把文章一键变成播客:我的 side project `lazy-podcast-mate`
Posted on 二 21 4月 2026 in Journal
| Abstract | 把文章一键变成播客:我的 side project lazy-podcast-mate |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-04-21 |
| License | CC-BY-NC-ND 4.0 |
把文章一键变成播客:我的 side project lazy-podcast-mate
短大纲
- 为什么很多文章写完就躺在硬盘里,价值只兑现了一次
lazy-podcast-mate到底解决了什么问题- 从 Markdown 到 MP3,中间这条流水线是怎么跑起来的
- 我在这个小项目里踩过哪些工程坑,又是怎么补上的
- 如果你也想做一个 side project,哪些细节最值得认真做
一、很多文章不是没人看,而是只被消费了一次
写博客这件事,有个很现实的尴尬。
你花了几个晚上查资料、画图、写代码、改措辞,好不容易把一篇文章发出来。发完那一刻像交卷,过两天再看后台,阅读量还凑合,心情也不错。可再过一周,这篇文章大概率就安静地躺进了归档页,像一个认真工作过、但很快下线的老同事。
问题不是内容不值钱,而是内容的复用率太低。
一篇技术文章,本来至少可以有三种活法:
- 在博客里被读;
- 在通勤路上被听;
- 在知识库里继续被检索、被改写、被二次加工。
可现实通常是,它只活成了第一种。剩下两种,要么靠手工,要么干脆就算了。程序员当然最擅长“先算了”,毕竟 backlog 已经够长,不差这一个。
所以我给自己做了一个小项目:lazy-podcast-mate。目标很朴素,也很不朴素。
朴素在于,它只想做一件事:把本地文章一条命令变成可发布的播客 MP3。
不朴素在于,我不想只做一个“能出声音”的玩具,而是想做一个真正能反复用的工程化工具。
项目地址在这里:
- GitHub 仓库:lazy-podcast-mate
- 中文说明:README_zh.md
二、它到底是什么,不是什么
先用一句人话介绍:
lazy-podcast-mate 是一个 CLI 工具。输入是你本地磁盘上的 Markdown / TXT / HTML 文章,输出是带 ID3 标签、背景音乐、淡入淡出、响度校准的 MP3。
它不是:
- 一个在线 SaaS 平台;
- 一个录音软件;
- 一个“点一下就有感情朗读”的黑盒魔法按钮;
- 一个只会把整篇文章生硬朗读出来的文本转语音脚本。
它更像一个小型内容流水线。你把原文交给它,它负责把不适合直接念出来的部分先处理掉,再把文章改写成适合口播的脚本,分块合成语音,最后做后处理,导出一份够像“播客节目”的成品。
也就是说,它的思路不是:
“给文字配个声音。”
而是:
“把文章重新生产成一种适合耳朵消费的内容形态。”
这两句话,看着只差一点,工程上差得可不止一点。
三、为什么我会想做这个项目
我做这个项目,当然有一点“程序员看什么都想写个工具”的职业病。但更主要的,还是几个非常具体的痛点。
1. 长文适合读,不一定适合听
很多技术文章包含代码块、表格、链接、配图,甚至还有命令行输出。它们在屏幕上很好用,一进耳机就开始闹脾气。
比如下面这些内容,直接朗读体验都不太行:
- 一大段 Python 代码;
- 一个很长的 URL;
- Markdown 表格的分隔线;
- “见下图”这种只对眼睛友好的表达。
如果只是把原文扔给普通 TTS,最后得到的东西很像有人认真地把 README 当火车时刻表念给你听。不能说完全没用,只能说非常考验友谊。
2. 真正麻烦的不是生成第一版,而是把它做到“可以发布”
很多 side project 停在第一步:能跑。
可内容产品最烦人的地方恰恰在后面:
- 音量是不是合适;
- 码率够不够;
- 章节衔接会不会突兀;
- 元信息有没有写进去;
- 失败了能不能断点续跑;
- 某个 TTS chunk 挂了以后,是整个任务报废,还是允许宽松继续。
这些东西单看都不性感,合在一起才决定它是不是一个“能长期用”的工具。
3. 我想要的是本地优先、脚本友好、可恢复
我不太想把文章一段段复制到网页里,再手工下载音频、调音量、改文件名、补 shownotes。那种流程不是自动化,是把人肉当编排引擎。
