驾驭 AI 工程的一些最佳实践:从 Meta-Harness 论文到可落地的工程手册
Posted on 二 21 4月 2026 in Journal
| Abstract | 驾驭 AI 工程的一些最佳实践:从 Meta-Harness 论文到可落地的工程手册 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-04-21 |
| License | CC-BY-NC-ND 4.0 |
驾驭 AI 工程的一些最佳实践:从 Meta-Harness 论文到可落地的工程手册
短大纲
- 为什么换模型,常常治不好 AI 工程里的老毛病
Meta-Harness论文到底讲了什么- 六条真正能落地的 AI 工程实践
- 从“手工 harness”到“可搜索 harness”的技术栈
- 一条不靠玄学、靠数据和回路的路线图
一、先说结论:AI 系统翻车,很多时候不是模型不够强
很多人一看到 AI 结果不对,第一反应就是换模型。今天换个更大的,明天换个更便宜的,后天再换个“更会写代码”的。折腾一圈下来,错误模式居然还挺稳定:忘上下文、跑偏、输出不成型、测试没跑、重复犯同样的错。
这就像你们部门项目延期了,先把会议室换成带落地窗的。采光是变好了,进度通常不会因此自动感人。
我现在越来越相信一句话:
AI 系统的表现,往往不只取决于 model weights,更取决于 harness。
这里的 harness,不是一个新瓶装旧酒的时髦词。它指的是包在模型外面的那层代码和规则:决定存什么、取什么、怎么展示给模型、什么时候调用工具、什么时候算完成的整套机制。
很多团队把注意力全投在模型上,却把 harness 当成“顺手写一下的胶水层”。这就有点像把发动机当神仙,把刹车、变速箱和方向盘当装修。车当然还是车,但你敢不敢上高速,就是另一回事了。
二、Meta-Harness 论文到底讲了什么
最近我读到一篇很有意思的论文:Meta-Harness: End-to-End Optimization of Model Harnesses。这篇论文给我的冲击,不在于又提出了一个新 benchmark,而在于它把一个很多工程团队隐约知道、却没认真面对的事实捅明了:
同一个模型,外面的 harness 改一改,性能差距可以非常大。
论文里甚至引用了一个很扎眼的现象:在相同模型上,只是换 harness,某些 benchmark 上能出现 6 倍 的性能差距。这就很说明问题了。很多时候你以为你在测“模型能力”,其实你测到的是“系统外壳设计得怎么样”。
2.1 什么叫 harness
用人话说,harness 就是 LLM 系统真正上班时穿的那套工装。
它至少包括这些东西:
- prompt 怎么构造;
- 记忆存在哪里;
- 检索拿什么、怎么排;
- 工具怎么暴露给模型;
- 状态怎么更新;
- 什么时候继续尝试,什么时候停;
- 结果怎么打分,失败日志怎么记。
也就是说,harness 不是一句 system prompt,而是一段可执行的过程代码。
2.2 论文真正有意思的点:优化的对象,从提示词变成了 harness 代码
以前很多“优化 prompt / text”的方法,本质上都比较短视。它们常常只看:
- 当前候选;
- 一个分数;
- 一小段反馈摘要;
- 或者最近几轮的窗口。
这对简单问题也许够了,但对 harness 不太够。因为 harness 的坏,往往是长链条的。某个记忆策略写错了,表面上出问题的可能是第 7 步;某个 tool definition 太含糊,真正炸出来也许在第 12 个动作。你只看一个 aggregate score,等于拿体温计去修变速箱。
Meta-Harness 的核心做法非常工程化:
- 有一个 outer loop;
- 每轮让一个 coding agent proposer 去读历史;
