让 AI 如你如愿:从 Harness Engineering 说起
Posted on 二 12 5月 2026 in AI
| Abstract | 让 AI 如你如愿:从 Harness Engineering 说起 |
|---|---|
| Authors | Walter Fan |
| Category | AI |
| Status | v0.3 |
| Updated | 2026-05-13 |
| License | CC-BY-NC-ND 4.0 |
让 AI 如你如愿:从 Harness Engineering 说起
短大纲
- 这篇文章读的是 Martin Fowler 网站上的 Harness engineering for coding agent users。
- 核心观点很朴素:coding agent 靠不靠谱,不只看模型,也看模型外面的 harness。
- Harness 可以粗略理解为:规则、上下文、工具、测试、检查器、反馈机制,以及人类给它搭好的工作台。
- 对工程团队来说,未来拼的可能不是"谁的 prompt 更玄学",而是谁能把 agent 放进一个可验证、可调校、能持续改进的系统里。
- 文末给一个 Java Web / Spring Boot 项目的最小 harness 示例,方便直接照着改。
- 这仍是一篇读书笔记,后续还可以补上我在 Cursor / Claude Code / Codex 里的真实使用体会。
一、别再把 AI 想成一个"会聊天的模型"
过去两年,大家一说 AI,多半先想到一个聊天框。
你输入一句话,它回你一大段。你让它写代码,它真的写了。你让它解释异常,它也能说得头头是道。于是很多人自然得出一个结论:AI 的核心就是 LLM,谁的模型强,谁就赢。
这话固然有道理,可是只说了一半。
从工程角度看,一个裸模型就像一个聪明但没进过你们公司、没读过你们代码、也不知道线上事故有多疼的新人。它可以很聪明,但它不知道"这里不能乱改"、"这个接口有历史包袱"、"这个测试虽然慢但很保命"。如果你直接把生产代码丢给它,让它自由发挥,那就像把方向盘交给一个开车技术不错、但没看过地图的人。
Martin Fowler 网站上的这篇文章,把这个问题说得很清楚:要让 coding agent 少添乱、多干活,我们需要的不只是更强的模型,还需要 harness engineering。
二、什么是 Harness?
LangChain 有一句很简洁的说法:Agent = Model + Harness。
Model 是模型本身,Harness 是模型外面那一整套让它能干活的东西。放在 coding agent 的语境里,harness 可以包括:
- 系统提示词、项目规则、
AGENTS.md、skills 之类的指导材料; - 代码检索、上下文管理、文件系统、终端、浏览器、MCP 工具;
- 测试、lint、类型检查、架构约束、pre-commit hook;
- 代码审查指令、AI reviewer、质量门禁;
- 团队约定、服务模板、脚手架、运行手册。
说人话,harness 就是你给 Agent 配的导师和员工守则。
只给它一个模型,相当于给新人一张椅子,让他自己找电脑、找仓库、找需求、找测试环境,顺便猜一猜你们团队到底怎么干活。搭好 harness,则是把电脑、权限、文档、任务单、检查表、CI 和老同事的提醒都摆好。新人还是新人,但犯低级错误的概率会明显下降。
当然,agent 不是人,它没有羞耻心,也不会因为把 300 行函数写成 600 行而半夜睡不着。它需要更明确的约束和更快的反馈。
这正是 harness engineering 的价值。
三、两个关键词:Feedforward 和 Feedback
这篇文章里有一个框架很实用:把 harness 分成两类控制手段。
第一类叫 Feedforward,可以理解为"事前引导"。agent 动手前,先告诉它应该怎么做,什么风格是对的,哪些边界不能碰。
例子包括:
- 代码风格规则;
- 项目结构说明;
- 架构原则;
- 安全开发要求;
- "怎么启动项目、怎么跑测试、怎么提交变更"的 skill。
第二类叫 Feedback,可以理解为"事后反馈"。agent 动手后,观察结果,再让它自我修正。
例子包括:
- 单元测试失败;
- lint 报错;
- 类型检查失败;
- 架构边界测试失败;
- AI reviewer 指出"这里的修复只是掩盖症状,没有解决根因"。
两者缺一不可。
只有 feedback,没有 feedforward,agent 就像一个总被老师批改作业、但从不听课的学生。它能改错,可是同样的错可能反复出现。只有 feedforward,没有 feedback,则像把规章制度贴满墙,却没人检查执行情况。看上去很严谨,实际效果全靠运气。
工程上真正有用的是一个小循环:先引导,再检查;检查出问题,再改进引导。无他,别让同一个坑反复绊倒同一个 agent。
四、Computational 与 Inferential:别把所有判断都交给 LLM
