AI Agent Loop 讲透:以一个会自己写博客的 Python Demo 为例
Posted on 四 19 3月 2026 in Journal
| Abstract | AI Agent Loop 讲透:以一个会自己写博客的 Python Demo 为例 |
|---|---|
| Authors | Walter Fan |
| Category | learning note |
| Status | v1.0 |
| Updated | 2026-03-31 |
| License | CC-BY-NC-ND 4.0 |
这回我不是让 AI 回答问题,我是让它自己去干活
前几天我做了个小实验,用 lazy-rabbit-agent 目录里的 agent_loop_demo.py,直接给它下了这么一条命令:
python agent_loop_demo.py --task "please write a blog in chinese to introduce ai agent loop, use agent_loop_demo.py as example, explain how does an ai agent work, please write the markdown file into current folder, the markdown file gent_loop_demo.md should contain a mindmap script (plantuml) to summarize the blog"
结果它还真就在当前目录里写出了一个 agent_loop_demo.md。
这件事挺有意思。因为从用户视角看,你只说了一句话;可从程序视角看,这已经不是普通的“一问一答”了。它得先理解任务,再判断要不要看文件,要不要列目录,要不要写文件,写完之后还得确认结果在不在,最后才能宣布“活干完了”。
这中间那台不停运转的小机器,就是 Agent Loop。
很多文章一说 Agent,就容易把话说得玄乎,仿佛它突然有了自主意识。其实没那么神。大多数 Agent Loop,本质上就是一套受控的循环:
理解任务 → 生成动作 → 调工具 → 看结果 → 更新上下文 → 再决定下一步
说白了,它像一个肯动手的实习生,但这个实习生有几个特点:
- 脑子是 LLM
- 手脚是工具
- 短期记忆和长期记忆负责“别转头就忘”
- 规则系统负责“别把家里煤气点着”
这篇文章我不打算讲泛泛而谈的概念。我想就着这个真实脚本,把 AI Agent Loop 从头拆到尾,看看一个 Agent 到底是怎么转起来的,它为什么能写文件,为什么会犯傻,又为什么必须被管起来。
先把底牌翻开:Agent 不是“会思考的聊天框”,而是“带工具的循环体”
普通 LLM 调用,大多是这样:
用户输入 → 模型生成 → 返回答案
这像你问路,别人给你指个方向。说完就完了。
Agent 不一样。Agent 的活儿不是“回答”,而是“完成任务”。只要任务没有完成,它就不能停在第一轮。
比如这次我的任务不是“解释一下 Agent Loop”,而是:
- 用中文写博客
- 以
agent_loop_demo.py为例 - 写入当前目录
- 文件名叫
gent_loop_demo.md - 里面还得带 PlantUML 思维导图
这不是一句话能直接吐干净的。它得拆。
所以 Agent Loop 的第一原则不是“回答得漂亮”,而是:
先判断下一步该做什么。
这就引出了一个关键点:Agent 的核心,不是模型本身,而是这个循环。
模型只负责出主意。真正把主意变成结果的,是 Loop。
用这支 demo 来看,Agent Loop 其实就是一台小发动机
agent_loop_demo.py 这个脚本并不大,但骨架很完整。它里面最关键的几块,我给它翻译成人话,大概是这样:
| 组件 | 作用 | 类比 |
|---|---|---|
LLMClient |
负责向模型发问 | 大脑接口 |
AgentTools |
负责列目录、读文件、写文件、追加文件、取时间 | 手脚 |
ShortTermMemory |
保存最近几轮对话和工具结果 | 工作台上的便签纸 |
LongTermMemory |
持久化记忆,跨运行保留一些东西 | 抽屉里的笔记本 |
Action |
模型每轮做出的决策 | 工单 |
AgentLoopDemo.run_task() |
整个循环的总调度 | 发动机曲轴 |
你看这几个名字,已经把味道说明白了:它不是一个“大而全的框架”,而是一台最小可运行的 Agent。
目的无他,就是证明一件事:
Agent Loop 不一定非得很复杂,关键是闭环要完整。
这条命令真正发生了什么
咱们先别急着看代码,先从运行过程倒推。
当我把那条 --task 命令扔给脚本之后,程序大致经历了下面这几步:
- 把用户任务记下来
- 先让模型做一个简短计划
- 把系统提示词、工作区路径、短期记忆、长期记忆、计划一起打包成 prompt
- 调 LLM,请它返回一个 严格 JSON 动作
- 如果动作是
tool,就执行工具 - 把工具结果塞回上下文
- 再问模型下一步
- 如果模型返回
final,还要检查目标文件是否真的写出来了
注意,这里最重要的一点是:
模型不是直接生成最终博客,而是在多轮里一步一步把事情做完。
这和普通 Prompt 的差别,就像“动嘴指挥”和“自己下场搬砖”的差别。
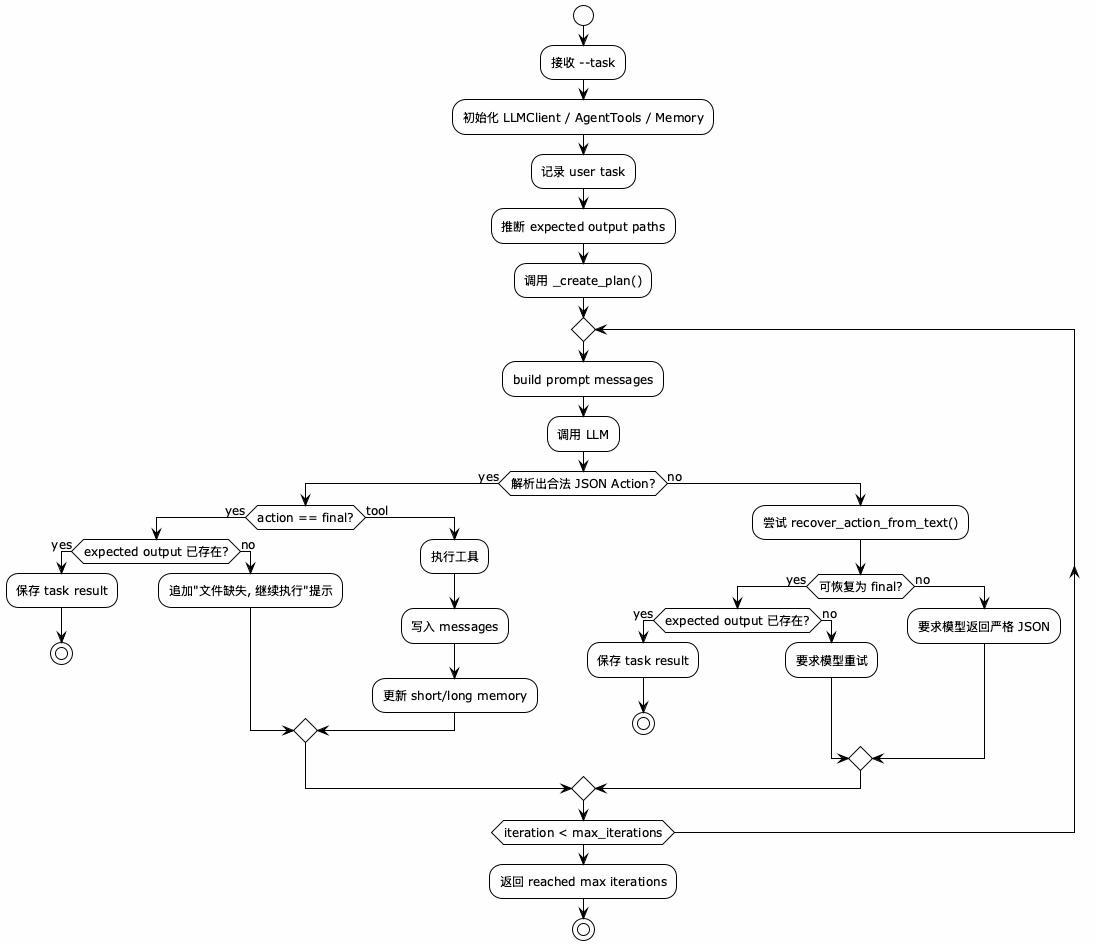
如果把 agent_loop_demo.py 的主循环抽成一张 UML 活动图,大概就是这个样子:
@startuml
!theme plain
skinparam backgroundColor #FEFEFE
skinparam activityFontSize 13
skinparam defaultFontSize 12
start
:接收 --task;
:初始化 LLMClient / AgentTools / Memory;
:记录 user task;
:推断 expected output paths;
:调用 _create_plan();
repeat
:build prompt messages;
:调用 LLM;
if (解析出合法 JSON Action?) then (yes)
if (action == final?) then (yes)
if (expected output 已存在?) then (yes)
:保存 task result;
stop
else (no)
:追加"文件缺失, 继续执行"提示;
endif
else (tool)
:执行工具;
:写入 messages;
:更新 short/long memory;
endif
else (no)
:尝试 recover_action_from_text();
if (可恢复为 final?) then (yes)
if (expected output 已存在?) then (yes)
:保存 task result;
stop
else (no)
:要求模型重试;
endif
else (no)
:要求模型返回严格 JSON;
endif
endif
repeat while (iteration < max_iterations)
:返回 reached max iterations;
stop
@enduml
Agent Loop 的第一层:先做计划,但计划不是圣旨
这个 demo 里有一个挺有意思的小细节:它不是一上来就让主循环瞎跑,而是先调用 _create_plan()。