所以这个项目从一开始就定了几个原则:
- 本地文件输入,别折腾拷来拷去;
- CLI 优先,因为命令行最容易进脚本和工作流;
- 断点续跑,因为 LLM 和 TTS 服务总会在你最不想的时候抽风;
- 输出可发布,不是“有个 mp3 就算完”。
四、从 Markdown 到 MP3,这条流水线是怎么设计的
项目的目录结构其实已经把设计思路暴露得很明显了:
lazy_podcast_mate/
ingestion/
cleaning/
script/
chunking/
tts/
post/
output/
orchestrator/
config/
cli.py
它不是一个大脚本里塞三百行 if else 的那种“祖传自动化工具”,而是明确拆成几段责任清晰的流水线。
4.1 流水线总览
@startuml
title lazy-podcast-mate 内容生产流水线
skinparam backgroundColor white
skinparam shadowing false
skinparam roundcorner 12
skinparam activity {
BackgroundColor #F8FBFF
BorderColor #4C78A8
DiamondBackgroundColor #FFF8E8
DiamondBorderColor #C28F2C
ArrowColor #4C78A8
}
start
:读取本地 Markdown / TXT / HTML;
:抽取正文与元数据;
:清洗文本并替换代码块/图片/表格为自然语言占位符;
:调用 LLM 改写成适合口播的脚本;
:按句子边界切分为 TTS chunks;
:调用 TTS provider 逐块合成语音;
:拼接音频并做淡入淡出 / 背景音乐 / loudnorm;
:写入 MP3、ID3 标签与 shownotes;
stop
@enduml
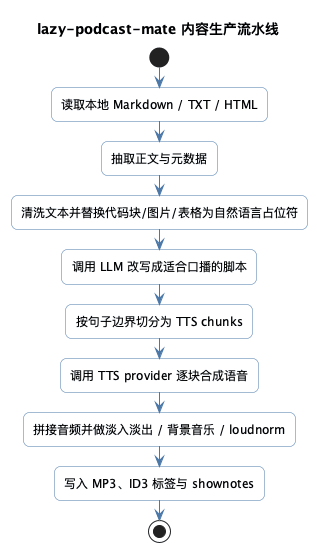
看起来挺顺,其实每一段都各有脾气。
4.2 ingestion 和 cleaning:先把“文章”变成“机器能处理的内容”
第一段工作不是合成语音,而是读懂输入。
项目支持 Markdown / TXT / HTML,这意味着入口不能只假设“用户给的是一个格式完美的博客文件”。它得先把不同来源读进统一的数据结构,再交给后面的步骤。
然后是 cleaning。这一段我觉得特别关键,因为它决定了后面脚本改写的上限。
项目没有把原始代码块、URL、Markdown 表格原样喂给 LLM,而是先替换成更适合口播语境的占位符,比如:
- 代码块 -> “此处有一段 Python 代码示例”
- 图片 -> “配图:某某结构图”
- 表格 -> “表格:比较了 A、B、C 三项”
这一步看上去像小修小补,其实是在做一件很重要的事:
把视觉内容翻译成语义内容。
否则后面不管是 LLM 还是 TTS,都会被这些不适合口播的原始符号拖下水。
4.3 script:不是复读,而是改写
这是整个项目最像“内容生产”而不是“音频处理”的一段。
script 模块会调用 LLM,把文章改写成更适合听的脚本。这里面最重要的不是模型名字,而是 prompt 的目标设定:哪些内容该保留,哪些内容该压缩,哪些内容该用一句自然语言带过。
我很喜欢 README 里这次写得更清楚的一个处理思路:代码、图片、表格和原始 URL 不直接进入口播正文,而是被整理到 shownotes。
而且这不是一句模糊口号。README 现在把默认策略写得很细:从 0.2.0 开始默认启用的 prompt v2,会让旁白只在上下文确实需要时,用一句短短的人话描述这些占位符;否则就安静地略过。你如果想复现更早版本的行为,还可以在 config.yaml 里把 script.prompt_version 切回 v1。
这很像做演讲时的取舍:
- 台上讲“主线”;
- 细节材料放到讲义里;
- 真想深挖的人自己去看附录。
程序员做工具很容易犯一个毛病,叫“全都要”。可播客内容恰恰不能全都要。你把视觉细节、代码原文、长链接全部念出来,信息是完整了,听众也差不多准备取下耳机了。
4.4 chunking 和 tts:音频不是一口气吞下去的