文章还把 harness 的执行方式分成两种:Computational 和 Inferential。这组词有点学术,说人话就是:有些检查靠机器算,有些判断靠模型猜。
Computational 是确定性的、机器能快速算出来的东西,比如:
- 测试;
- lint;
- type checker;
- 静态分析;
- 架构规则检查;
- 依赖扫描。
Inferential 则是需要语义判断的东西,比如:
- AI code review;
- "这个方案是不是过度设计";
- "这个测试是不是只测了实现,没有测行为";
- "这段代码虽然能跑,但是否符合团队习惯"。
老工程师都知道,能用确定性工具解决的问题,不要轻易交给玄学。
不是说 LLM 不好,而是成本和可靠性不同。一个 type checker 能在几秒内告诉你类型不对,而且不会今天说错、明天说对。AI reviewer 可以看出更高层次的问题,但它慢、贵,偶尔还会一本正经地胡说八道。就像请专家会诊很有价值,但你不能让专家每天帮你量体温。
所以比较健康的做法是:
- 快、便宜、确定的检查,尽量前置到本地、pre-commit 或 agent 工作循环里;
- 慢、贵、需要语义判断的检查,放到更合适的位置,比如 MR review、nightly job 或关键变更前;
- 不要让 agent 只靠自己"感觉良好",要给它能读懂、能执行、能修正的信号。
这也是传统软件工程里 "shift left" 的老道理,只不过现在多了一个新角色:coding agent。
五、三类 Harness:可维护性、架构适配、行为正确性
把 coding agent 的 harness 分成三个方向,我觉得很适合作为团队讨论的起点。别急着买工具,先问清楚自己到底想约束什么。
1. Maintainability Harness
这是最容易起步的一类。它关注代码可维护性,比如重复代码、复杂度、测试覆盖率、风格一致性、死代码、依赖风险。
这类问题有大量现成工具。对 agent 来说,也最容易形成反馈循环:写完代码,跑检查,失败就修。
不过它也有边界。可维护性检查能告诉你"这个函数太复杂",却不一定能告诉你"你修错了问题"。它能抓住很多结构性毛病,但不一定抓得住需求理解错误。
2. Architecture Fitness Harness
这类 harness 关注系统是否还保持在我们想要的架构方向上。
比如:
- 模块边界有没有被穿透;
- API 层有没有偷偷调用数据库;
- 日志是否符合可观测性要求;
- 性能预算有没有被破坏;
- 安全规则有没有被绕开。
Thoughtworks 早年提出过 Architectural Fitness Function,意思是用自动化检查持续验证架构特征。现在有了 coding agent,这个概念反而更有价值。因为 agent 写代码很快,漂移也可能更快。
以前是人慢慢把系统写歪,现在是 agent 可以很勤快地帮你写歪。
3. Behaviour Harness
最难的是行为正确性。
代码能编译,测试也绿,并不代表它真的满足业务需求。尤其当测试本身也是 agent 写的时候,问题就更微妙了。它可能写一组"自证清白"的测试,看起来覆盖率很漂亮,实际上只是证明它自己的实现符合它自己的想象。
这也是文章里最谨慎的部分。当前比较现实的做法包括:
- 让人类给出更清晰的功能规格;
- 使用 approved fixtures 等模式,把关键输入输出固化下来;
- 用端到端测试验证用户可见行为;
- 对 AI 生成测试的质量再做检查,比如 mutation testing;
- 保留必要的人工验收。
一句话:行为 harness 还远没成熟。谁说"agent 已经可以完全替代工程师做需求实现",多半是还没被线上 bug 结结实实教育过。
六、Harnessability:不是所有代码库都一样好"拴"
文章里还有一个词很有意思:Harnessability。
不是每个代码库都同样适合被 harness 管起来。强类型语言天然有 type checker;清晰模块边界更容易写架构测试;成熟框架能减少 agent 需要操心的细节。反过来,一个历史包袱很多、结构松散、测试稀薄的老系统,最需要 harness,也最难搭 harness。
这听起来有点残酷,但很真实。
新项目可以从第一天就把 harnessability 当作设计目标:语言、框架、目录结构、测试策略、服务模板,都可以围绕"未来如何让人和 agent 都不容易犯错"来设计。
老项目则要务实一点。别一上来就想着"全自动智能体开发平台"。先找最疼、最常见、最容易自动化的几个点下手:
- agent 总是改错目录?补项目结构说明;
- agent 总是忘记跑测试?加本地检查脚本;
- agent 总是违反分层?加架构测试;
- agent 总是写不合规日志?加 lint 或 review skill;
- agent 总是误解任务?改需求模板和验收用例。
无他,先把重复踩的坑填上。
七、对我们有什么启发?