- 历史不是摘要,而是一个文件系统,里面存着之前所有候选 harness 的源码、分数、执行轨迹和日志;
- proposer 自己决定读哪些文件,分析哪些失败模式,提出新的 harness;
- 新 harness 被评测后,结果再写回文件系统,进入下一轮。
这和很多只喂一段总结 prompt 的方法不一样。项目页里给了个很夸张但很有说服力的数据:Meta-Harness 每一步可以利用的诊断上下文可达 10M tokens 量级,而作者调研的先前方法最多大约 26K。这不是“小幅优化”,这是从“看片头摘要”切换到了“可以调原始监控和日志”。
2.3 把它翻成一个可实现的 outer loop
如果把论文里的方法翻成一张更适合工程团队照着实现的图,大概会长这样:
@startuml
title Meta-Harness 风格 Outer Loop
skinparam backgroundColor white
skinparam shadowing false
skinparam roundcorner 12
skinparam activity {
BackgroundColor #F8FBFF
BorderColor #4C78A8
DiamondBackgroundColor #FFF8E8
DiamondBorderColor #C28F2C
ArrowColor #4C78A8
}
start
:准备 seed harnesses\n(人工 baseline / 历史版本);
:在 search set 上评估 harness;
:归档到 filesystem archive\n源码 + 分数 + 执行轨迹 + 失败日志;
:coding agent proposer 读取历史\n选择要看的 harness / log / trace;
:诊断失败模式\n提出新 harness;
if (接口校验 / 约束检查通过?) then (yes)
:评估新 harness;
:更新 archive 与 Pareto frontier;
else (no)
:记录无效候选与失败原因;
endif
if (达到预算 / 收敛 / 人工停止?) then (yes)
:输出最优 harness\n或 Pareto frontier;
stop
else (no)
:进入下一轮 outer loop;
endif
@enduml
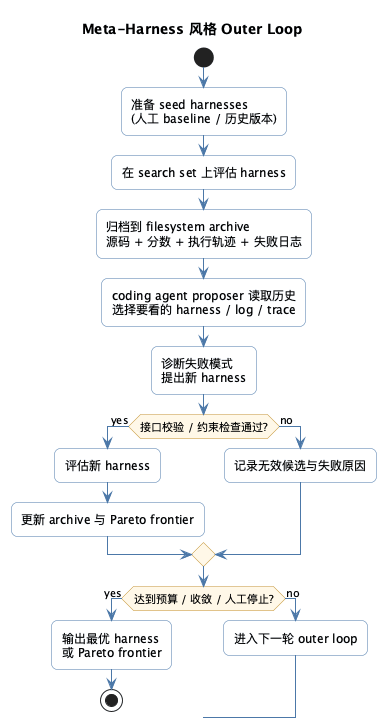
把这张图映射到真实工程里,其实没有想象中那么玄:
seed harnesses就是你当前已有的 baseline,比如几版 prompt、几套 memory 策略、几种 tool orchestration 写法。filesystem archive不是神秘组件,本质上就是一个有组织的实验归档目录,里面至少放源码、评估分数、trace、失败样本。coding agent proposer可以是 Claude Code、Codex 这类 coding agent,它的关键能力不是“文采好”,而是会读日志、会改代码、会做差异分析。接口校验 / 约束检查很重要,它避免 proposer 每轮都把系统改坏。比如只允许修改指定目录、必须保留统一入口函数、必须通过 schema 校验。Pareto frontier也很实用,因为现实里你不一定只优化一个指标。成功率、token 成本、耗时,往往都得一起看。
这也是为什么我觉得这篇论文特别像“工程论文”,而不只是“模型论文”。它讨论的不是怎样再发明一个更华丽的推理链,而是怎样把候选代码、评估、日志、搜索接成一个闭环。
2.4 它为什么有效
我觉得这篇论文最值钱的一点,是它把 credit assignment 这件事做对了。
很多系统只会告诉你:“这一轮分数低了。”
Meta-Harness 尝试回答的是另外一个问题:
到底是哪一段 harness 决策,让后面的行为越来越歪?
