化 (Robotics)
├── 自动驾驶 (Autonomous Driving)
├── 语音识别与合成 (Speech)
└── AI 安全 / 可解释 AI (AI Safety / XAI)
LLM 在哪里?在 NLP 分支下面,再往下一级。
它很重要,但它不是全部。
三、那些你每天在用、却不知道是"AI"的东西
讲个实际的场景:你上午在某电商平台逛了十分钟,下午刷微博或 X 的时候,商品广告精准得让你怀疑手机在偷听。那背后是 LLM 吗?不是。
是协同过滤 + 深度学习排序模型 + 实时特征工程组成的推荐系统。这套东西跑了将近二十年,跟 LLM 几乎没有关系。
再比如:
- 你用人脸解锁手机——人脸识别是计算机视觉,卷积神经网络(CNN)做的。
- 你发语音消息,微信帮你转成文字——语音识别(ASR),端到端序列模型。
- 工厂流水线上检测零件瑕疵——工业视觉检测,在生产线上 24 小时实时跑,LLM 根本插不上手。
- AlphaGo 打败柯洁——强化学习(Reinforcement Learning),跟文本处理毫无关系。
- 特斯拉的自动泊车——感知、规划、控制的协同,多个模型和算法的流水线。
- 银行的反欺诈系统——异常检测、图神经网络(Graph Neural Network),实时判断一笔交易是否可疑。
这些东西日复一日地在运作,影响着数十亿人的生活,但几乎没有人会用"AI"这个词来描述它们——因为它们"不会说话",没有聊天界面,不够炫。
四、为什么 LLM 抢走了所有聚光灯?
这不难理解。有几个客观原因:
1. 交互门槛极低。 你不需要懂机器学习,只要会打字,就能和 GPT-4 对话。历史上从未有过这样的 AI——不需要学习成本,直接能"用"。
2. 泛化能力让人叹为观止。 以前的 AI 都是"窄 AI":下棋的只能下棋,识图的只会识图。LLM 第一次表现出跨任务的通用能力——翻译、写代码、写诗、分析合同……同一个模型。这在概念上是划时代的。
3. 媒体需要一个简单的叙事。 "会说话的 AI"比"更精准的点击率预测模型"好写、好传播、好炒作。推荐算法你怎么拍?拍不出来。ChatGPT 你截个屏就能发朋友圈。
4. 创业公司和投资人需要新的故事。 LLM 给了整个行业一个集体狂欢的理由。这没什么可批评的,只是需要清醒地知道,聚光灯下的那部分,不等于全局。
五、工程师容易掉进的陷阱
做工程的人,如果被"AI = LLM"的认知框住了,会出现几个典型的判断失误:
陷阱一:所有 AI 需求都往 LLM 上套。
一家物流公司想做包裹破损识别,你给他们设计了一套"上传图片 → 发给 GPT-4V → 让它描述是否破损"的方案。LLM 视觉能力确实不弱,但你忽略了:他们有 50 万张历史标注图片,一个微调过的轻量 CNN 推理成本是 LLM API 的 1/100,而且延迟在毫秒级。LLM 是把好刀,但这里用不上。
陷阱二:低估传统 ML 的成熟度。
机器学习领域很多问题,用 XGBoost、LightGBM 这类梯度提升树,在结构化数据上跑出来的效果,经常碾压硬塞进去的 LLM 方案。银行风控、用户流失预测、CTR 预估——这些场景 LLM 既不是最优解,也往往不是最经济的解。
陷阱三:以为调 API 就等于"做 AI"。
调用 OpenAI 的 API 是工程能力的一部分,但不是 AI 能力的全部。你知道 Token 是什么,但你了解 Embedding 空间吗?你会写 Prompt,但你知道为什么 RAG(检索增强生成)比直接塞上下文更靠谱吗?你能接入 LLM,但当模型幻觉出一个假答案,你有能力在系统层做后置过滤吗?