我读完这篇文章,最大的感受是:AI 工程化正在从"调 prompt"走向"建系统"。
Prompt 当然重要,但 prompt 只是 harness 里的一小块。真正能让 agent 稳定工作的,是它周围那套可观察、可验证、可迭代的工程设施。
这对工程团队至少有三个启发。
第一,把隐性经验显性化。老工程师脑子里的"这里不能这么写",如果只停留在脑子里,agent 永远不会知道。能写成规则就写成规则,能变成测试就变成测试,能做成模板就做成模板。
第二,把检查前移。不要等 MR review 才发现 agent 写了一堆风格不一致的代码。越便宜、越确定的检查,越应该靠近 agent 工作现场。
第三,把 harness 当成产品维护。规则会过期,测试会失效,skills 会互相打架,模板会和现实脱节。harness 不是一次性配置,而是需要持续演进的工程资产。
结合自己这段时间的使用,我还有四点体会。这几条不花哨,但很管用。
AGENTS.md要好好打磨。它是给 AI 编程工具看的说明书,也是团队给 agent 的第一份"入职手册"。不要冗长,但要把基本原则、工作流程、项目知识库位置和注意事项写清楚。- 项目知识库要建好。至少要有总体架构、技术栈、开发规则和惯例,再提供一个
index.md给 AI 编程工具做入口。没有入口,agent 就会像刚入职那天的我,在公司楼里找会议室,越走越心虚。 - 在让 AI 编程工具开始实现之前,设计文档最好用 OpenSpec 之类的 SDD 工具和 AI 充分讨论、审查。需求、约束、反例和测试用例要先摆出来,特别是端到端用例。
- Build Pipeline 中传统的静态检查和自动化测试不可少,还可以引入基于规则的 AI Review,再结合人工 review,在 PR/MR 合并之前把关。
如果一个项目还没有 AGENTS.md,不妨先从一个精简版开始。它不应该写成百科全书,更像机场指示牌:告诉人和 agent 往哪里走,真正的细节放到 README 或项目知识库里。
# AGENTS.md - {{PROJECT_NAME}}
<!-- First stop for coding agents and new contributors. Keep it short. -->
{{ONE_SENTENCE_PURPOSE}}
## 1. Project Snapshot
- Language / runtime: {{LANGUAGE_AND_VERSION}}
- Package manager: {{PACKAGE_MANAGER}}
- Task runner: {{TASK_RUNNER}}
- Entry point: {{ENTRY_POINT}}
- Knowledge base: {{KB_OR_README}}
- Owner / help: {{OWNER_OR_CHANNEL}}
## 2. Read First
1. {{ARCHITECTURE_DOC}}
2. {{CONVENTIONS_DOC}}
3. {{WORKFLOW_DOC}}
If time is short, read {{AI_SINGLE_FILE}} first.
## 3. Repo Layout
```text
{{REPO_TREE}}
```
Boundaries:
- Public surface: {{PUBLIC_SURFACE}}
- Internal modules: {{INTERNAL_SURFACE}}
- Danger zones: {{DANGER_ZONES}}
## 4. Commands
Use the task runner. Do not bypass wrappers unless asked.
```bash
{{SETUP_COMMAND}} # install deps
{{LINT_COMMAND}} # static checks
{{FORMAT_COMMAND}} # format code
{{TEST_COMMAND}} # test suite
{{BUILD_COMMAND}} # build artifact
```
Focused runs:
```bash
{{FOCUSED_TEST_EXAMPLES}}
```
## 5. Conventions
- {{RULE_1}} - {{REASON_1}}
- {{RULE_2}} - {{REASON_2}}
- {{RULE_3}} - {{REASON_3}}
- Never log secrets, tokens, request bodies, or PII - production logs are long-lived and searchable.
## 6. Change Workflow
{{CHANGE_WORKFLOW_SHORT}}
For design-heavy changes, create `docs/changes/{{CHANGE_ID}}/` with:
- `proposal.md`
- `design.md`
- `tasks.md`
Update docs when architecture, API, dependencies, workflow, or conventions change.