这就从“打分”变成了“诊断”。
论文里 proposer 会去看 prior candidates 的源码、prompt、tool call、错误日志、执行轨迹,再做有针对性的修改。不是乱变异,不是碰运气式 evolutionary magic,而是更像一个会读日志、会查代码、会做差异分析的工程师。
换句话说,它优化的不只是结果,而是导致结果的那层过程代码。
2.5 结果怎么样
论文给出的结果挺能打,而且跨了三个不同任务域:
- 在线文本分类:比当时的 context management baseline 提升 7.7 个点,同时使用 4 倍更少 的上下文 token;
- 检索增强数学推理:在 200 道 IMO 级问题上,跨 5 个 held-out model,平均提升 4.7 个点;
- Agentic Coding:发现出来的 harness 超过了手工设计 baseline,在
TerminalBench-2上表现更强。
项目页还给了更直观的终端代理成绩:在 Claude Haiku 4.5 上,Meta-Harness 版本达到 37.6%,排名第一;在 Claude Opus 4.6 上达到 76.4%,也明显强于几个很能打的 hand-engineered baseline。
这不意味着“人类工程师可以提前下班了”。但它非常清楚地说明了一点:
你不一定要先升级模型,也可以先升级 harness。
2.6 两家大厂的同一个工程判断
这套想法不只是学术圈在讲。OpenAI 和 Anthropic 最近都给出了类似的工程判断,而且都有真实数据撑腰。
OpenAI:Harness engineering: leveraging Codex in an agent-first world(2026-02-11)
这篇文章描述了他们内部用 Codex 做一个真实软件产品的实验:3 名工程师,零行手写代码,5 个月内跑出约 100 万行代码,合出约 1500 个 PR,平均每人每天 3.5 个 PR,后来团队扩到 7 人,吞吐量还在增加。
他们踩过的坑和论文说的几乎一样:早期进展比预期慢,不是因为 Codex 不行,而是"环境欠规范"——工具不够、抽象层没建好、结构没定义清楚。工程师的核心工作从"写代码"变成了"设计环境、定义意图、建反馈回路"。
关于 AGENTS.md,他们也交过一次学费。一开始用一个大文件写所有规则,结果很快失败了:
- 上下文被占满,真正的任务反而挤不进去;
- "所有事都重要"等于"没有事重要",agent 开始乱猜;
- 文件腐烂极快,很快变成一堆没人维护的旧规则,agent 也分不清哪条还有效。
后来他们改成:AGENTS.md 只做目录(约 100 行),真正的知识放在 docs/ 下的结构化目录里,包含设计文档、架构图、质量评分、可靠性记录等,让 agent 自己按需去读。
有一句话值得记住:
当 agent 出错时,答案几乎从来不是"再试一次"。而是要问:缺少什么能力,怎么让这个能力既对 agent 可见、又可强制执行?
Anthropic:Building agents with the Claude Agent SDK(2025-09-29)
Anthropic 把 Claude Code 背后的 harness 架构抽出来做成了 SDK,并给出了他们的四层模型:
| 层 | 作用 |
|---|---|
CLAUDE.md |
跨会话记忆:技术栈、规范、禁区、架构索引;是地图,不是手册 |
Skills |
高频流程的自动化封装 |
Hooks |
事件驱动的确定性执行门禁 |
Subagents |
隔离并行的专项执行环境 |
他们对 Subagents 给出了两个核心理由:一是并行化,多个 subagent 同时处理不同任务;二是上下文隔离,subagent 用自己的 context window,只把有用的结果回传给 orchestrator,不把整段历史塞回来。
Anthropic 的设计原则一句话说清:给 agent 一台电脑(终端权限 + 文件读写 + 工具调用),让它能像工程师一样工作,而不只是回答问题。他们的 agent 主循环基本就是:收集上下文 → 执行动作 → 验证结果 → 重复。
两篇文章传递的底层判断是一样的:
瓶颈不是模型能力,是模型工作的基础设施。