计划提示词也很朴素,大意是:
- 任务是什么
- 预期输出文件是什么
- 请给我 3 到 8 条简短执行步骤
- 重点写工具使用和验证步骤
这件事看起来像“多此一举”,其实很值。
因为 LLM 直接干活时,最常见的问题不是不会写,而是容易乱:
- 该先读文件的时候直接写
- 该验证输出的时候提前宣布完成
- 写长文件时一口气塞太多,导致工具 payload 爆掉
先做计划,相当于先在脑子里打一个草稿。当然,这个计划不是编排器自己能理解的 AST,也不是任务图引擎里的 DAG,它只是普通文本。可就算只是普通文本,也足够给后面几轮推理“定个调”。
换句话说,这个计划更像开工前在白板上写下的几行字,不是法律条文,但能让人别一上来就跑偏。
第二层:系统提示词才是“规矩”,不是装饰
这个 demo 的 SYSTEM_PROMPT 写得很实在,我挺喜欢这种风格。它没有摆一堆“你是世界上最聪明的 AI 助手”这种排场,而是直接讲规矩:
- 有哪些工具可用
- 路径必须相对工作区
- 写博客任务要把完整 markdown 写到目标文件
- 长内容不要一次性全写,要
write_file+ 多次append_file - 回答必须是严格 JSON
- 不要在 JSON 前后废话
这段提示词,其实就是 Agent Loop 的“交通法规”。
很多人刚做 Agent 时,容易把注意力全放在模型上,比如选 GPT 还是 Claude,温度调多少。固然模型重要,可真正决定系统是否稳定的,往往是这些硬邦邦的约束。
因为模型最大的毛病,不是不聪明,而是太爱自由发挥。
不给规矩,它就会:
- 在 JSON 外头多说两句解释
- 工具参数名写错
- 明明该分块写文件,却一口气吐几万字
- 文件还没写成功,就抢着说“任务完成”
所以做 Agent,提示词不是文案,是协议。
第三层:Action 是整个系统的“指令集”
这个 demo 把 LLM 的输出收束成两种动作:
{"action":"tool","tool_name":"read_file","tool_args":{"path":"input.md"}}
或者:
{"action":"final","final_text":"Completed. Wrote output to gent_loop_demo.md"}
你可以把它理解成一个极简版 CPU 指令集。它不让模型天马行空地输出任意格式,而是只许干两件事:
- 要么调工具
- 要么宣布完成
这一步特别关键。
因为只要动作空间收窄了,系统的可控性就会大幅提升。模型再聪明,也得按这个门进,按那个门出。
这也是很多 Agent 走向工程化的分水岭:
- Demo 阶段:模型说啥都行
- 工程阶段:模型只能在一个有限动作集合里活动
无他,动作越有限,系统越可测,越能 debug,越能兜底。
第四层:工具不是“外挂”,工具就是 Agent 的四肢
在这支 demo 里,工具很少,只有五个:
list_dirread_filewrite_fileappend_fileget_current_datetime
看上去朴素得很,可这正好说明问题。
一个 Agent 能不能干活,不在于它能背多少术语,而在于它能不能碰到环境、改变环境。
没有工具的 Agent,像个只会纸上谈兵的谋士。能分析半天,真要写个文件,还是得你自己来。
这也是为什么我说 Agent 和聊天机器人不是一回事。聊天机器人负责“解释”;Agent 负责“落地”。
工具设计里最容易被忽略的,是边界
AgentTools 里有个 _safe_path(),这段代码看着不花哨,实际非常要命:
def _safe_path(self, raw_path: str) -> Path:
candidate = (self.workspace / raw_path).resolve()
if not str(candidate).startswith(str(self.workspace)):
raise ValueError(
f"Path escapes workspace: {raw_path!r}. Workspace={self.workspace}"
)
return candidate
这是什么意思?
就是说,无论模型多有创意,它都不能借着 ../../ 这种路径越狱,跑去读你工作区外头的文件。
这就是 Agent 工程里一个很现实的真相:
工具能力越强,边界就越要硬。
否则你辛辛苦苦做出来的,不是助手,是内鬼。
第五层:短期记忆和长期记忆,不是锦上添花,而是防止失忆
这个脚本里有两套 memory:
1. ShortTermMemory
短期记忆像工作台上的便签,存最近几轮:
- 用户任务
- 模型刚才做了什么决定
- 工具返回了什么观察结果
它是滚动窗口,有上限,旧的会被裁掉。原因也简单:上下文不是无限的,模型窗口再大也不能拿它当垃圾场。
2. LongTermMemory
长期记忆存在 memory/long_term_memory.json 里,会跨运行保留一些条目,比如:
- 上次写过哪些文件
- 某个任务最后结果是什么
- 某些常见内容片段
它的 recall() 不是向量检索,也不是什么 fancy 的 RAG,就只是一个基于词匹配的简单召回。可这反而挺说明问题:
Agent 不一定非得一上来就上最重的架构。很多时候,一个简单能用的 recall,已经能解决“完全失忆”这个问题。
咱们做系统,最怕的不是不高级,最怕的是还没站稳就想飞。
第六层:真正的 Loop 在 run_task() 里
这支 demo 的灵魂,在 AgentLoopDemo.run_task()。
把细节折叠掉之后,它大概就是这么个意思:
for iteration in range(self.max_iterations):
llm_messages = self._build_llm_messages()
raw = self.llm.complete_with_options(llm_messages)
payload = extract_json_object(raw)
action = self._normalize_action(payload)
if action.kind == "final":
校验输出文件是否真的存在
return final_text
result = self._execute_tool(action.tool_name, action.tool_args)
self.messages.append(tool_result)
self.short_memory.add(...)
看着很像 while-loop,对吧?是的,本质上就是。
可它不是死循环,而是一个带边界、带反馈、带失败恢复的循环。
Agent Loop 的味道,全在这里:
- 不是一次调用
- 不是固定流程
- 是“看结果再决定下一步”
这点像写程序时的 REPL,也像老师傅修机器:先看症状,再拧一刀,再听动静,再判断要不要继续拆。
第七层:为什么工具结果还要再喂回模型
很多初学者会有个疑问:工具执行完了,程序自己不是已经知道结果了吗,为什么还要把结果写回 self.messages 和 memory 里,再喂给模型?
因为模型不会自动读你的 Python 变量。
它只能看到你放进上下文里的文本。
在这个 demo 里,工具执行后会塞回一条类似这样的观察:
Tool result from the previous step.
Tool: read_file
Observation:
... 文件内容 ...
