如何写好一个 AI Skill:让 AI Agent 从"什么都会"变成"真的能干活"
Posted on 二 17 3月 2026 in Tech
| Abstract | 如何写好一个 AI Skill |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Version | v1.0 |
| Updated | 2026-03-17 |
| License | CC-BY-NC-ND 4.0 |
大纲
1. 扎心场景:AI 什么都会,但什么都不精 2. What:AI Skill 到底是什么 3. Why:为什么你需要写 Skill 4. How:六步法写出一个好 Skill 5. 好 Skill 长什么样(真实案例拆解) 6. 写 Skill 的核心原则 7. 常见反模式 8. 行动清单 + 思维导图 9. 扩展阅读一、你的 AI Agent 是个"高学历文盲"
上周我让 Claude 帮我处理一个 PDF 表单——填写一份报销单。它很聪明,知道 PDF 的原理,能侃侃而谈 PDF 1.7 规范里 AcroForm 和 XFA 的区别。但你猜怎么着?它不知道我用的是 pypdf 还是 pdftk,不知道我的表单字段名叫什么,不知道填完之后要存到哪个目录。
它就像你从清华招来的实习生:微积分能手推,但公司的 Git 分支策略、CI/CD 流水线、代码规范,一概不知。
这不是 AI 的问题,是你没给它"入职培训"。
AI Skill 就是这份入职培训手册。它把你的领域知识、工具链、工作流程和最佳实践,打包成一个 AI 能理解、能执行的模块。写得好,AI 就是你团队里最靠谱的成员;写得烂,它还是那个"高学历文盲"。
二、AI Skill 到底是什么
简单说,AI Skill 是一个模块化的知识包,用来把通用 AI 变成某个领域的专家。
它一般包含三层:
my-skill/
├── SKILL.md # 核心:指令 + 工作流(必须有)
└── 可选资源
├── scripts/ # 可复用的脚本(Python/Bash 等)
├── references/ # 参考文档(API 文档、Schema 等)
└── assets/ # 输出用的素材(模板、图片、字体等)
SKILL.md 的两个部分
1) Frontmatter(元数据):决定"什么时候触发"
---
name: pdf-editor
description: >
PDF 处理工具包:支持文本提取、表格解析、文档合并拆分、表单填写。
当需要处理 PDF 文件时使用。
---
这段 YAML 是 Skill 的"门牌号"。AI Agent 扫描所有 Skill 的 name 和 description,决定哪个 Skill 该上场。写得模糊,Agent 就不知道什么时候该用你;写得精准,它才能在正确的时机把你请出来。
2) Body(正文):告诉 AI "怎么干活"
正文是 Markdown 格式的指令,包括工作流步骤、代码示例、决策树、注意事项等。它只在 Skill 被触发后才加载——所以不用担心浪费 context window。
一句话总结
Skill = 触发条件(description)+ 操作手册(body)+ 工具箱(scripts/references/assets)
三、为什么你需要写 Skill
你可能会想:"直接在 Prompt 里写清楚不就行了?"
当然可以。就像你每次做菜都可以从头搜菜谱,而不是把常做的菜记在本子上。但如果你每周做三次红烧肉,你早晚会把步骤写下来。
写 Skill 的理由就三个:
1) 复用 —— 一次写好,到处触发。你不用每次对话都重复"请用 pypdf 库""请保存到 content/images/ 目录"。
2) 一致性 —— 团队里五个人用 AI,如果没有统一的 Skill,五个人写出来的代码风格、文件命名、工作流程全不一样。
3) 质量天花板更高 —— Prompt 写得再好,2000 字是极限。Skill 可以拆成多层:SKILL.md 放核心流程,references/ 放详细文档,scripts/ 放可执行代码。AI 按需加载,既不浪费 token,又能保证深度。
打个比方:Prompt 是口头叮嘱,Skill 是 SOP 手册。口头叮嘱对简单任务够用了,但当任务变复杂、需要多步骤、涉及多文件,你需要一本手册。
四、六步法:从想法到可用的 Skill
这是我总结的创建 AI Skill 的完整流程,核心参考了 Anthropic 的 Skill Creator 指南,再结合自己踩坑的经验。
Step 1:用具体例子理解需求
别急着动手写 SKILL.md。先问自己三个问题:
- 用户会怎么触发这个 Skill?("帮我处理这个 PDF"、"生成一份周报"、"把这段代码重构一下")
- Skill 需要处理哪些变体?(不同格式的 PDF?不同模板的周报?)
