CGM 论文讲了什么,咱们又该怎么落地
Posted on 二 21 4月 2026 in Journal
| Abstract | Code Graph Model(CGM) 论文解读 + 可落地的技术栈与路线图 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-04-21 |
| License | CC-BY-NC-ND 4.0 |
CGM 论文讲了什么,咱们又该怎么落地
短大纲
- 为什么 "仓库级" 比 HumanEval 难得多: 结构会丢, agent 还容易飘
- CGM 的核心想法: 代码图 + 语义进模型 + 结构进注意力, 而不是把图压成一长段 prompt
- Graph RAG 四件套: Rewriter → Retriever → Reranker → Reader, 它比 Agentless 十步流水线到底省在哪
- 训练的两步在干什么: Graph-to-Code 自监督 + 带噪声的 issue-patch 微调
- 落地技术栈: 从 "直接拉权重" 到 "先抄图和检索" 再到 "真自研 CGM"
- 明天就能做的 CheckList + 扩展阅读
一、先说这篇论文为什么值得看
这两年看 AI 写代码的论文,看多了,容易生出一种错觉: 只要模型够大,agent 会用终端,会跑测试,会自己规划,仓库级问题迟早会被一锅端。真到工程里干活,才知道事情没这么省心。
修一个 repo 级 issue,不是写一道 HumanEval,也不是补一个 LeetCode。它更像在一部长篇小说里改一句台词,前后人物关系、伏笔和语气都不能乱。改对这一句,前面不能塌,后面也不能崩。这才是仓库级任务真正麻烦的地方。
现在行业里常见的路子,一是上 LLM Agent,让它自己调工具、开终端、多轮规划;二是做 RAG,检索一堆代码片段塞进 prompt 里。前一条路很强,可也很容易飘,决策链一长,错一步后面全歪;后一条路看着朴素,可一旦把结构摊平成文本,跨文件关系就糊了。再叠上闭源 API,代码隐私、成本和可定制性,都不是小问题。
arXiv:2505.16901 这篇论文做的事,说白了就是一句话: 让模型不只"读到"代码,还要"看懂"代码之间的关系。 这实在是个对症下药的思路。
1.1 先插一张术语小抄
这一类论文喜欢满天飞术语。第一次读的时候,最容易被这些词绊一下。我先用人话解释一遍:
-
HumanEval
这是代码生成领域很经典的一套题,主要考单个函数会不会写。给模型一个函数签名和题目描述,让它补全代码,再用测试用例判分。你可以把它理解成"AI 写算法题"。 -
MBPP
全称是Mostly Basic Python Problems。它也是代码题 benchmark,不过题目通常更基础,更像 Python 小练习。如果说 HumanEval 像稍正式一点的编程测验,MBPP 就更像入门到中等难度的练习册。 -
SWE-bench
这是更接近真实软件开发的 benchmark。它不是让模型写一个小函数,而是给它一个真实仓库里的 issue,让它去改代码、修 bug,最后跑测试看有没有修对。这个场景就不是"做题"了,更像"进项目干活"。 -
repo-level task
就是"仓库级任务"。不只看一个函数,而是要看整个代码仓库,可能要跨文件、跨模块理解依赖关系。比如改一个 bug,可能要同时看api.py、service.py、test_xxx.py,这就属于 repo-level。 -
issue-patch pair
一个 issue 对应一个 patch。前者是问题描述,后者是修这个问题的代码修改。这类数据特别适合训练"看懂问题,然后改代码"的模型。 -
resolution rate
就是"修复成功率"。比如 100 个问题里修好了 43 个,那 resolution rate 就是43%。