## 7. AI Working Protocol
Input expected:
```yaml
goal:
context:
constraints:
definition_of_done:
verification:
```
Output required:
```yaml
summary:
assumptions:
changes:
risks:
verification:
next_step:
```
Hard rules:
- No "done" without evidence.
- Ask when scope or compatibility is unclear.
- Keep the diff small.
- Do not touch danger zones without a design note.
- Never add logs that expose secrets, tokens, request bodies, or PII.
## 8. Gotchas
| Symptom | Likely cause | Fix |
| --- | --- | --- |
| {{SYMPTOM_1}} | {{CAUSE_1}} | {{FIX_1}} |
| {{SYMPTOM_2}} | {{CAUSE_2}} | {{FIX_2}} |
## 9. Keep This File Useful
Update this file when commands, top-level directories, KB layout, agent clients, or danger zones change.
<!-- last_updated: {{DATE}} -->
八、一个最小可用 Harness 清单
如果明天就想给团队的 coding agent 加一点约束,不妨从这张表开始。表不复杂,胜在能抄。
| 场景 | Feedforward:先告诉它 | Feedback:做完后检查 |
|---|---|---|
| 新人式迷路 | 项目结构、启动方式、常用命令 | smoke test、构建脚本 |
| 风格不一致 | 编码规范、命名习惯、日志规则 | lint、format、review skill |
| 分层被破坏 | 架构边界说明、允许依赖列表 | ArchUnit、import boundary check |
| 测试偷懒 | 测试策略、验收标准、fixture 规则 | coverage、mutation testing、人工抽查 |
| 安全问题 | 安全基线、敏感字段规则、权限模型 | SAST、secret scan、日志隐私检查 |
| 任务误解 | 清晰需求模板、反例、验收样例 | E2E test、QA review、产品验收 |
这张表不高级,但能落地。工程上很多事都是这样,先别追求"智能",先追求"不犯傻"。
九、Java Web 项目的 Harness 示例
光说概念容易飘。下面以一个常见的 Java Web 后台服务为例,假设它是 Spring Boot + Maven + Controller / Service / Mapper 分层,入口是 HTTP API,后面连数据库和外部服务。
这个项目的风险边界大概是这样:外部请求从 Controller 进来,参数可能不可信;Service 承担业务规则和事务边界;Mapper 访问数据库,不能拼接 SQL;日志里不能泄露 token、手机号、邮箱、订单明细等敏感信息;权限检查不能只靠前端"自觉"。这些话如果只在老工程师脑子里,agent 不会自动知道。
一个最小可用的 harness,可以长成这样:
my-order-service/
├── AGENTS.md
├── docs/ai/index.md
├── docs/ai/architecture.md
├── docs/ai/api-contracts.md
├── scripts/agent-check.sh
├── src/main/java/com/example/order/
│ ├── controller/
│ ├── service/
│ └── mapper/
├── src/test/java/com/example/order/architecture/LayeringTest.java
└── src/test/resources/fixtures/order-create-success.json
1. Feedforward:先把规则写给 agent 看
AGENTS.md 不必写成公司制度汇编,太长了 agent 也容易抓不住重点。先写成这样就够用:
# Order Service Agent Guide
## Architecture
- Follow Controller -> Service -> Mapper. Controller must not call Mapper directly.
- Keep transaction boundaries in Service methods.
- DTOs are API contracts. Do not expose database entities from Controller.
- SQL lives in MyBatis XML mappers. Use `#{}` binding, never `${}` for user input.
## Security
- Validate all request body, path and query parameters.
- Keep authorization checks on service APIs or controller endpoints.
- Do not log secrets, tokens, full request bodies, phone numbers, emails or payment data.
- User-facing errors should be generic; detailed errors go to safe structured logs.
## Before Finishing
Run:
```bash
./scripts/agent-check.sh
```
If any check fails, fix the issue before asking for human review.
这段文字的作用不是"教育 AI 要做个好人",而是把团队最在意的约束前置。尤其是分层、SQL、安全和日志,这些地方一旦错了,review 时再骂 agent 也没用。
2. Feedback:给 agent 一个能跑的检查脚本
再配一个 scripts/agent-check.sh,让 agent 每次改完都知道该跑什么。
#!/usr/bin/env bash
set -euo pipefail
./mvnw -q test
./mvnw -q checkstyle:check
./mvnw -q spotbugs:check
如果项目没有 checkstyle 或 spotbugs 插件,就换成已有的命令。重点不是工具名字,而是把"请自行验证"变成一条确定可执行的路径。否则 agent 很容易写一句"建议运行测试",然后心安理得地收工。
3. Architecture Fitness:用 ArchUnit 防止分层漂移
分层规则不能只写在文档里,最好变成测试。比如用 ArchUnit 写一条边界检查:
package com.example.order.architecture;
import com.tngtech.archunit.core.domain.JavaClasses;
import com.tngtech.archunit.core.importer.ClassFileImporter;
import org.junit.jupiter.api.Test;
import static com.tngtech.archunit.library.Architectures.layeredArchitecture;
class LayeringTest {
@Test
void controller_should_not_access_mapper_directly() {
JavaClasses classes = new ClassFileImporter()
.importPackages("com.example.order");
layeredArchitecture()
.consideringAllDependencies()
.layer("Controller").definedBy("..controller..")