- 什么是"做得好"的标准?(输出的 PDF 能正确填表?周报格式统一?)
举个例子:如果你要做一个"PDF 处理 Skill",你的具体场景可能是:
场景 1:用户说"帮我把这三个 PDF 合并成一个"
场景 2:用户说"把这个 PDF 表单填好"
场景 3:用户说"提取这份报告里的所有表格"
三个场景,三种工作流。如果你一开始没想清楚,写出来的 Skill 就会"什么都能做,什么都做不好"。
Step 2:规划可复用的资源
拿着 Step 1 的场景,逐个分析:
| 场景 | 重复性工作 | 可抽取的资源 |
|---|---|---|
| 合并/拆分 PDF | 每次都要写 pypdf 的样板代码 | SKILL.md 里放代码片段 |
| 填写 PDF 表单 | 检测字段、坐标转换、校验 | scripts/ 放表单处理脚本 |
| 提取表格 | pdfplumber 的配置和后处理 | references/ 放高级用法文档 |
原则是:如果同样的代码/文档你写了两次以上,就该抽出来。
Step 3:初始化 Skill 目录
创建目录结构。如果你用 Anthropic 的 Skill Creator,它提供了一个脚手架脚本:
scripts/init_skill.py my-skill --path ./skills/
如果你自己搭,只需要一个 SKILL.md 和按需的子目录:
pdf-editor/
├── SKILL.md
├── scripts/
│ ├── check_fillable_fields.py
│ └── fill_form.py
└── references/
└── advanced-usage.md
Step 4:写 SKILL.md
这是最关键的一步。分两部分写:
Frontmatter:写好触发条件
---
name: pdf-editor
description: >
PDF 处理工具包:支持文本提取、表格解析、合并拆分、旋转、水印、
表单填写、加密解密、图片提取、OCR 识别。
当用户提到 .pdf 文件或需要生成 PDF 时使用。
---
注意几个要点:
- description 要同时说做什么和什么时候用
- 把可能的触发词、触发场景都列出来
- 不要只写功能描述,要写用户意图
Body:写操作手册
把工作流写清楚。关键是用祈使句——你在给 AI 下指令,不是写论文。
# PDF Editor
## Quick Start
[3 行代码示例:读取 + 提取文本]
## 合并 PDF
1. 用 pypdf 的 PdfWriter 逐页添加
2. 保存到用户指定路径
## 填写表单
1. 运行 `scripts/check_fillable_fields.py` 检测字段类型
2. 如果有可填写字段 → 走 Fillable 工作流
3. 如果没有 → 走注解方式填写
4. 详细步骤见 forms.md
Step 5:测试 + 打包
写完之后,用真实场景测一遍。让 AI Agent 加载你的 Skill,然后模拟用户请求,看它能不能正确触发、正确执行。
常见的翻车点:
- description 写得太模糊,Agent 不知道什么时候该触发
- 工作流步骤漏了关键环节(比如忘了说"先读文件再编辑")
- scripts 里有 bug 没测过
- 引用了不存在的文件路径
Step 6:迭代
Skill 不是写一次就完事的。每次使用后,注意 AI 在哪些地方"跑偏"了,然后回来改 SKILL.md。
这跟写代码一样:第一版能跑,第二版好用,第三版才算优雅。
五、完整案例拆解:Anthropic 官方 PDF Skill
光讲原则太抽象,咱们拿一个真实的、设计精良的 Skill 开膛破肚——Anthropic 官方的 PDF 处理 Skill(来自 anthropics-skills/skills/pdf)。
5.1 目录结构一览
pdf/
├── SKILL.md # 核心指令(~315 行)
├── forms.md # 表单填写专题(~295 行)
├── reference.md # 高级用法参考(~612 行)
├── scripts/ # 8 个可复用脚本
│ ├── check_fillable_fields.py # 检查 PDF 是否有可填写字段
│ ├── extract_form_field_info.py # 提取表单字段信息
│ ├── extract_form_structure.py # 提取表单结构(标签、行、复选框)
│ ├── fill_fillable_fields.py # 填写可填写字段
│ ├── fill_pdf_form_with_annotations.py # 用注解方式填写非表单 PDF
│ ├── convert_pdf_to_images.py # PDF 转图片
│ ├── check_bounding_boxes.py # 校验边界框
│ └── create_validation_image.py # 生成验证图片
└── LICENSE.txt
先看整体:一个 SKILL.md,两个参考文档,八个脚本。没有 README,没有 CHANGELOG,没有 CONTRIBUTING.md——只有 AI 干活需要的东西,一个多余的文件都没有。
5.2 Frontmatter:触发条件写得像搜索引擎
---
name: pdf
description: >
Use this skill whenever the user wants to do anything with PDF files.