一句话压缩一下:
HumanEval/MBPP: 更像刷题SWE-bench: 更像在真实项目里修 bugrepo-level: 重点不只是"会写代码",而是"知道该看哪、该改哪"
从我的亲身实践来看, 让 AI 写个定义清楚的函数, 它做的很好, 写个类也还可以, 可是让它实现一个跨多模块,跨多文件的大的功能, 我没有看到 AI 能一次做成功的, 它经常改错,给我的信息也经常误导。
二、论文到底做了什么
2.1 仓库先变成一张代码图
Code Graph Model (CGM) 这篇论文先把每个仓库表示成一张有向图 (G=(V,E))。这张图不是拿来摆样子的,它是整个系统的地基。节点最多七类,从 REPO、PACKAGE、FILE 一直细到 FUNCTION 这一级。边大体分两种,很好理解:
- 层级边: 谁包含谁。这个主要靠文件系统和 AST 递归拆出来,根节点是 REPO,往下是 PKG、文本文件,再往下到 CLASS、FUNC 这类实体。
- 引用边: 谁调用谁,谁 import 谁,谁 extends 谁。这个只靠 AST 不够,还得做一点轻量的语义分析,把符号解析到真正的目标节点。
这里有个关键细节: 节点里不只是 id 和类型,还保留了原始代码片段以及行号范围。后处理时,又会把子节点里已经出现过的文本从父节点里剔掉,避免重复。这么一来,它得到的不是一张干巴巴的拓扑图,而是一张真正"带文本"的代码图。
一句话,这篇论文不是把仓库当成一个超长字符串,而是当成一张有结构、有语义的图。差别就在这里。
2.2 语义怎么进模型
节点里的代码和注释如果太长,就按 512 token 切块。每一块先过预训练的 CodeT5+ encoder,再过一个两层 MLP Adapter(GELU),映射到 Qwen2.5 decoder 的 embedding 空间。
这里最妙的一点是: 每个 chunk 最后会被压成 一个 node token。这有点像把一大段代码浓缩成一个语义胶囊。论文把它看作一种 soft prompt compression,这么做的好处也很直接,就是把模型能感知的上下文半径撑大了。长仓库里最怕还没走两步,上下文就塞满了。它这一招,就是在给上下文扩容。
2.3 结构怎么进模型
难点在这里。Transformer 天生擅长吃序列,可代码仓库不是单纯的序列。传统做法往往把检索出来的片段摊平,拼成 prompt,这样语义还在,结构却糊了。
CGM 的解法很直接,也很硬核: 用代码图的邻接关系改写 node token 之间的 attention mask。 谁和谁能互相注意,不再只由顺序决定,还由图上的邻接关系决定。图上挨着的节点可以彼此看见,不相邻的就别东张西望。
这个思路有点像把 GNN 的 message passing 塞进了 LLM 的注意力里。也就是说,图不是挂在外面的检索附件,它真的进了模型的计算过程。整个 encoder、adapter、decoder 再用 LoRA 一起微调。
一句话,语义走 encoder + adapter 这条路,结构走 attention mask 这条路。 这和"检索十段代码,然后拼 prompt"不是一个层面的东西。
2.4 训练怎么做
训练分两步,也都很有针对性。
第一步是 Graph-to-Code 预训练。随机采一个子图,让模型根据图把代码生成出来。这个任务听起来像拼图,实际上是在逼模型同时学习两件事: 一是节点里文本的语义,二是节点之间的依赖关系。输出顺序也不是乱排的,高层节点靠前,文件按拓扑排序,文件内再按行号排。它不是瞎生成,是尽量贴近真实代码组织方式。
第二步是 Noisy Fine-tuning。拿真实的 issue-patch 对做微调,输入是子图加提示词,但提示词里故意加噪声: 有的样本会塞一个无关文件,有的样本又会漏掉该改的文件。这个做法挺工程化,因为真实检索本来就不可能次次完美,提前让模型吃点苦头,上线后反而更稳。