三、把论文翻译成工程语言:别只优化模型,要优化“模型周围的系统”
如果把 Meta-Harness 的思想翻译成日常工程语言,我会说成这样:
别把 AI 的问题都归咎给模型。很多问题,其实出在模型外面的那一层工程设计。
这层工程设计,在我们手里通常长这样:
AGENTS.md/CLAUDE.mdmemory.md/tasks.md- skills / SOP / commands / rules
- prompt 组装逻辑
- tool schema
- completion check
- verifier
- 回放日志
- 评估数据集
它们加在一起,就是你的 harness。
所以,AI 工程真正该建设的,不只是“更好的 prompt”,而是下面这六层东西:
- 项目手册层:AI 先知道这是什么项目;
- 外化记忆层:坑要写下来,不要指望模型自己“悟”;
- 流程技能层:高频动作要模板化,不靠临场发挥;
- 协议层:输入输出要结构化;
- 门禁层:不合格结果不能带着病继续往后流;
- 改进层:日志、分数、trace 要回流,进入下一轮 PDCA。
这就是我下面要讲的六条实践。
四、六条最佳实践
1. 让 AGENTS.md 或 CLAUDE.md 成为项目开发的简明手册
Meta-Harness 让我更坚定地觉得,AGENTS.md / CLAUDE.md 不是“给 AI 的便签”,而是 harness 的第一层。
它要做的事,不是写很多,而是写对:
- 这个项目是什么;
- 关键目录和边界在哪;
- 哪些规则必须遵守;
- 哪些文件是危险区;
- 哪些知识库、skill、memory 值得继续读。
我更愿意把它看成 AI 的“项目引导页”。像机场指示牌,不是把整座城市塞进去,而是告诉你:出关往哪走、登机口在哪、别误入员工通道。
一个好用的结构通常包括:
Architecture:系统结构、模块边界、关键依赖;Conventions:命名、测试、提交流程、禁区;Commands:最常用的 build / test / lint / debug;Index:知识库、memory、skills、tasks、decision log 的入口。
这层的目标只有一个:减少 AI 每次开工前的迷路成本。
2. 别让 AI 记太多,把记忆外化成文件
Meta-Harness 的一个核心洞察是:丰富的 prior experience 值钱,但前提是它得可访问、可检索、可诊断。
这对我们平时用 AI 写代码也一样。
别把所有知识都寄托在会话上下文里。会话是缓存,不是档案馆。一个 session 里你们聊得再热火朝天,关掉窗口以后,它大概率还是会像昨晚没睡醒一样看着你。
所以要外化。
我推荐最小配置是:
soul.md:长期原则,比如“默认最小修改”“别在没验证前宣称完成”;memory.md:稳定、可复用的项目 learnings;tasks.md:当前任务、下一步、阻塞项;decisions/*.md:设计取舍和原因。
这里最关键的一点,不是“多”,而是“可用”。
memory.md 只收两类东西:
- 下次大概率还会遇到;
- 下次遇到时,能帮你少走一段弯路。
否则它很快就会长成一片热带雨林。AI 还没开始解决问题,先被你自己的历史碎片绊了一跤。
3. 别让 AI 临时想,给它准备好 skills、SOP、commands、rules
Meta-Harness 优化的不是一句话,而是一整段可执行逻辑。这对我们也有启发:
高频任务不要靠即兴发挥,要靠预制工作流。
最适合沉淀成 skill 的任务,通常都有这几个特点:
- 高频;
- 步骤相对固定;
- 错误模式重复;
- 验证路径明确。
比如:
- 新建接口 / 页面;
- 修 bug;
- 写测试;
- 做 code review;
- 提交 PR;
- 生成图表;
- 排查日志;
- 同步设计文档。
一个好 skill 至少要写清楚:
- 什么时候触发;
- 任务目标是什么;
- 典型步骤是什么;
- 哪些反模式禁止;
- 结束前必须验证什么。
这件事看着土,其实很高级。真正能把系统做稳的,常常不是“灵光一现”,而是 SOP。医院手术靠 checklist,不靠主刀当天突然有感觉;AI 工程同理。
4. 给 AI 定协议:人和 AI、AI 和 AI,都按协议说话
没有协议,协作很容易退化成两种东西:
- 人给 AI 的,是“情绪化需求”;
- AI 回给人的,是“文学化结果”。
两边都很热闹,中间却没法交付。
所以我强烈建议给协作定协议。
人对 AI 的输入协议
最小输入最好包含:
goal: 要解决什么问题
context: 相关背景、文件、链接
constraints: 不能做什么 / 必须满足什么
definition_of_done: 什么算完成
verification: 需要跑哪些检查
AI 对人的输出协议
最小输出最好包含:
summary: 做了什么
assumptions: 基于什么假设
changes: 改了哪些文件 / 配置 / 数据
risks: 还有哪些风险
verification: 跑了什么,结果如何
next_step: 建议下一步做什么
AI 与 AI 的协议
一旦进入多 agent 场景,协议更不能偷懒。至少要统一:
- 输入 schema;
- 状态字段;
- 允许工具范围;
- 产出格式;
- 失败回退策略。
不然多 agent 协作很容易演变成“多线程甩锅系统”。
5. 给输入和输出立规矩,不合格就立刻打回,并留下 trace
这一条和 Meta-Harness 最像。
论文为什么能优化 harness?因为每一轮不是只留下一个分数,而是留下源码、分数、执行轨迹和日志。这样下一轮才能诊断。
所以你平时和 AI 协作,也不能只说“这次不太行,再来一次”。要把失败留下证据。
比如:
- 输入不带
Definition of Done,先补齐; - 输出没有
verification,直接打回; - 说“已完成”但没证据,判定为未完成;
- 引用了链接但没验证可达,要求替换;
- 改动超授权范围,要求回滚;
- 每次失败都要记录触发条件、错误输出、修复动作和结果。
这一条的本质就是:
别奖励不合格的中间结果,也别浪费不合格结果带来的诊断价值。
你把失败当噪声,它就只会重复;你把失败当 trace,它才有机会变成系统学习的原料。
6. AI 编程也要遵循 PDCA:Planner, Doer, Checker, Actor
很多团队的问题,不是不会让 AI 干活,而是只做到 PD C 的前三步,最后那个 A 总是省掉。
我会把 AI 编程流程拆成四个角色:
Planner:拆任务、澄清约束、给方案和取舍;Doer:实施改动;Checker:验证结果、做 review、找回归;Actor:根据验证和 trace,更新 rule、memory、skill 和 harness。
这里面最容易被跳过的,偏偏就是最值钱的 Actor。
因为没有这一步,整个系统就永远在“会做题,但不长记性”的循环里。
有了这一步,失败才会变成资产,规则才会越来越像规则,而不是聊天时的灵感碎片。
所以 PDCA 在 AI 时代不是老古董,反而更像一个元 harness。
五、实际落地的技术栈:先把 harness 做成系统,再谈自动优化
如果你问我,怎么把这套东西真正落到工程里,我会建议按投入分三档。
Tier A:先把“手工 harness”搭起来
这一档最适合个人和小团队,目标不是炫技,而是先让系统有骨架。
| 能力层 | 选型建议 |
|---|---|
| 项目手册 | AGENTS.md / CLAUDE.md |
| 外化记忆 | soul.md、memory.md、tasks.md、decisions/ |
| 工作流 | skills/、commands/、rules/ |
| 协议 | YAML / Markdown 模板,固定输入输出 schema |
| 执行环境 | Cursor / Claude Code / Codex 任一即可 |
| 验证 | pytest、npm test、lint、格式化、构建检查 |
这一档的目标很简单:先把随机发挥压缩成可重复动作。
Tier B:把“评估、日志、trace”接进 harness
这时你的重点从“写规则”变成“让规则可观测”。
| 能力层 | 选型建议 |
|---|---|
| Harness 实现 | Python / TypeScript 单文件或小模块化程序 |
| 版本管理 | Git + 命名清晰的 harness 目录 |
| 评估集 | 小样本真实任务回放集、回归 case 集 |
| 轨迹记录 | JSONL、SQLite、Postgres、对象存储均可 |