.layer("Service").definedBy("..service..")
.layer("Mapper").definedBy("..mapper..")
.whereLayer("Controller").mayNotBeAccessedByAnyLayer()
.whereLayer("Service").mayOnlyBeAccessedByLayers("Controller")
.whereLayer("Mapper").mayOnlyBeAccessedByLayers("Service")
.check(classes);
}
}
这类测试的好处是直接。agent 如果在 Controller 里偷懒调用 Mapper,测试立刻红。它不用等到人工 review 才知道"我们这里不这么写"。
4. Behaviour Harness:用 fixture 固化关键行为
行为正确性最难,尤其不能完全相信 agent 自己写的测试。一个实用办法是:关键输入输出由人先给 approved fixture,agent 可以写实现和补测试,但不能随便改 fixture。
比如 src/test/resources/fixtures/order-create-success.json:
{
"request": {
"customerId": "CUST-10001",
"items": [
{ "sku": "BOOK-001", "quantity": 2 }
]
},
"expectedResponse": {
"status": "CREATED",
"totalQuantity": 2
}
}
然后在测试说明里写清楚:
- fixture 是人类确认过的验收样例,agent 不得为了让测试通过而修改它;
- 新增行为可以新增 fixture,但要说明业务含义;
- 修改 fixture 必须在 PR 描述里单独解释。
这听起来有点啰嗦,可是很有必要。否则 agent 有时会走一条很"聪明"的捷径:实现不对,就改测试;测试还不对,就改期望值。代码绿了,需求黄了。
5. PR/MR 前的 Harness Gate
最后,把这些检查放进流水线:
| Gate | 目的 | 失败后谁处理 |
|---|---|---|
mvn test |
验证单元测试和架构测试 | agent 先修 |
checkstyle / spotbugs |
抓风格、空指针、资源释放等问题 | agent 先修 |
| dependency / secret scan | 抓依赖漏洞和误提交密钥 | 人和 agent 一起看 |
| AI Review | 看是否过度设计、误解需求、测试自嗨 | 人类 reviewer 复核 |
| 人工 Review | 做最终语义判断和业务取舍 | 人负责 |
这就是一个 Java Web 项目的小型 harness。它不神奇,但足够实用:事前有规则,事后有检查,中间有测试,最后有人把关。
一句话:让 agent 写代码之前,先给它修一条能回家的路。
总结
这篇文章的价值,不在于发明了一个新名词,而在于给我们一个更稳的思考框架。
LLM 是发动机,但 coding agent 能不能开得稳,还要看底盘、刹车、仪表盘、车道线和驾驶规则。Harness engineering 做的就是这些事情:把模型外面的环境、约束、反馈和验证做扎实。