This includes reading or extracting text/tables from PDFs, combining
or merging multiple PDFs into one, splitting PDFs apart, rotating pages,
adding watermarks, creating new PDFs, filling PDF forms, encrypting/
decrypting PDFs, extracting images, and OCR on scanned PDFs to make
them searchable. If the user mentions a .pdf file or asks to produce
one, use this skill.
---
这个 description 的写法值得细品:
- 总括句打头:"whenever the user wants to do anything with PDF files" —— 一句话兜底,确保不漏
- 穷举式列举:reading、extracting、combining、merging、splitting、rotating、watermarks、creating、filling forms、encrypting/decrypting、extracting images、OCR —— 把用户可能说的每种意图都覆盖了
- 兜底触发条件:"If the user mentions a .pdf file or asks to produce one" —— 即使用户没说具体操作,只要提到
.pdf,也触发
跟这个对比一下反面教材:
# ❌ 太模糊,AI 不知道什么时候该用
description: "处理 PDF 文件"
# ❌ 只说了功能,没说触发场景
description: "PDF toolkit with text extraction and form filling"
5.3 Body 结构:Quick Start → 分类工具 → 速查表 → 路由
SKILL.md 的正文用了经典的"金字塔"结构:
第一层:Quick Start(5 行代码,10 秒上手)
from pypdf import PdfReader, PdfWriter
reader = PdfReader("document.pdf")
print(f"Pages: {len(reader.pages)}")
text = ""
for page in reader.pages:
text += page.extract_text()
不管 AI 要做什么,先给它一个能跑的 baseline。
第二层:按工具库分类的操作手册
Python Libraries
├── pypdf → 合并、拆分、旋转、元数据、加密
├── pdfplumber → 文本提取(带布局)、表格提取
└── reportlab → 创建新 PDF(含下标/上标的坑点提醒)
Command-Line Tools
├── pdftotext → 命令行文本提取
├── qpdf → 合并、拆分、旋转、解密
└── pdftk → 备选命令行工具
每个工具下面都是可以直接复制粘贴的代码,不是伪代码,不是"请参考文档"。
第三层:Quick Reference 速查表
| Task | Best Tool | Command/Code |
|---|---|---|
| Merge PDFs | pypdf | writer.add_page(page) |
| Extract text | pdfplumber | page.extract_text() |
| Create PDFs | reportlab | Canvas or Platypus |
| Fill PDF forms | pypdf or pdf-lib | See FORMS.md |
这张表是给 AI 的"决策索引"——先查表选工具,再按工具找代码。
第四层:路由到深度文档
→ 高级用法? 读 reference.md
→ 填表单? 读 forms.md
→ 问题排查? 读 reference.md 的 Troubleshooting 部分
SKILL.md 自己不超过 315 行,但通过路由可以调动 900+ 行的深度内容。
5.4 forms.md:低自由度任务的"保姆级"工作流
表单填写是 PDF 处理里最脆弱的操作——坐标差一个像素,文字就跑偏了。所以这部分用了极低自由度的写法。
先看开头,一句话定调:
CRITICAL: You MUST complete these steps in order. Do not skip ahead to writing code.