这些问题,深挖下去,都会碰到 ML 基础知识,碰到向量数据库的工作原理,碰到模型评估方法……而这些,跟 LLM 调参只是重叠,不是等同。
六、LLM 真正的位置:工具箱里的一把锤子
说了这么多,我并不是要给 LLM 泼冷水。正好相反——它确实是近年来最重要的工具进化之一。
但"最重要"不等于"唯一"。
一个工程师的 AI 工具箱,应该长这个样子:
| 场景 | 推荐工具 |
|---|---|
| 文本生成、理解、摘要 | LLM(GPT/Claude/开源模型) |
| 图像分类 / 目标检测 | CV 模型(YOLO, ResNet, ViT) |
| 个性化推荐 | 协同过滤、深度排序模型 |
| 结构化数据预测 | XGBoost, LightGBM, 线性模型 |
| 游戏 / 机器人控制 | 强化学习(PPO, SAC) |
| 时序预测 | LSTM, Transformer-based 时序模型 |
| 异常检测 | 孤立森林、自编码器 |
| 知识推理 | 知识图谱 + 图神经网络 |
| 语音识别 | Whisper 及类似 ASR 模型 |
用什么工具,取决于你的问题是什么,而不是哪个工具最新、最热、媒体提及频率最高。
我见过一个真实案例:一个团队花了三个月用 LLM 做故障根因分析,最后上线效果勉强及格,且延迟高、成本贵。后来换成了基于日志特征工程 + 决策树的方案,两周搞定,准确率反而更高。他们当初的问题不是技术不够好,是一开始就带着"答案"去找"问题"——AI 问题解法里,这是很常见的路径依赖。
七、如何建立更完整的 AI 认知框架
我自己是怎么做的?粗暴地说,就是:从问题出发,不从工具出发。
每次接到一个 AI 相关的需求,我习惯先问自己三个问题:
- 数据是什么形态的? 文本、图像、表格、序列、图结构……数据决定工具类别。
- 目标是什么? 分类、回归、生成、推荐、决策……目标决定算法思路。
- 约束是什么? 实时性要求、成本限制、可解释性要求、训练数据量……约束决定最终落地方案。
把这三个问题回答清楚之后,再去选工具。大多数时候,LLM 不是第一个跳出来的答案。
另外,建议每个做 AI 工程的人,哪怕你现在主要搞 LLM 应用,也值得花时间补一补下面几块:
- ML 基础:线性代数、概率论、优化算法——不是让你手推梯度,是要理解为什么模型会出现你观察到的行为。
- 计算机视觉入门:看懂一个 CNN 的结构,知道 YOLO 在做什么。多模态是趋势,视觉和语言迟早要打通。
- 推荐系统原理:互联网产品里这是最常见的 AI 场景之一,理解协同过滤和特征交叉,会让你和产品的对话质量高一个档次。
- 强化学习概念:RLHF(人类反馈强化学习)是 LLM 对齐的核心技术之一,不了解 RL,很多关于大模型的讨论你只能听个皮毛。
八、行动清单
- [ ] 下次看到"AI 项目"需求,先问三个问题:数据形态、目标类型、约束条件,再决定用什么工具
- [ ] 找一门计算机视觉的入门课(推荐斯坦福 CS231n),了解 CNN 是怎么工作的
- [ ] 了解一个你日常接触的推荐系统(抖音、淘宝、Netflix)背后大概用了什么技术路线
- [ ] 读一下 RLHF 的原始论文(InstructGPT),理解为什么 ChatGPT 比 GPT-3 "好说话"