AI 不只是 LLM 和 NLP。到了 coding agent 这里,AI 更像一套社会技术系统:模型、工具、流程、测试、规范和人类判断,缺一不可。
最后一句不中听但有用的话:如果一个团队平时连 CI、测试、架构边界都维护不好,把 agent 接进来以后,它不会自动变成工程文明,最多变成一个更勤快的混乱放大器。
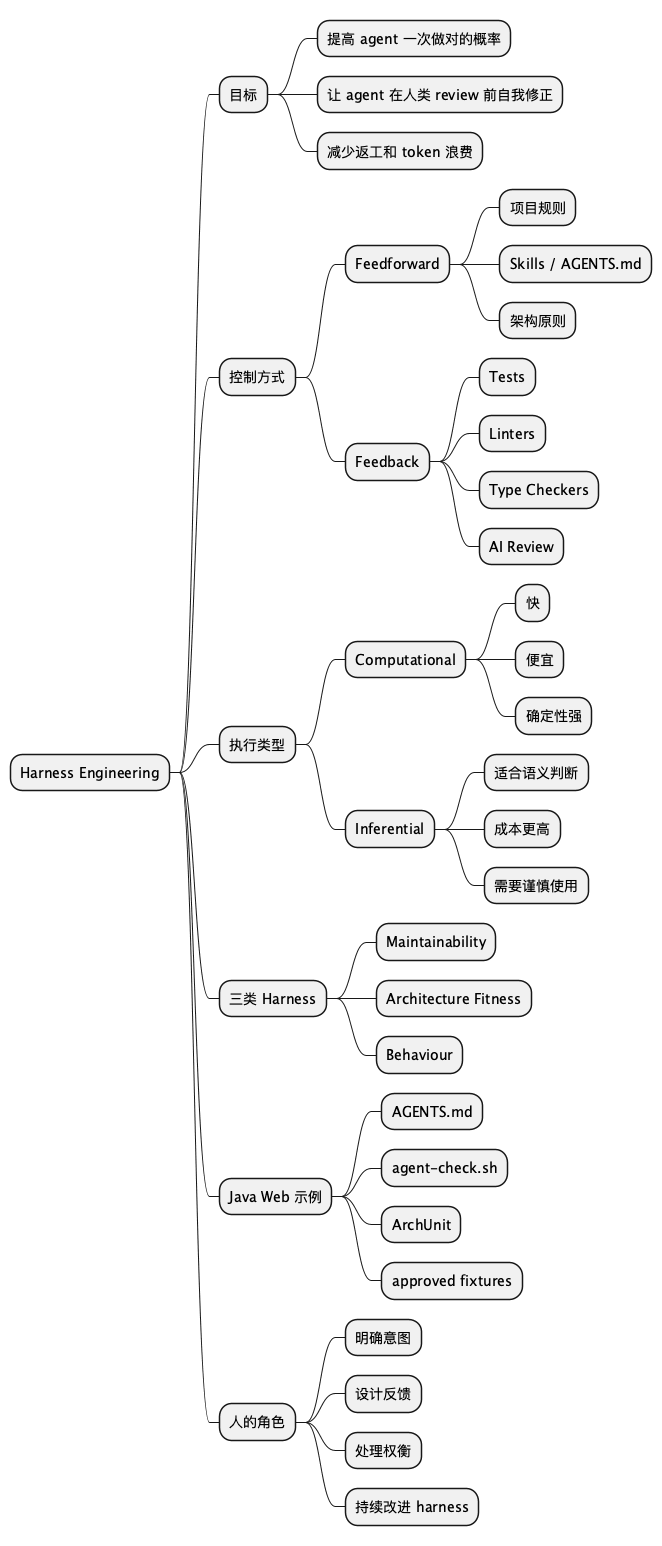
思维导图
@startmindmap
* Harness Engineering
** 目标
*** 提高 agent 一次做对的概率
*** 让 agent 在人类 review 前自我修正
*** 减少返工和 token 浪费
** 控制方式
*** Feedforward
**** 项目规则
**** Skills / AGENTS.md
**** 架构原则
*** Feedback
**** Tests
**** Linters
**** Type Checkers
**** AI Review
** 执行类型
*** Computational
**** 快
**** 便宜
**** 确定性强
*** Inferential
**** 适合语义判断
**** 成本更高
**** 需要谨慎使用
** 三类 Harness
*** Maintainability
*** Architecture Fitness
*** Behaviour
** Java Web 示例
*** AGENTS.md
*** agent-check.sh
*** ArchUnit
*** approved fixtures
** 人的角色
*** 明确意图
*** 设计反馈
*** 处理权衡
*** 持续改进 harness
@endmindmap
明天可以做的 5 件小事
- 给当前项目补一份
AGENTS.md或等价的项目工作说明。 - 把 agent 经常犯的三个错误写下来,分别判断是缺 feedforward,还是缺 feedback。
- 把最便宜的检查前移,比如 format、lint、type check、快速单测。
- 给关键架构边界加一条自动化检查,不要只靠 code review 记忆。
- 挑一个功能点试试"人写验收样例,agent 写实现和测试,人再抽查"的工作流。
扩展阅读
- Harness engineering for coding agent users,Martin Fowler 网站上的原文。
- The Anatomy of an Agent Harness,LangChain 对
Agent = Model + Harness的解释。 - Effective harnesses for long-running agents,Anthropic 关于长任务 agent harness 的实践。
- Harness engineering,OpenAI 关于 harness 的工程实践。
- Continuous Integration,理解"把反馈前移"的经典背景。
- Architectural fitness function,架构约束如何自动化验证。
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。