直接告诉 AI:"别自作聪明,老老实实按步骤来。"
然后是一个二分决策:
检查 PDF 是否有可填写字段
├── 有 → Fillable fields 工作流
└── 没有 → Non-fillable fields 工作流(注解方式)
├── 先尝试 Structure Extraction(更精准)
└── 不行再用 Visual Estimation(兜底)
Fillable 工作流,4 步走:
1. python scripts/check_fillable_fields.py <file.pdf>
→ 判断是否有可填写字段
2. python scripts/extract_form_field_info.py <input.pdf> <field_info.json>
→ 提取字段列表(field_id, page, rect, type)
3. 创建 field_values.json
→ 按指定 JSON 格式填入值
4. python scripts/fill_fillable_fields.py <input.pdf> <field_values.json> <output.pdf>
→ 执行填写
Non-fillable 工作流更复杂,但结构同样清晰——先试结构提取(Approach A),不行再用视觉估算(Approach B),还有一个混合方案(Hybrid Approach)。每种方案都给了完整的命令行调用示例和 JSON 格式规范。
这是"自由度匹配脆弱性"原则的教科书级实现:越容易出错的环节,指令写得越死。
5.5 scripts/:把重复代码变成确定性工具
8 个 Python 脚本,各司其职:
| 脚本 | 职责 | 为什么要抽成脚本 |
|---|---|---|
check_fillable_fields.py |
检查 PDF 是否有可填写字段 | 判断用哪条工作流分支 |
extract_form_field_info.py |
提取表单字段的 ID、坐标、类型 | 每次都要写的重复代码 |
extract_form_structure.py |
提取文本标签、行线、复选框 | 复杂的 PDF 解析逻辑 |
fill_fillable_fields.py |
填写可填写字段 + 自动校验 | 脆弱操作,不能让 AI 自由发挥 |
fill_pdf_form_with_annotations.py |
用注解方式填写非表单 PDF | 坐标转换容易出错 |
convert_pdf_to_images.py |
PDF 转图片 | 视觉验证的基础工具 |
check_bounding_boxes.py |
校验边界框有没有重叠/过小 | 防错机制 |
create_validation_image.py |
生成校验用图片 | 让 AI 自己检查填写结果 |
关键洞察:这些脚本不只是"省得 AI 重写",更重要的是确定性。AI 生成的代码每次可能不一样,但脚本每次跑出来的结果都一样。对于"差一个像素就出错"的表单填写,这种确定性就是生命线。
5.6 reference.md:按需加载的知识库
612 行的深度参考文档,涵盖:
- pypdfium2(PyMuPDF 的替代品)
- JavaScript 库(pdf-lib、pdfjs-dist)
- 高级命令行操作
- 复杂工作流(批量处理、图片提取、裁剪)
- 性能优化
- 问题排查
这些内容不在 SKILL.md 里——只有当 AI 需要高级功能时才加载。99% 的 PDF 任务用 SKILL.md 就够了。
5.7 这个 Skill 教给我们什么
把 PDF Skill 的设计模式提炼出来,就是这五条:
- description 要像搜索引擎的索引:穷举动词(reading, extracting, merging...)+ 兜底条件(mentions .pdf)
- Body 用金字塔结构:Quick Start → 分类工具 → 速查表 → 路由到深度文档
- 脆弱操作用脚本兜底:表单填写不让 AI 自由发挥,全走预置脚本
- 决策树比工具列表有用:告诉 AI "什么时候用什么",而不只是"有什么"
- 文档分层加载:SKILL.md(315 行)→ forms.md(295 行)→ reference.md(612 行)
补充案例:DOCX 处理 Skill 的决策树
除了 PDF Skill,DOCX Skill 的决策树也值得一提:
读/分析 → 用 pandoc 提取文本
创建新文档 → 用 docx-js
编辑已有文档:
├── 自己的文档 + 简单修改 → 直接编辑 XML
└── 别人的文档 / 正式文档 → 用 Redlining 工作流(保留修订记录)
Skill 里最难写的不是"怎么做",而是"什么情况下用哪种方式做"。决策树帮 AI 在不同场景下选择正确的路径,比给一堆工具让它自己猜强得多。
六、写 Skill 的三条核心原则
原则 1:Context Window 是公共资源,别浪费
AI 的 context window 就像会议室的白板——你写得越多,留给别人(其他 Skill、用户消息、对话历史)的空间就越少。
默认假设:AI 已经很聪明了。 只写它不知道的东西。
❌ "Python 是一种编程语言,可以用 pip 安装包..."