| 观测 | OpenTelemetry、Langfuse、Phoenix 或自建 trace viewer |
| 指标 | 成功率、返工率、上下文 token、耗时、失败类型分布 |
这一档最关键的不是工具多高级,而是你能回答:
- 这次为什么失败;
- 是检索错、协议错、工具错,还是 verifier 错;
- 哪一种 harness 设计更稳。
没有 trace,就没有 credit assignment。没有 credit assignment,优化就只剩拍脑袋。
Tier C:做成 Meta-Harness 风格的 outer loop
当你已经有可运行 harness、可回放评估、可归档日志,再考虑自动搜索。
| 能力层 | 选型建议 |
|---|---|
| Proposer | Claude Code / Codex 这类 coding agent |
| 搜索对象 | prompt、memory 策略、retrieval 逻辑、tool schema、completion check |
| 历史存储 | 文件系统归档:源码、分数、执行轨迹、失败日志 |
| 约束 | 接口校验、只允许改指定目录、测试集隔离 |
| 评估 | 搜索集与最终测试集分离,支持 Pareto frontier |
| 基础设施 | 容器化任务、批量 runner、统一日志规范 |
这档最迷人的地方,不是“自动”,而是它终于让 harness engineering 从手艺活变成半工程化的搜索问题。
但我还是那句老话:先把 trace 记清楚,再谈 agent 自动搜索。
六、一条现实点的路线图:按阶段推进,不要按周末许愿
Phase 0:一周内,先把地基打平
先做五件事:
- 写好
AGENTS.md/CLAUDE.md; - 建
memory.md和tasks.md; - 选 5 个最高频任务,开始做 skill;
- 定一版输入 / 输出协议模板;
- 把“完成必须附验证证据”写进规则。
这时先盯两个指标:
- 首轮输出被打回的比例;
- 同类错误一周内是否重复。
Phase 1:一个月内,把高频任务流程化,并留下执行痕迹
交付物建议包括:
- 10 个左右高频 skills;
- 一套 code review / bugfix / test / PR 协议;
- CI 中可跑的 lint / test / build 门禁;
- 一个最小 trace archive,用来保存失败与成功样本。
这一步做完,AI 不一定更聪明,但会更像“熟悉你们项目规矩的人”。
Phase 2:一到两个季度,把 harness 做成可评估对象
这阶段开始建立实验能力:
- 为不同 harness 版本命名;
- 用固定任务集回放;
- 记录 token、耗时、成功率和失败类型;
- 做简单的 A/B 对比;
- 让 verifier 与 trace viewer 稳定可用。
这时你才真正拥有了“优化 harness”的资格。
Phase 3:有证据再引入自动 proposer
当你已经能稳定回答下面这些问题时,再考虑引入 Meta-Harness 风格的自动搜索:
- 哪类任务最常失败?
- 哪些失败是由 memory / retrieval / prompt orchestration 引起的?
- 当前人工改 harness 的收益,是否已经遇到瓶颈?
- 自动 proposer 带来的评估成本,值不值?
如果这些问题答不出来,就别急着上 evolutionary loop。很多团队不是缺 optimizer,是缺账本。
七、一个最小可用的协作模板
如果你想明天就开始,不用等系统完美,先用下面这个模板。
任务输入模板
## Goal
要解决的问题是什么?
## Context
相关文件、链接、背景、已有结论
## Constraints
不能改什么?必须遵守什么?
## Definition of Done
什么算完成?
## Verification
需要哪些测试、检查或证据?
任务输出模板
## Summary
## Plan or Changes
## Risks / Assumptions
## Verification
## Next Step
如果你愿意再进一小步,可以再加一栏:
## Trace Notes
这次失败 / 修复最关键的证据是什么?