这一步很关键。没有 observation 回流,Loop 就断了。
你可以把整个 Agent Loop 理解成一个不断追加“外部世界观察”的认知链:
任务 → 行动 → 观察 → 新上下文 → 新行动
如果没有“观察”这一步,Agent 就会像闭着眼睛修表,一直拧,一直拧,直到把螺丝拧飞。
第八层:真正像工程系统的地方,在失败恢复
这份 demo 我觉得最有价值的,不是能写博客,而是它已经开始认真对待“模型不听话”这件事。
1. 模型不返回合法 JSON,怎么办
现实里的模型,经常会犯这种毛病:
- 外面套一层 markdown fence
- 连着吐两个 JSON
- 先说一段废话,再给 JSON
- 甚至直接输出
TOOL_RESULT::write_file
所以脚本里做了两层兜底:
extract_json_object(raw)先尽量从混乱输出里捞 JSONrecover_action_from_text(raw, workspace)再做一次 best-effort 恢复
这就很像生产系统里的容错解析器。因为你不能把希望全压在“模型这次一定听话”上。
2. 模型说完成了,但文件其实没写出来,怎么办
这个 demo 更狠的一点,是它不相信模型的嘴。
如果任务里推断出了预期输出文件,比如 gent_loop_demo.md,那么模型就算返回:
{"action":"final","final_text":"done"}
程序也不会立刻信。它会先去工作区里检查这个文件是否真的存在。
这个设计我很喜欢。因为它把“完成”的定义,从语言层,拉回到了事实层。
说得再漂亮,文件没落地,就是没做完。
这也是 Agent 系统和普通聊天系统最重要的一条分界线:
聊天系统以措辞为准,Agent 系统以外部世界状态为准。
3. 为什么要有 max_iterations
再聪明的模型,也会偶尔钻牛角尖。
比如:
- 一直重复
list_dir - 文件已经在了,还反复
read_file - 写了一半后忘了收尾
所以 max_iterations 本质上是保险丝。它防止 Loop 因为模型幻觉变成永动机。
很多人第一次做 Agent,总想追求“让它一直跑到成功”。可一个能停下来的系统,往往比一个号称永不停止的系统更成熟。
把这次“自动写博客”任务拆给你看
回到这次实验。这个任务能成功,大概依赖下面这条链:
第一段:模型先理解任务的约束
它得知道:
- 这是写博客,不是回答一段话
- 输出要落地成 markdown 文件
- 文件必须写到当前目录
- 还得包含 PlantUML mindmap
第二段:模型决定先不急着 final
只要它脑子还清楚,就不会第一轮就说“已完成”,而是先走工具:
- 也许先
list_dir - 也许直接
write_file(gent_loop_demo.md, first_chunk) - 然后多次
append_file
第三段:工具把文本真正写到磁盘
这个动作很重要,因为“博客存在于文件系统里”这件事,只有工具能完成,模型自己做不到。
第四段:程序核实结果
当模型最后返回 final 时,Loop 会去检查 gent_loop_demo.md 是否真的在工作区。
这才叫闭环。
所以你看到的是“AI 自己把文章写出来了”,可程序内部其实发生的是:
任务理解
→ 计划草拟
→ 结构化决策
→ 文件写入
→ 结果回读
→ 完成校验
这比“问模型要一篇文章”扎实得多。
Agent Loop 到底难在哪里
讲到这里,很多人会觉得:原来 Agent Loop 也没什么,不就是一个 for-loop 加几个工具嘛。
这话对一半。
骨架确实不复杂。复杂的是,骨架一旦碰上现实,就会长出很多刺。
第一个难点:模型输出不稳定
你让它返回 JSON,它偏要先写一段抒情散文。你让它调用 write_file,它可能给你拼成 writefile。这不是少数情况,这是常态。
第二个难点:上下文会越来越脏
每跑一轮,history 就变长一点。工具结果、错误提示、修正指令、重试信息,全都往里塞。时间一长,模型上下文像没整理过的桌面,越找越乱。
第三个难点:工具结果是文本,不是世界本身
模型不是直接看到了文件系统,它看到的是“程序转述给它的世界”。这个转述如果不准、不全、太长、太短,都会影响判断。
第四个难点:完成条件很难定义
“写完一篇博客”算完成吗?