✅ "使用 pypdf>=3.0,注意 PdfReader 的 API 在 3.x 有 breaking change"
具体策略:
- SKILL.md 控制在 500 行以内
- 详细文档放
references/,按需加载 - 重复执行的代码放
scripts/,不用每次重写
原则 2:自由度匹配任务的脆弱性
不是所有指令都要写得一样细。关键看任务有多"脆弱"——出错的代价有多大。
| 自由度 | 适用场景 | 示例 |
|---|---|---|
| 高(文字描述) | 多种方式都行,取决于上下文 | "根据文章主题选择合适的开头方式" |
| 中(伪代码/参数化脚本) | 有最佳实践,但允许变化 | "输出 JSON 格式:{field_id, page, value}" |
| 低(具体脚本,不能改) | 操作脆弱、容错率低 | "渲染 PlantUML 必须用这个脚本和这组参数" |
打个比方:过独木桥需要护栏(低自由度),走草原只需要指个方向(高自由度)。
原则 3:渐进式披露——别一次倒完
别把所有信息都塞进 SKILL.md。用三层结构:
第 1 层:Frontmatter(name + description)
→ 始终在 context 里,~100 词
→ 决定"要不要触发这个 Skill"
第 2 层:SKILL.md Body
→ 触发后才加载,<5000 词
→ 核心工作流和决策逻辑
第 3 层:scripts/ + references/ + assets/
→ 按需加载,无上限
→ 详细文档、可执行代码、模板素材
实战模式举例:
模式 A:总纲 + 参考文档
# PDF 处理
## Quick Start
[3 行代码示例]
## 高级功能
- 表单填写:见 [forms.md](forms.md)
- API 参考:见 [reference.md](reference.md)
模式 B:按领域拆分
bigquery-skill/
├── SKILL.md(概览 + 路由)
└── references/
├── finance.md # 财务指标
├── sales.md # 销售数据
└── product.md # 产品数据
用户问销售数据时,AI 只加载 sales.md,不会把财务和产品的内容也塞进 context。
七、常见反模式:这些坑我都踩过
反模式 1:description 太模糊
# ❌ 差
description: "处理文档"
# ✅ 好
description: >
DOCX 文档创建、编辑和分析,支持批注、修订追踪、格式保持和文本提取。
当需要创建/修改/分析 .docx 文件时触发。
模糊的 description 就像门牌号写着"某公司"——快递员找不到你。
反模式 2:把所有东西都塞进 SKILL.md
如果你的 SKILL.md 超过 500 行,说明你该拆了。把详细内容移到 references/,把重复代码移到 scripts/。
反模式 3:只写了 What,没写 When 和 How
# ❌ 差:只告诉 AI 有这个功能
支持 PDF 表单填写。
# ✅ 好:告诉 AI 什么时候用、怎么用
## 表单填写
当用户需要填写 PDF 表单时:
1. 先读取 forms.md 了解表单处理流程
2. 使用 pypdf 打开 PDF
3. 用 reader.get_fields() 获取表单字段
4. 填充字段值
5. 保存到输出路径
反模式 4:创建一堆"辅助文件"
# ❌ 不需要这些
README.md
INSTALLATION_GUIDE.md
QUICK_REFERENCE.md
CHANGELOG.md
CONTRIBUTING.md
Skill 是给 AI 用的,不是给人类读的开源项目。AI 不需要 README,不需要安装指南,不需要 CHANGELOG。只保留 AI 干活需要的文件。
反模式 5:没测就发布
这和不写单测就上线是一个道理。写完 Skill 之后,至少用 3 个不同的真实场景测一遍:
- 能正确触发吗?
- 工作流步骤跑得通吗?
- scripts 有 bug 吗?
- 输出符合预期吗?