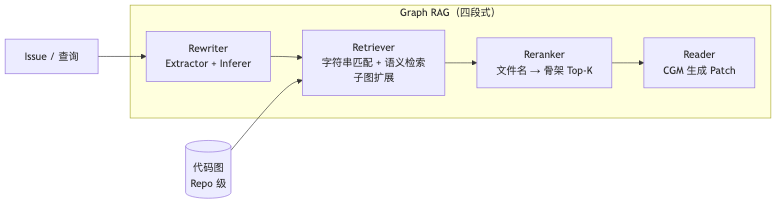
2.5 推理怎么跑: Graph RAG 四步走
论文把推理侧叫 Graph RAG。和一些十来步的 Agentless 流水线相比,它更短,但每一步都挺要命。流程如下:
flowchart LR
subgraph RAG["Graph RAG(四段式)"]
RW[Rewriter\nExtractor + Inferer]
RT[Retriever\n字符串匹配 + 语义检索\n子图扩展]
RR[Reranker\n文件名 → 骨架 Top-K]
RD[Reader\nCGM 生成 Patch]
end
ISS[Issue / 查询] --> RW
RW --> RT
RT --> RR
RR --> RD
CG[(代码图\nRepo 级)] --> RT
- Rewriter: 从 issue 里抽文件名、函数名、关键词,再把用户的话扩写成更适合检索的描述。论文里这里用的是
Qwen2.5-72B-Instruct。 - Retriever: 先靠字符串匹配找锚点,再用 CGE-Large 做语义检索,然后往外扩一跳邻居,再把它们连回根节点,保证子图连通。
- Reranker: 先按文件名筛一轮,从候选里挑出 Top-10,再按 file skeleton 缩到 Top-5。论文的消融实验明确说了,Reranker 非常关键,因为它决定了"到底改哪几个文件"。
- Reader: 这才是真正的 CGM。它一边吃 Retriever 给出的子图 node tokens,一边吃 Reranker 选中的文件全文 text tokens,一边看全局,一边看局部,最后生成 patch。
结果也确实不差: 在 SWE-bench Lite 上,CGM-SWE-PY 基于 Qwen2.5-72B 跑到了 43.00% 的 resolution rate。按照论文里的说法,这在开源权重方案里排第一。作者也把代码和权重放了出来: GitHub: codefuse-ai/CodeFuse-CGM, Hugging Face: CodeFuse-CGM-72B。
三、这篇论文真正有意思的地方
我觉得 CGM 真正有意思,不只是它跑出了一个不错的分数,而是它把一个常被忽略的问题捅破了: 仓库级任务的瓶颈,往往不是模型不会写代码,而是它搞不清该去哪里看,该改哪几个文件。
这话听起来平平无奇,可工程上分量很重。很多团队现在折腾半天,其实不是卡在"怎么生成那一行",而是卡在"上下文喂错了"。一旦上下文喂错,再聪明的模型也会一本正经地胡说八道。就像让一个医生看错了片子,他后面的诊断越认真,反而越可怕。
所以 CGM 的价值,不只是"让模型更强",而是把问题拆开了看:
- 一是先把仓库结构显式表示出来;
- 二是让检索和重排尽量把真正该看的子图捞上来;
- 三是让 Reader 在生成阶段还能继续利用这些结构关系。
一句话,它抓的不是表面的"长上下文",而是更底下的"结构化上下文"。这个角度,很值钱。
四、咱们该怎么落地(按投入分三档)
下面不是论文里的官方部署手册,而是我更看重的工程梯度。越往下,越接近 CGM 原教旨;当然,代价也越大。
第一档(Tier A): 我先把它跑起来
| 层级 | 选型思路 |
|---|---|
| 模型 | 直接拉 CodeFuse-CGM-72B 权重,按官方仓库 README 走推理 |
| 评测 | SWE-bench 子集或自建 issue–单测闭环 |
| 图与 RAG | 优先复用官方脚本/配置;Retriever 侧如需替换嵌入,再评估 CodeFuse-CGE(论文里的语义检索) |
这档适合做 benchmark,做对比实验,先验证"图 + 专用 Reader"在你们业务里到底值不值。不要一上来就想复现整篇论文,那样大概率把自己折腾得够呛。