把整篇稿子一次性送给 TTS 往往不现实。长度、失败重试、服务端限制、成本控制,都会逼你做 chunk。
所以这里用了一个比较务实的做法:按句子边界切分。
这样做的好处有三个:
- 失败时容易重试,不用整篇重来;
- 后处理时更容易定位问题 chunk;
- 语音衔接比粗暴按字符数切块自然得多。
README 里提到它支持多种 TTS provider,比如 Volcano、Azure、CosyVoice。这个设计我也很认同,因为真实世界里,没有哪个云服务会永远稳定、永远便宜、永远最适合你。
把 provider 抽象成适配层,不是炫技,而是给未来留退路。
4.5 post 和 output:这才是“能不能发布”的分水岭
如果说前面几段解决的是“生成出来”,那么 post 和 output 解决的就是“拿不拿得出手”。
这里做的事情包括:
- 拼接所有 chunk 音频;
- 做淡入淡出;
- 叠加背景音乐;
- 使用
ffmpeg loudnorm做响度校准; - 导出 320 kbps MP3;
- 写入 ID3 标签;
- 生成配套 shownotes。
这里面我最喜欢的是两个工程细节。
第一,响度校准不是可有可无。
很多技术 demo 到了音频这一步,输出声音能听见就算成功。但真正拿去做播客,响度不稳会非常影响体验。别人节目听着舒服,你的节目忽大忽小,听众切走只需要三秒。
第二,shownotes 是正经产物,不是“以后再说”。
文章里被剥离掉的链接、代码块、图片、表格,没有消失,而是被完整保存在一个 .shownotes.md 文件里。这样既照顾了耳朵,也没牺牲信息密度。
README 这次还补了一个我很认同的工程判断:shownotes 的写入是 best-effort。也就是说,就算 shownotes 生成失败,MP3 仍然应该产出,错误写进日志。这种取舍很成熟,因为它区分了“主产物失败”和“伴生产物失败”。很多工具做不好这件事,最后一个配角出错,把整场演出都拖下台。
顺着这个思路,README 也把运行过程里的中间产物说得更透明了:改写后的脚本、分块音频、运行日志,都会落在 data/runs/<run_id>/。这对排查问题非常重要,因为你终于不用靠猜去理解“它刚才到底卡在哪一步”。
这就是我说它不像一个简单 TTS wrapper 的原因。它已经有一点“内容编排系统”的味道了。
五、这个项目里,我最看重的几个设计取舍
如果让我挑几个最能代表这个项目气质的点,我会选下面这几个。
1. 断点续跑,比一次跑通更重要
README 里有 --run-id 和 --force-stage。这两个参数看着不花哨,但对真实使用非常重要。
因为 LLM 限流、TTS 失败、网络波动,几乎是必然事件。一个真正可用的流水线,不该要求你每次出错都从头烧 token、重跑一遍。
这背后的思路很朴素:
不要把“失败”当异常路径,要把它当常规路径认真设计。
这也是很多 side project 和真正工具的分界线。
2. 严格模式和宽松模式,要把选择权交给用户
有些人希望任何 chunk 出错都立即中止;有些人更在意先得到一个大体可用的结果。于是项目提供了 --lenient 模式。
这个设计的价值不只在功能上,更在产品心态上:
工具不要擅自替用户决定什么叫“可接受失败”。
工程师最怕的不是工具严格,而是工具自作聪明。
3. 让输出带着“节目感”,不是“脚本朗读感”
320 kbps、ID3 标签、BGM、fade、loudness,这些词放在一起,已经很接近播客制作的语境,而不是单纯的 TTS。
这说明项目的目标其实很明确:不是做一份音频缓存,而是尽量让成品接近“可以直接发”的状态。
很多 side project 的问题是目标太虚:好像什么都能做,所以最后什么都做得差一点。
这个项目反而让我觉得它边界感挺清楚:
- 输入聚焦在文章;
- 输出聚焦在节目;
- 中间环节围绕“可发布”而不是“技术炫耀”。
六、如果你第一次上手,最小路径是什么
README 已经把环境和配置写得比较清楚了。如果只说一条最短路径,大概是这样。
6.1 准备环境
你至少需要:
- Python 3.10+
- Poetry
ffmpeg- 一个可用的 LLM API Key
- 一个可用的 TTS API Key
安装方式很直给:
poetry install
cp .env.example .env