八、Skill 写作自检清单
写完一个 Skill 之后,对着这张表过一遍:
触发层(description)
- [ ] description 同时说了"做什么"和"什么时候触发"
- [ ] 列出了用户可能的触发词和意图
- [ ] 与其他 Skill 的 description 没有歧义重叠
工作流层(SKILL.md Body)
- [ ] 用祈使句写指令("读取文件",不是"可以读取文件")
- [ ] 关键步骤有具体代码示例
- [ ] 有决策树/条件分支(if-else 逻辑清晰)
- [ ] SKILL.md 不超过 500 行
- [ ] 引用的文件路径都存在
资源层(scripts/references/assets)
- [ ] 重复执行的代码抽成了 script
- [ ] 详细文档放在了 references/,而不是塞在 SKILL.md 里
- [ ] scripts 经过了真实测试
- [ ] assets 的模板是最新版
质量检查
- [ ] 用 3 个以上真实场景测试过
- [ ] AI 能在正确时机触发这个 Skill
- [ ] AI 按工作流执行时,不会跑偏
- [ ] 输出质量符合预期
- [ ] 没有"AI 不需要知道的废话"
九、一些有启发的观点
写 AI Skill 这件事,本质上是一个知识工程问题。这里有几个我觉得值得深思的观点:
"Skill 是给另一个你的 Onboarding 文档" —— 想象你要把工作交接给一个聪明但对你的项目一无所知的人。你不会从"什么是 Python"开始教,但你会告诉他"我们的 CI 用 Jenkins,部署流程是这样的,注意这几个坑"。写 Skill 的心态应该跟这个一样。
"Context window 是公共资源" —— 这句话来自 Anthropic 的 Skill Creator 文档,我觉得是最被低估的观点。每多一行废话,AI 就少一行理解用户需求的空间。写 Skill 最难的不是写什么,而是不写什么。
"自由度应该和脆弱性成反比" —— 这是工程思维在 AI 指令设计上的体现。不是所有步骤都需要 step-by-step,也不是所有步骤都可以"随机应变"。关键是识别哪些环节容错率低,给这些环节上"护栏"。
"Progressive Disclosure 是 Skill 架构的核心模式" —— 和 UI 设计一样,信息不是越多越好。好的 Skill 像好的 API 文档:首页只有 Quick Start,详细内容按需跳转。
十、附赠:一个用来检查 Skill 的 Skill
既然有了写 Skill 的方法论,能不能让 AI 自己来检查 Skill 质量?
我写了一个 skill-reviewer Skill,它会按 5 个维度(触发层、工作流层、资源层、渐进式披露、脆弱性匹配)给目标 Skill 打分,输出结构化的审查报告,并给出具体修改建议。
目录结构很简单:
skill-reviewer/
├── skill.md # 审查流程 + 评分标准
└── references/
└── checklist-quick.md # 快速检查清单(轻量版)
评分维度示例:
| 维度 | 检查项(示例) | 满分 |
|---|---|---|
| A. 触发层 | description 说了 What + When?触发条件不含歧义? | 12 |
| B. 工作流层 | 有 Quick Start?决策树清晰?代码能跑?≤500 行? | 18 |
| C. 资源层 | 重复代码抽成 script?无冗余文件?引用不孤立? | 15 |
| D. 渐进式披露 | 三层加载有效?Body 是路由层不是百科全书? | 9 |
| E. 脆弱性匹配 | 脆弱操作低自由度?有验证步骤? | 9 |
你可以从 这里 下载
但有一个重要提醒
让同一个 LLM 审查它自己写的 Skill,效果未必好。
这不是谦虚,是认知科学。人类有个偏差叫 "blind spot bias"——你很难发现自己的盲区,因为它之所以是盲区,恰恰是因为你看不见。LLM 也一样:
- 它倾向于给自己的输出打高分(self-serving bias 的 AI 版本)