第二档(Tier B): 我不训练模型,但我要抄它的思路
多数团队真正适合待的,其实是这一档。说得再直白一点: 论文的思想整包,比架构整包更容易落地。
| 模块 | 可替代实现 |
|---|---|
| 代码图 | 用 Tree-sitter 抽 AST,再用 LSP / SCIP 补跨文件引用,图可以先存成 内存邻接表 或 Neo4j / Memgraph |
| Rewriter | 任意强一点的 Instruct 模型,输出固定 JSON,把"实体列表 + query 扩写"做出来 |
| Retriever | BM25 / 向量库(Milvus、Qdrant) + 图上的 k-hop 扩展;多路召回用 RRF 合并 |
| Reranker | 小模型 cross-encoder,或者"文件名打分 → 骨架摘要打分"两阶段 |
| Reader | 普通 Decoder 就行,比如 Qwen-Coder、DeepSeek-Coder,再配结构化 prompt |
你在这一档里刻意放弃的,主要是两样东西: 一是图注意力掩码,二是 chunk 到 node token 的压缩。代价当然有,长仓库里结构信息仍会丢一部分,上下文也会更紧张。可它的好处同样明显: 迭代快,成本低,容易接进现有 Copilot 或内部工单系统。很多时候,这就够了。
第三档(Tier C): 我要在私有数据上继续训 CGM
| 层级 | 选型思路 |
|---|---|
| 基座 | Qwen2.5-72B-Instruct 这类 decoder-only 模型,Encoder 侧论文用的是 CodeT5+ |
| 训练 | PyTorch 2.x + FSDP / DeepSpeed;LoRA 或 QLoRA;自定义 attention mask 需要能往解码器里注入 block-sparse mask |
| 数据 | 公开 issue-patch 对 + 自建脱敏数据,复现 Graph-to-Code 与 noisy fine-tuning 的数据管线 |
| 观测 | W&B / MLflow,再配离线 SWE-bench 子集回归 |
这一档适合平台团队,前提是你们真有训练资源,也有安全合规闭环,更重要的是,业务上真的值得为"repo 级专用大脑"单独投钱。否则的话,第二档往往已经够用到下一轮模型换代了。
五、路线图(建议按季度想,不要按周末想)
Q0(1-2 周): 先把 CodeFuse-CGM 跑通。别急着谈平台化,先选 3-5 个你们真实仓库里的历史 issue 做"离线回放",对比现有纯 RAG 或 Agent 方案。先看有没有肉眼可见的差别。
Q1(4-8 周): 落地第二档。把 图构建 job 统一起来,可以是 CI 里增量更新,也可以先做定时全量;把 节点 schema 定下来,先粗后细;Retriever 日志里要记清楚"锚点 → 扩展子图"的全过程,后面分析效果全靠它。
Q2(视人力): 把 Reranker 做成可插拔策略,学论文的两阶段打法;再引入一个 轻量 cross-encoder,专门收拾那种"文件名像、骨架也像、可语义就是不对"的场景。
Q3+: 如果 benchmark 和真实业务两边都证明值回票价,再考虑第三档。从 冻结 decoder,先训 adapter 开始,慢慢再打开图注意力相关部分。全程用 SWE-bench 子集做门禁,不要靠"感觉它变聪明了"来做判断。那种感觉,往往不太靠谱。
六、什么时候值得用,什么时候别硬上
值得认真往 CGM 这条路走的信号:
- 你们的问题里,"改哪几个文件" 比 "怎么写那一行" 更难;
- 已经有单测或 CI 信号,能做成 可自动判对错 的闭环;
- 代码不能出公网,开源全链路 是硬需求。
不必硬上的信号:
- 任务本质上还是 CRUD 或单文件脚本,HumanEval 型模型配一个好 prompt 就够了;
- 团队没人能长期维护 图数据正确性。图一脏,后面全玄学;
- 没有评测集,只是想上一个新名词,那就先在第二档里小步试错,不必上强度。
七、明天就能做的 5 条 CheckList
- 先把论文的 Figure 2-3 看明白,知道代码图长什么样,四个模块怎么流转。看 HTML 版 会比 PDF 更方便。
- Clone CodeFuse-CGM,把 Reader + 最小子图 在样例仓库上跑通。
- 给你们最大的 repo 先画一张 "文件 → 符号" 的粗粒度图,人工 spot check 10 条跨文件边。
- 把 Retriever 日志 做起来,记录每次 issue 的子图节点数、边数、Top-K 文件列表。后面调优 Reranker,全靠这个。
- 用 第二档(Tier B) 做对照实验: 同一批 issue,比一比 "图摘要 + 文件全文" 和 "扁平长上下文" 哪个单测通过率更高。
总结
CGM 的贡献,我觉得可以压成三句话。
第一句话,它用文本富图把仓库结构显式保留了下来。
第二句话,它不是只把代码片段喂给 LLM,而是把语义和结构一起送进了模型。
第三句话,它抓住了仓库级任务真正难的地方: 不是不会生成,而是找不准上下文,也找不准该改哪里。
外面再套一层 Graph RAG,把"检索谁、改谁、怎么生成 patch"拆成四段可控流水线,所以它才能在 SWE-bench Lite 上,用 开源 Qwen2.5-72B 跑到 43%。这个成绩固然还谈不上横扫四方,可它已经说明了一件事: 仓库级软件工程,不一定非得把希望都押在闭源 agent 身上。
思维导图(PlantUML 源在下方,图为渲染结果):
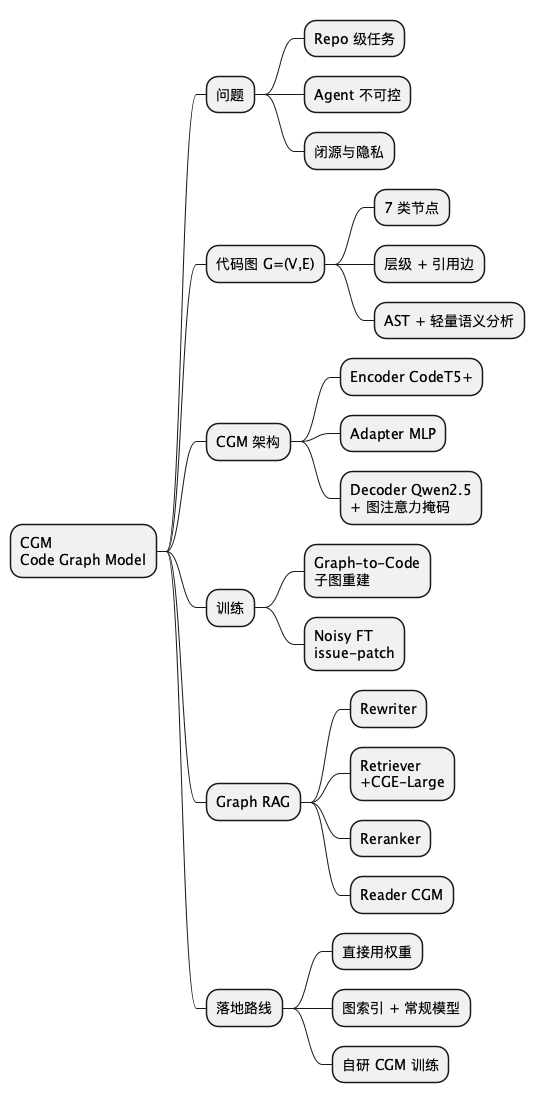
@startmindmap
* CGM\nCode Graph Model
** 问题
*** Repo 级任务
*** Agent 不可控
*** 闭源与隐私
** 代码图 G=(V,E)
*** 7 类节点
*** 层级 + 引用边
*** AST + 轻量语义分析
** CGM 架构
*** Encoder CodeT5+
*** Adapter MLP
*** Decoder Qwen2.5\n+ 图注意力掩码
** 训练
*** Graph-to-Code\n子图重建
*** Noisy FT\nissue-patch
** Graph RAG
*** Rewriter
*** Retriever\n+CGE-Large
*** Reranker
*** Reader CGM
** 落地路线
*** 直接用权重
*** 图索引 + 常规模型
*** 自研 CGM 训练
@endmindmap
最后留一个问题给你。
如果你们今天就把 "改哪些文件" 猜对的概率,从 60% 提到 85%,你们现有研发链路里最先受影响的,会是哪一环?
我猜,很多时候不是模型先不够用,而是检索、重排和上下文组织先拖了后腿。想清楚这一点,往往比急着去训一个新 attention mask 更划算。
扩展阅读
- arXiv:2505.16901 — Code Graph Model(CGM)(论文摘要页; 全文 PDF: 2505.16901)
- arXiv HTML v4(便于跳转章节)
- GitHub: codefuse-ai/CodeFuse-CGM
- Hugging Face: CodeFuse-CGM-72B
- SWE-bench - 仓库级 issue 修复基准
- GitHub: codefuse-ai/CodeFuse-CGE - 论文 Retriever 侧语义嵌入相关
本作品采用 知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议 进行许可。