- 文件存在就行?
- 内容不能是空的?
- 结构要完整?
- PlantUML 代码块必须有?
很多 Agent 系统最后翻车,不是因为不会调用工具,而是因为完成条件太模糊。
如果把 Agent Loop 再抽象一层,我会这样理解
讲到最后,咱们可以把 Agent Loop 抽象成一个四件套:
1. State
当前任务、历史消息、短期记忆、长期记忆、已写文件路径。
2. Policy
系统提示词、动作格式、工具权限、最大迭代次数、恢复策略。
3. Actuator
工具层。它决定 Agent 能不能碰到外部世界。
4. Evaluator
校验逻辑。它决定什么叫“真的完成了”。
把这四样放在一起,Loop 才不是一个空转的脑袋,而是一台能落地的机器。
从这个角度看,Agent 不是什么新物种,它更像:
LLM + 状态机 + 工具系统 + 反馈回路。
只不过以前这些零件散着放,现在被拼成了一台能跑的机器。
一个不太中听但很实用的结论
很多人讨论 AI Agent 时,容易把重点放在“智能”上。可真到工程里,最吃力的地方常常不是 intelligence,而是 discipline。
也就是:
- 约束输出
- 限制路径
- 核实结果
- 控制迭代
- 处理失败
这些事听上去不性感,可没有它们,Agent Loop 就是一个会一本正经胡说八道的执行器。
就好比带徒弟。光聪明没用,还得守规矩,干完活还得回来说“师傅,我真拧紧了”,而不是站在那儿一脸诚恳地说“我感觉已经拧紧了”。
从工程再抬头看一眼:ReAct、Toolformer、Plan-and-Execute 分别在解决什么
写到这里,咱们可以把视角再往上提半层。
agent_loop_demo.py 当然不是照着哪一篇论文原样翻出来的,可它背后的思路,并不是天上掉下来的。过去几年,Agent 领域里有几条特别关键的线,今天工程里常见的做法,多少都能在里面找到影子。
ReAct:边想边做,别把推理和行动拆成两张皮
ReAct 这个名字,来自 Reason + Act。
它最有价值的地方,是把“推理”和“行动”放进了同一个闭环,而不是先在脑子里想完一切,再出去碰世界。
它的基本节奏是:
Thought → Action → Observation → Thought → Action → Observation
这套东西解决的,是传统 Chain-of-Thought 的一个老毛病:模型能想很多,可它想出来的东西没法立刻去验证。ReAct 让模型一边想,一边查,一边修正。
如果你回头看这篇里的 demo,会发现味道其实很像:
- 根据当前上下文决定下一步动作
- 调工具
- 把 observation 塞回去
- 再做下一轮决策
区别只在于,这个 demo 为了工程稳定,没有把 Thought 明文打印出来,而是把“想什么”压缩成了结构化 JSON Action。论文表达更显式,工程实现更克制,但骨架是一家的。
论文链接:
- ReAct: Synergizing Reasoning and Acting in Language Models https://arxiv.org/abs/2210.03629
Toolformer:重点不在循环本身,而在模型怎么学会用工具
如果说 ReAct 更像是在讲“流程怎么走”,那 Toolformer 更像是在讲“工具意识怎么长出来”。
Toolformer 关心的问题是:
- 什么时候该调用工具
- 调哪个工具
- 参数怎么填
- 返回结果怎么并回后续生成
它的价值,不只是告诉你“可以加工具”,而是进一步问:模型能不能学会主动、合适地使用工具。