这一栏很朴素,但它往往是下一轮优化最值钱的燃料。
八、总结
我想让你带走的,不是一个新名词,而是下面这几个判断:
Meta-Harness真正提醒我们的,是 AI 系统性能取决于 harness,不只取决于模型;- 多数团队短期最值得做的,不是先换模型,而是把 项目手册、外化记忆、skills、协议、质量门禁和 trace 建起来;
AGENTS.md/CLAUDE.md不是装饰文件,而是 harness 的入口层;memory.md不是聊天记录备份,而是可复用经验的索引;PDCA不只是管理方法,它其实就是 harness 持续优化的闭环。
说到底,AI 工程不是在比谁先拿到下一个模型,而是在比谁先把模型周围那一圈系统,做成可诊断、可验证、可进化的工程。
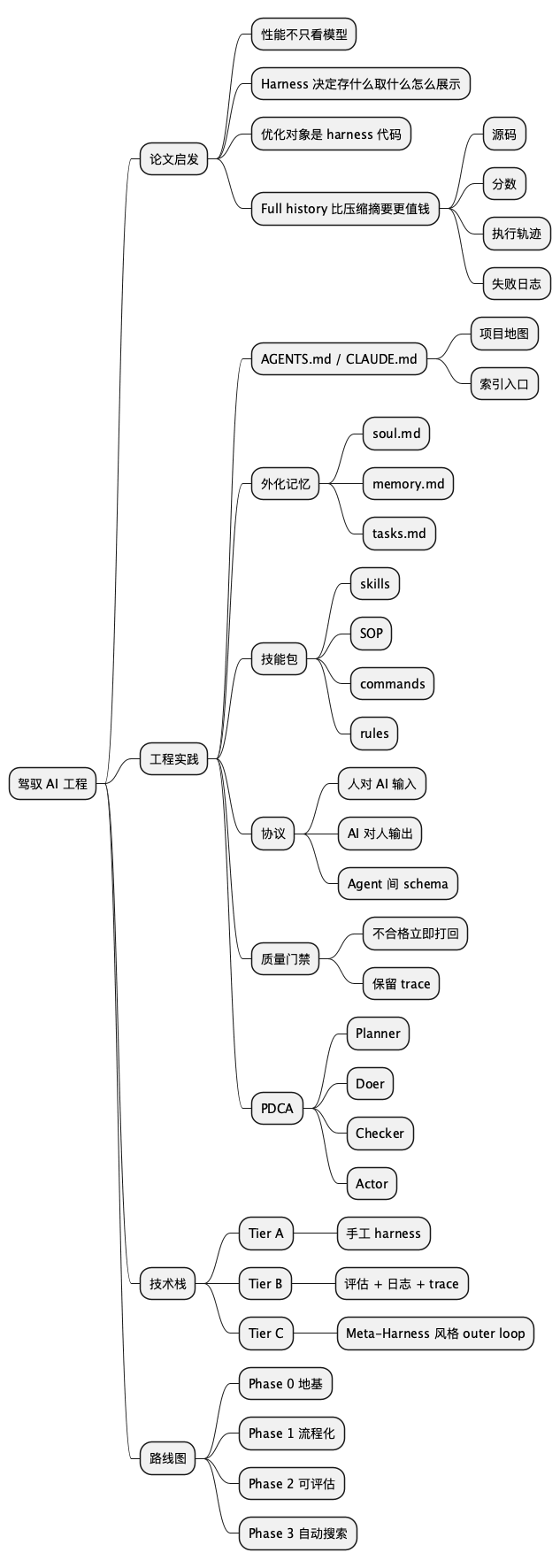
下面这张图,是我对这篇文章的一个压缩版总结。
@startmindmap
* 驾驭 AI 工程
** 论文启发
*** 性能不只看模型
*** Harness 决定存什么取什么怎么展示
*** 优化对象是 harness 代码
*** Full history 比压缩摘要更值钱
**** 源码
**** 分数
**** 执行轨迹
**** 失败日志
** 工程实践
*** AGENTS.md / CLAUDE.md
**** 项目地图
**** 索引入口
*** 外化记忆
**** soul.md
**** memory.md
**** tasks.md
*** 技能包
**** skills
**** SOP
**** commands
**** rules
*** 协议
**** 人对 AI 输入
**** AI 对人输出
**** Agent 间 schema
*** 质量门禁
**** 不合格立即打回
**** 保留 trace
*** PDCA
**** Planner
**** Doer
**** Checker
**** Actor
** 技术栈
*** Tier A
**** 手工 harness
*** Tier B
**** 评估 + 日志 + trace
*** Tier C
**** Meta-Harness 风格 outer loop
** 路线图
*** Phase 0 地基
*** Phase 1 流程化
*** Phase 2 可评估
*** Phase 3 自动搜索
@endmindmap
扩展阅读
论文
-
Meta-Harness: End-to-End Optimization of Model Harnesses(项目页)
本文的主要参考。提出用 coding agent 作为 outer loop proposer,利用历史源码、分数和执行轨迹来自动搜索更好的 harness,在文本分类、数学推理、代码 agent 三个任务上都跑出了大幅提升。 -
Natural-Language Agent Harnesses (NLAHs)
把 harness 逻辑外化成可移植的自然语言制品(natural-language executable artifacts),通过 Intelligent Harness Runtime(IHR)解释执行,可在 coding 和 computer-use 两类 benchmark 上做系统性评测和模块消融。思路和 Meta-Harness 互补:一个优化 harness 代码,一个把 harness 本身写成自然语言。 -
VeRO: An Evaluation Harness for Agents to Optimize Agents