- [ ] 用 scikit-learn 训练一个简单的分类器,感受一下监督学习的完整流程(不要跳过这一步)
- [ ] 整理一张属于你自己项目领域的"AI 工具地图",标注哪些是 LLM 适合做的,哪些不适合
九、总结
AI 不等于 LLM,LLM 也不等于 NLP,NLP 只是 AI 生态里的一个分支,尽管现在是最耀眼的那个。
认知边界的狭窄,会直接影响解决问题的质量。当你的工具箱里只有一把锤子,所有问题看起来都像钉子。
更好的状态是:你知道工具箱里有哪些东西,每件工具适合什么场景,也知道自己在哪个工具上最拿手——然后在合适的时候,拿出合适的那把。
LLM 是目前最性感的那把锤子,没错。但别忘了,性感和正确,有时候不是同一件事。
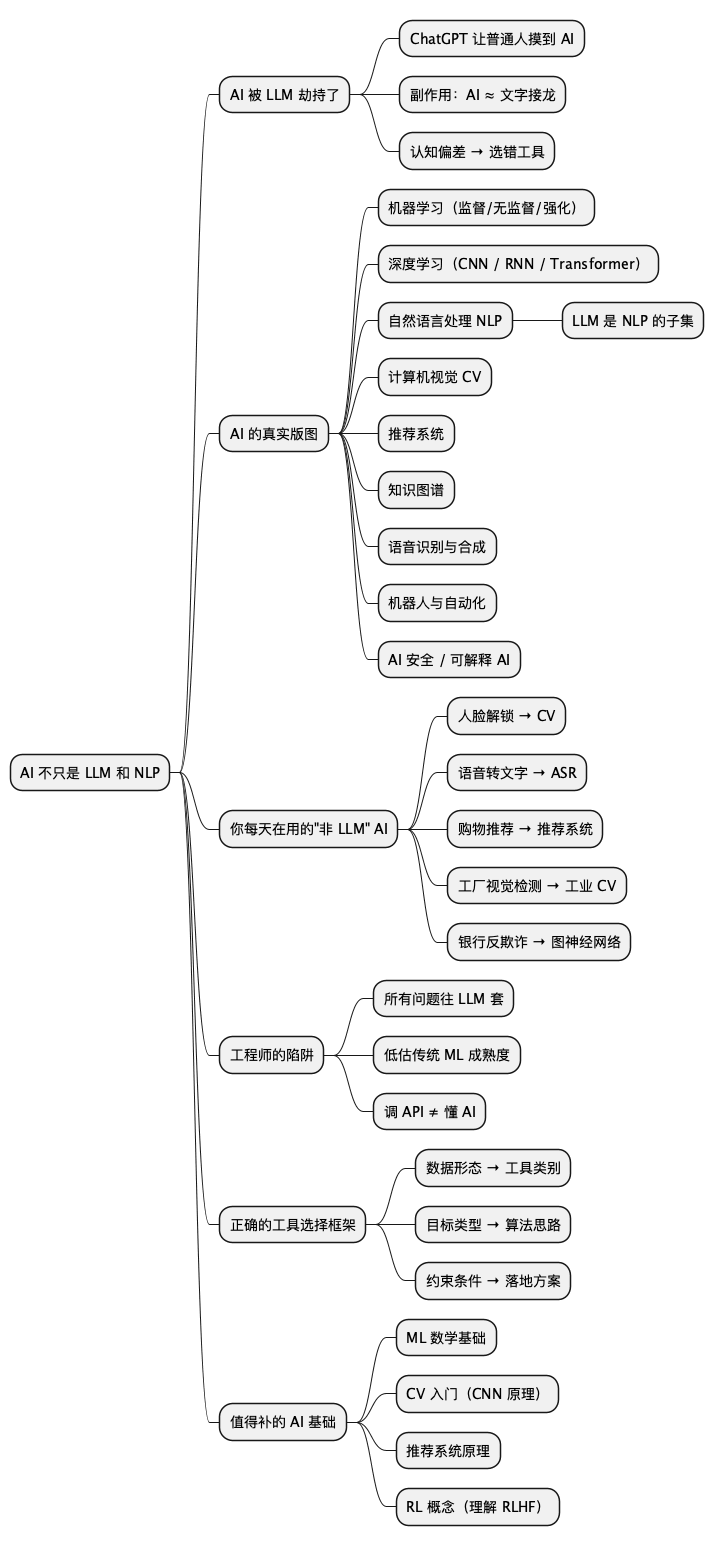
下面是这篇文章的骨架总结:
@startmindmap
* AI 不只是 LLM 和 NLP
** AI 被 LLM 劫持了
*** ChatGPT 让普通人摸到 AI
*** 副作用:AI ≈ 文字接龙
*** 认知偏差 → 选错工具
** AI 的真实版图
*** 机器学习(监督/无监督/强化)
*** 深度学习(CNN / RNN / Transformer)
*** 自然语言处理 NLP
**** LLM 是 NLP 的子集
*** 计算机视觉 CV
*** 推荐系统
*** 知识图谱
*** 语音识别与合成
*** 机器人与自动化
*** AI 安全 / 可解释 AI
** 你每天在用的"非 LLM" AI
*** 人脸解锁 → CV
*** 语音转文字 → ASR
*** 购物推荐 → 推荐系统
*** 工厂视觉检测 → 工业 CV
*** 银行反欺诈 → 图神经网络
** 工程师的陷阱
*** 所有问题往 LLM 套
*** 低估传统 ML 成熟度
*** 调 API ≠ 懂 AI
** 正确的工具选择框架
*** 数据形态 → 工具类别
*** 目标类型 → 算法思路
*** 约束条件 → 落地方案
** 值得补的 AI 基础
*** ML 数学基础
*** CV 入门(CNN 原理)
*** 推荐系统原理
*** RL 概念(理解 RLHF)
@endmindmap
十、扩展阅读
- Stanford CS231n: Convolutional Neural Networks for Visual Recognition — 计算机视觉入门最经典的课
- Andrej Karpathy: Software 2.0 — 理解 ML 范式转变的好文
- InstructGPT 论文:Training language models to follow instructions — RLHF 的原始文献
- Recommender Systems Handbook — 推荐系统全景参考
- 《统计学习方法》—— 李航(ML 基础,中文教材里的良心之作)
- Lilian Weng's Blog — 深度学习各个方向的系统综述,质量极高
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。