放回这支 demo 里看,工具集合是我们手工定义的,调用协议也是提示词硬规定的,所以它更像“框架教模型做事”;而 Toolformer 代表的是另一个方向:让模型在训练过程中逐渐形成用工具的习惯。
这两条路并不冲突。工程里常见的做法,通常是先靠框架约束把系统跑稳,再慢慢往更强的工具选择能力演进。
论文链接:
- Toolformer: Language Models Can Teach Themselves to Use Tools https://arxiv.org/abs/2302.04761
Plan-and-Execute:任务太长时,先列施工单,再动手
工程界常说的 Plan-and-Execute,核心意思很简单:
- 先单独做一轮 planning
- 把大任务拆成几步
- 再进入执行循环
- 必要时边执行边修计划
它和 ReAct 的区别,不是谁更高级,而是“计划”放在什么位置。
ReAct 更像老师傅现场修机器,边看边拧。
Plan-and-Execute 更像先在白板上写施工步骤,再开工。它更适合这类任务:
- 写长文档
- 多文件修改
- 先调研、再生成、再验证
- 目标明确,但过程较长
你再看 agent_loop_demo.py 里的 _create_plan(),就会发现这个 demo 其实已经踩进这条路了。它没有把 planner 和 executor 分成两套大系统,但“先做计划,再进入循环”这个味道是很清楚的。
这里我顺手说一个容易混淆的小点:
Plan-and-Execute 更常见于工程实践和框架命名;如果你想找更直接的论文脉络,学术上最接近的是 Plan-and-Solve Prompting。
Plan-and-Solve 的关键思想也是:
- 先把问题拆成子问题
- 再按计划逐步求解
它原本更偏 reasoning prompt,不是完整 agent 框架,但理论指向非常清楚:复杂任务不要一口吞,先规划,再执行。
论文链接:
- Plan-and-Solve Prompting: Improving Zero-Shot Chain-of-Thought Reasoning by Large Language Models https://arxiv.org/abs/2305.04091
把三者放在一起看,就比较不容易乱
如果硬要一句话记住这三条路,我会这么分:
| 模式 | 最关心的问题 | 关键词 |
|---|---|---|
| ReAct | 推理和行动怎么闭环 | Thought / Action / Observation |
| Toolformer | 模型怎么学会使用工具 | API selection / tool use |
| Plan-and-Execute | 长任务怎么先拆再做 | planning first / staged execution |
说得再白一点:
- ReAct 像边开车边看路
- Toolformer 像学会什么时候该看导航、什么时候该掏计算器
- Plan-and-Execute 像出发前先把路线画在纸上
今天很多工程里的 Agent,其实不是三选一,而是三者混着来:
- 外层先做 planning
- 内层按 ReAct 风格循环执行
- 工具调用能力则往 Toolformer 那个方向继续长
所以 agent_loop_demo.py 这种小脚本,别看体量不大,它身上其实已经能看到今天 Agent 理论和工程实践汇流的影子。
明天就能用上的设计清单
- [ ] 把模型输出收束成有限动作,不要让它自由发挥整套协议