- 它会遗漏与自己同类的问题——如果它写 description 时习惯性地太模糊,审查时也不会觉得模糊
- 它不会质疑自己的"常识"——如果它默认某个工作流是对的,审查时也不会挑战
所以,更有效的做法是:
- 交叉审查:用 Claude 写的 Skill,拿 GPT 来审;反过来也行。不同模型的盲区不一样,交叉审查能互补。
- 人类抽查:至少让一个人快速过一遍审查报告,看看有没有"明显正确但实际有问题"的评分。
- 真实任务验证:任何审查都替代不了实际使用。跑 3 个真实场景,比读 10 遍审查报告有用。
这就像代码审查:你不会让作者自己 Review 自己的 PR。同理,Skill 的质量保障最好也引入"第二双眼睛"——哪怕那双眼睛也是 AI 的。
十一、总结
AI Skill 不是什么高深的东西——它就是一份写给 AI 的操作手册。但"写清楚"这件事,从来都不简单。
回顾一下核心方法:
- 从场景出发:先列举具体的使用场景,再动手写
- 三层架构:Frontmatter(触发)→ Body(工作流)→ Resources(深度内容)
- 三条原则:省 token、匹配自由度、渐进式披露
- 测试驱动:写完就测,测完就改
如果你只记住一句话,记住这个:
写 Skill 的最高境界,是 AI 读完之后觉得"这不就是我自己总结的经验吗?"——它没有意识到在被教。
思维导图
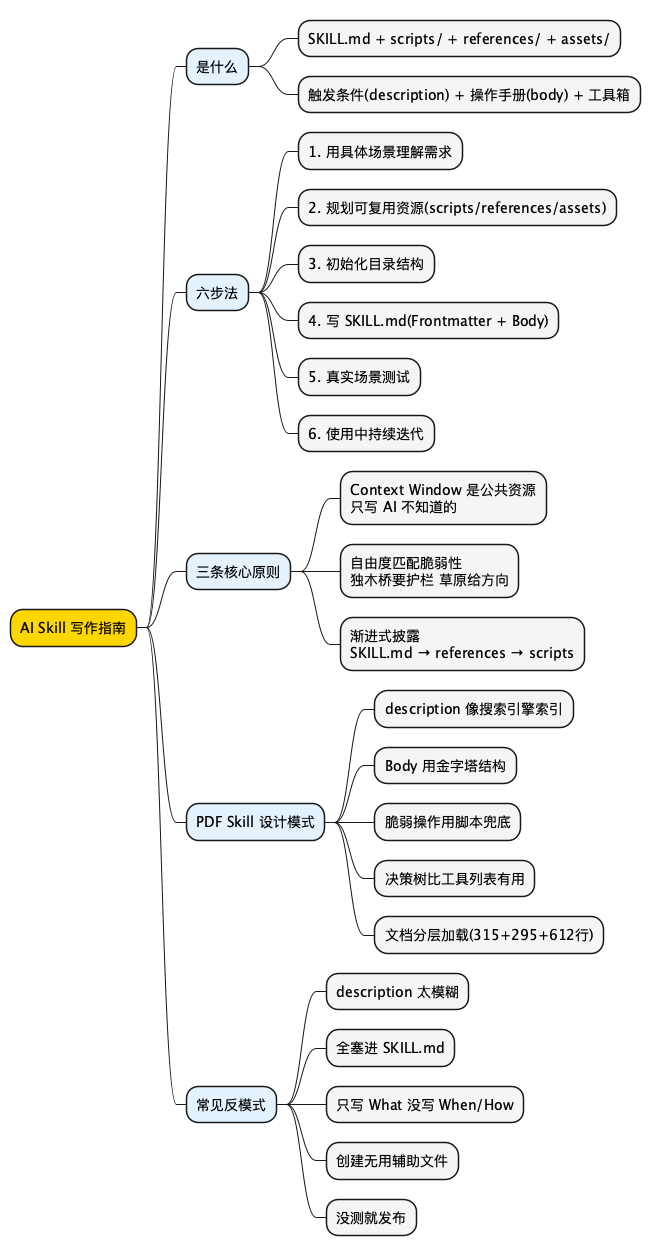
@startmindmap
<style>
mindmapDiagram {
node { BackgroundColor #FAFAFA }
:depth(0) { BackgroundColor #FFD700 }
:depth(1) { BackgroundColor #E3F2FD }
:depth(2) { BackgroundColor #F5F5F5 }
}
</style>
* AI Skill 写作指南
** 是什么
*** SKILL.md + scripts/ + references/ + assets/
*** 触发条件(description) + 操作手册(body) + 工具箱
** 六步法
*** 1. 用具体场景理解需求
*** 2. 规划可复用资源(scripts/references/assets)
*** 3. 初始化目录结构
*** 4. 写 SKILL.md(Frontmatter + Body)
*** 5. 真实场景测试
*** 6. 使用中持续迭代
** 三条核心原则
*** Context Window 是公共资源\n只写 AI 不知道的
*** 自由度匹配脆弱性\n独木桥要护栏 草原给方向
*** 渐进式披露\nSKILL.md → references → scripts
** PDF Skill 设计模式
*** description 像搜索引擎索引
*** Body 用金字塔结构
*** 脆弱操作用脚本兜底
*** 决策树比工具列表有用
*** 文档分层加载(315+295+612行)
** 常见反模式
*** description 太模糊
*** 全塞进 SKILL.md
*** 只写 What 没写 When/How
*** 创建无用辅助文件
*** 没测就发布
@endmindmap
扩展阅读
- Anthropic —— Skill Creator 官方指南(本文方法论的主要参考来源)
- Anthropic —— Claude Code 文档(SKILL.md 的宿主环境)
- Cursor —— Rules & Skills 文档(另一种 Skill 实现方式)
- Ethan Mollick —— 《Co-Intelligence: Living and Working with AI》(AI 协作的底层思维)
- Daniel Kahneman —— 《Thinking, Fast and Slow》(渐进式披露的认知科学基础)
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。