专门为"agent 优化 agent"这件事设计的评测 harness,提供版本快照、预算控制、结构化执行轨迹三件套。核心发现:在工具调用类任务上 optimizer 能稳定带来 8-9% 提升,但推理密集型任务收益有限;超过 50% 的修改是 prompt 编辑而非结构改动。如果你在做 agentic 系统的持续改进,这篇值得读。 -
SemaClaw: A Step Towards General-Purpose Personal AI Agents through Harness Engineering
从 prompt engineering 到 harness engineering 的范式转移的工程实现。提出 DAG-based 双阶段混合 agent 团队编排、PermissionBridge 行为安全系统和三层上下文管理架构。关注点不只是性能,还有可控性和可审计性。 -
SWE-bench Goes Live!
SWE-bench 的动态版本,1319 个来自 93 个仓库的真实任务,持续更新以对抗数据污染。引用它是因为它提供了一个很有说服力的数据点:同一个模型换不同 harness,benchmark 分数最大可差 9.5 个点;而换不同 frontier 模型,差距只有 0.8 个点。harness 的影响,比模型选型大一个数量级。
工程文章
-
Harness engineering: leveraging Codex in an agent-first world(OpenAI,2026-02)
OpenAI 内部用 Codex 做真实产品的实验报告:3 人团队,零手写代码,100 万行,3.5 PR/人/天。关于AGENTS.md大文件失败的一手经验尤其值得读。 -
Building agents with the Claude Agent SDK(Anthropic,2025-09)
Anthropic 的四层 harness 模型:CLAUDE.md/Skills/Hooks/Subagents,并给出了 subagents 并行化和上下文隔离的设计细节。 -
Building Effective AI Agents(Anthropic,2024-12)
Anthropic 的 agent 工程入门经典,区分了 workflow(预定义路径)和 agent(模型自主驱动)两种模式,强调从简单开始、只在必要时增加复杂度。适合刚开始做 agent 系统的团队打底子。 -
TerminalBench
面向终端代理的 benchmark,本文引用的 Meta-Harness 在 TerminalBench-2 上的成绩来自这里。 -
CLAUDE.md: Building Persistent Memory for AI Coding Agents
关于如何把CLAUDE.md做成跨会话持久记忆的工程实践。 -
Optimize Any Workflow with Context Engineering: CLAUDE.md + AGENTS.md in Practice
CLAUDE.md和AGENTS.md的落地实践,偏操作手册。
最后留一个问题给你,也留给我自己:当大家都在追更强模型时,你的团队是不是已经认真优化过“模型周围那层代码”?
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。
AI Engineering Context Engineering Meta-Harness Harness Engineering AGENTS CLAUDE PDCA TerminalBench