- [ ] 工具层一定做边界检查,尤其是文件系统和命令执行
- [ ] 工具结果要回流到上下文,否则 Loop 是断的
- [ ] 完成条件要落到外部事实,不要只信模型嘴里的“done”
- [ ] 给长任务加
max_iterations,别把系统做成永动机 - [ ] 为非法 JSON、半截输出、重复工具调用准备恢复策略
- [ ] 先做一个简单能跑的 memory,再考虑更重的 RAG 和向量检索
- [ ] 写大文件时强制分块写入,不要指望模型一次吐完还不出错
收个尾
这次 agent_loop_demo.py 自己把 output.md 写出来,表面上像是 AI 很能干;可我真正觉得有意思的,不是“它写出了一篇博客”,而是咱们终于能比较清楚地看到,Agent 是怎么从“会说”走到“会做”的。
它不是突然觉醒了。
它只是被放进了一个循环里,有了手脚,有了记忆,有了规矩,也有了刹车。
一句话收尾:
AI Agent Loop,不是魔法,它是一台被约束出来的发动机。模型负责点火,工具负责传动,记忆负责别熄火,规则负责别把车开沟里。
如果你也在做自己的 Agent,别急着一上来堆框架、堆术语、堆功能。先把最小闭环做出来。能读、能写、能验证、能停下。做到这一步,你的 Agent 才算真的开始上路。
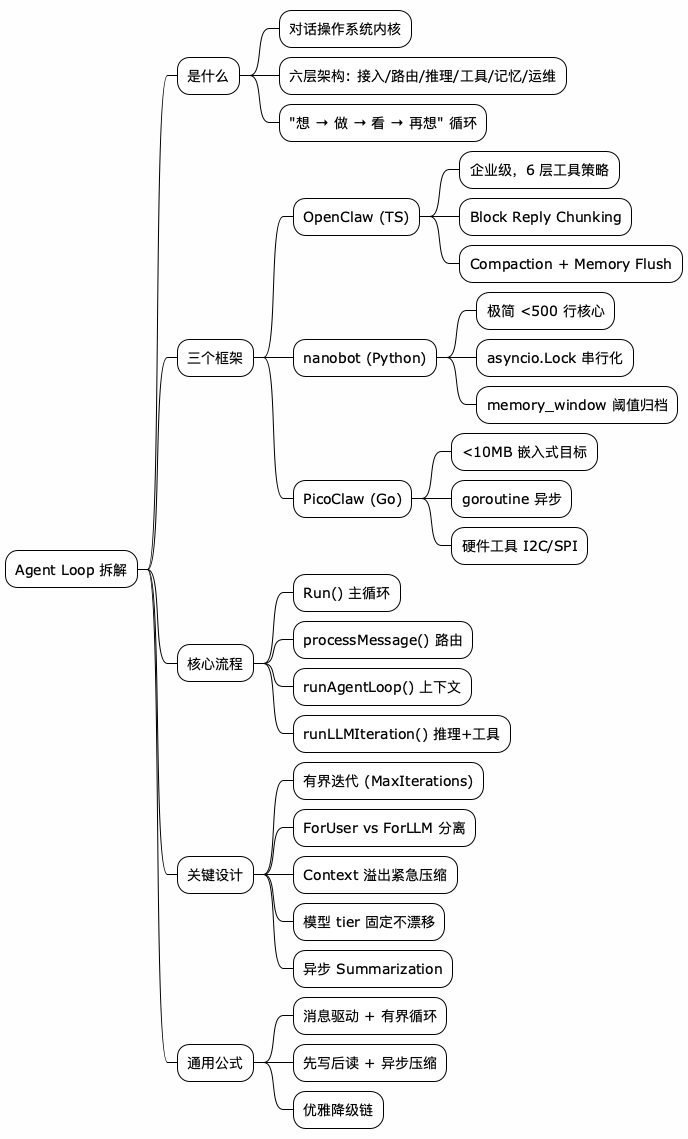
@startmindmap
!theme plain
skinparam backgroundColor #FEFEFE
* AI Agent Loop
** 本质
*** 不是聊天框
*** 是带工具的循环体
*** 理解任务 → 行动 → 观察 → 再行动
** 示例脚本
*** agent_loop_demo.py
*** 输出严格 JSON Action
*** 工具受 workspace 边界约束
** 核心组件
*** LLMClient
*** AgentTools
*** ShortTermMemory
*** LongTermMemory
*** Action
*** run_task()
** 关键流程
*** 先生成计划
*** 组装 prompt
*** 模型返回 tool/final
*** 执行工具
*** 结果回流
*** 校验输出文件
** 工程难点
*** JSON 不稳定
*** 上下文变脏
*** 工具观察不完整
*** 完成条件难定义
** 保护措施
*** safe_path
*** max_iterations
*** 非法 JSON 恢复
*** expected output 校验
** 一句话
*** Agent = LLM + 状态机 + 工具系统 + 反馈回路
@endmindmap
扩展阅读
lazy-rabbit-agent/example/agent_loop_demo.pylazy-rabbit-agent/example/output.md- ReAct: https://arxiv.org/abs/2210.03629
- Toolformer: https://arxiv.org/abs/2302.04761
- Plan-and-Solve Prompting(可视作 Plan-and-Execute 的重要理论近亲): https://arxiv.org/abs/2305.04091
- OpenAI function/tool calling 设计文档
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。