然后在 .env 里配置 LLM 和 TTS 提供商,再在 config.yaml 里设置一个合适的 tts.voice_id。
如果你的 LLM 网关在长文章改写时比较慢,建议顺手看看 script.request_timeout_seconds。新版本已经把这件事显式配置化了,长文场景下把它调到 180 或 300 会更稳。
如果你的 OpenAI 兼容网关支持 SSE 流式返回,还可以把 script.stream 设成 true。这样你在跑 --dry-run-script 时,终端会一边吐改写结果,一边把最终脚本写进 checkpoint,调 prompt 的体感会好很多。
6.2 先跑最小 happy path
如果我是第一次试这个项目,我会先用:
poetry run lazy-podcast-mate --input examples/sample.md --dry-run-script
这样先看改写后的脚本是不是顺耳,再决定要不要真正去调 TTS。
确认脚本没问题,再跑:
poetry run lazy-podcast-mate --input examples/sample.md
这比一上来就追求全量产出要稳得多。程序员都知道,先看中间产物,能省掉一半瞎猜。
6.3 直接拿这篇文章做一遍
如果你想看一个“不是 sample,而是真文章”的例子,最简单的办法就是直接拿本文开刀。
假设你的目录结构大致像这样,两个仓库是同级目录:
workspace/
├── lazy-podcast-mate/
└── my-personal-blog/
那么可以这样跑:
cd lazy-podcast-mate
poetry run lazy-podcast-mate \
--input ../my-personal-blog/content/journal/journal_20260421_lazy_podcast_mate.md \
--dry-run-script
这一步我非常建议先做,因为这篇文章里既有代码块,也有两张图,还有不少偏“写给眼睛看”的段落。你先看看改写后的口播脚本顺不顺,再决定要不要真的去烧 TTS 配额。
如果你已经把 config.yaml 里的 script.stream 打开,那么这里会更像“边生成边预览”,比等整篇脚本一次性吐出来更适合调试长文改写。
如果脚本看着没问题,再生成音频:
cd lazy-podcast-mate
poetry run lazy-podcast-mate \
--input ../my-personal-blog/content/journal/journal_20260421_lazy_podcast_mate.md
正常情况下,你会得到两类产物:
data/output/<date>-<slug>.mp3:最终音频文件data/output/<date>-<slug>.shownotes.md:配套 shownotes,里面会保留本文里的链接、代码块、图片和表格
中间过程里的改写脚本、分块音频和运行日志,则会落在:
data/runs/<run_id>/
如果你第一次跑就碰上限流、TTS 超时,别怀疑人生,先怀疑网络和供应商。现在这个项目对“长文改写很慢”的情况也考虑得更周到了,你可以先把 script.request_timeout_seconds 调大一些,再决定是不是要重跑。除此之外,也可以直接用同一个 run-id 续跑,或者在 provider 比较抽风的时候加上宽松模式:
poetry run lazy-podcast-mate \
--input ../my-personal-blog/content/journal/journal_20260421_lazy_podcast_mate.md \
--lenient
这里还有一个挺适合做 demo 的点:这篇文章本身就在介绍 lazy-podcast-mate,所以你最后得到的是一个“工具讲自己”的音频版本,有点像程序员给自己录产品宣传片。多少有点自恋,但也挺完整。
6.4 比较适合谁
我觉得这项目比较适合三类人:
- 有稳定写作习惯,想把文章再利用一遍的人;
- 有内部知识库或课程资料,想批量做音频化内容的人;
- 想练习“LLM + TTS + 内容后处理 + 可恢复流水线”这类完整工程闭环的人。
如果你只是想把一小段文字临时念出来,其实系统自带 TTS、浏览器朗读、甚至手机自带功能可能已经够了。
lazy-podcast-mate 更适合的是“文章级内容生产”,不是一句话朗读。
七、这个 side project 真正练到我的,不是 API 调用,而是产品闭环
做这种项目,最容易沉迷的是“接了多少模型、支持多少 provider、代码写得多优雅”。这些当然都重要,但我现在越来越觉得,一个个人项目最值钱的部分,往往是你愿不愿意把那些不性感的环节补齐。
比如:
- 出错以后怎么恢复;
- 中间产物怎么保存;
- 什么该进正文,什么该进 shownotes;
- 输出质量怎么校验;
- 参数怎么设计得既够用又不烦人;
- 用户第一次上手时最短成功路径是什么。
这些问题没有哪个能让你在朋友圈里显得特别酷,但它们恰好决定了一个项目会不会在两周后还继续被你自己使用。
说得再直白一点:
side project 的成年礼,不是“跑通了”,而是“我愿不愿意下个月还用它”。
lazy-podcast-mate 让我重新确认了一件事:
一个好工具,不只是 Happy Path 顺,Fail Path 也要讲道理。
八、如果你也想做一个像样的 side project,我建议盯住这五件事
这是我从这个项目里总结出来的一份小 CheckList:
-
先把目标用户缩到足够小。
不要一上来就做“所有文本都能转所有音频”。先把“本地技术文章转播客”这一个场景打透。 -
把中间产物当一等公民。
script、chunks、run.log、shownotes这些东西不是调试垃圾,而是系统可恢复、可解释、可迭代的关键。 -
优先处理失败路径。
真正让工具变靠谱的,往往不是第一次成功,而是第三次失败之后还能继续往前走。 -
把“体验指标”写进工程。
响度、码率、淡入淡出、标签信息,这些都不是装饰,它们就是产品质量。 -
别只想着自动化,要想可维护。
provider 会变,模型会变,API 会变。抽象层、配置、日志和检查点,都是给未来的自己留后路。
总结
如果用一句话总结 lazy-podcast-mate,我会这么说:
它不是把文章“读出来”,而是把文章重新生产成一种适合被听的内容。
它最打动我的地方,不是用了 LLM,也不是接了 TTS,而是它把一条常见但零碎的工作流,认真做成了一个能恢复、能校验、能发布的流水线。
很多个人项目死在“能跑就行”。
这个项目想做的,是再往前多走一步:让它值得反复使用。
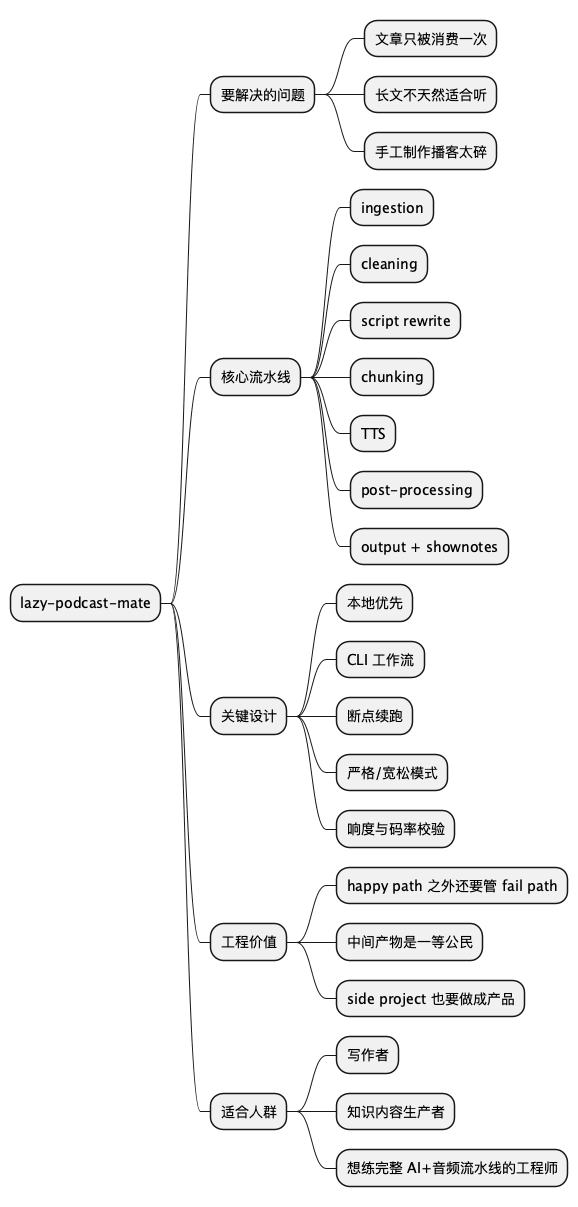
总结思维导图
@startmindmap
* lazy-podcast-mate
** 要解决的问题
*** 文章只被消费一次
*** 长文不天然适合听
*** 手工制作播客太碎
** 核心流水线
*** ingestion
*** cleaning
*** script rewrite
*** chunking
*** TTS
*** post-processing
*** output + shownotes
** 关键设计
*** 本地优先
*** CLI 工作流
*** 断点续跑
*** 严格/宽松模式
*** 响度与码率校验
** 工程价值
*** happy path 之外还要管 fail path
*** 中间产物是一等公民
*** side project 也要做成产品
** 适合人群
*** 写作者
*** 知识内容生产者
*** 想练完整 AI+音频流水线的工程师
@endmindmap
给明天就能做的 4 条建议
- 如果你有一批现成 Markdown 文章,先挑一篇 5 分钟以内能讲完的内容,跑一次
--dry-run-script,先看“口播改写”是不是你想要的。 - 如果你也在做 side project,把“断点恢复”和“中间产物落盘”提前设计进去,别等出问题了再补。
- 如果你的工具最终是给人消费的,尽量把“体验指标”写进代码和校验里,不要只盯功能正确。
- 如果你总想做一个大而全的平台,不妨用用这个项目的思路:收窄场景,做深流程,先让自己愿意反复使用。
扩展阅读
- 项目仓库:lazy-podcast-mate
- 中文说明文档:README_zh.md
ffmpeg官方网站:ffmpeg.org
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。