给代码仓库造一个 DeepWiki:Tree-sitter + Embedding + 图谱 + LLM 的方法论
Posted on 四 16 4月 2026 in Journal
| Abstract | 给代码仓库造一个 DeepWiki:Tree-sitter + Embedding + 图谱 + LLM 的方法论 |
|---|---|
| Authors | Walter Fan |
| Category | Journal / RAG 方法论 |
| Version | v1.6 |
| Updated | 2026-04-20 |
| License | CC-BY-NC-ND 4.0 |
给代码仓库造一个 DeepWiki
一、从一个尴尬的场景说起
新同事入职第一周,在团队群里小心翼翼地问:
"那个
runSync是从哪里被调用的?为啥它 defer 里还要recover?"
老板瞟一眼,回:
"你自己看下代码嘛,很简单的。"
简单个头。一个"成熟"的项目,动辄几十万行、几百个文件、依赖一堆内部库。新人不是不想看,是根本不知道从哪个文件开始。README 停在两年前,架构图早就对不上,注释是写给编译器看的不是给人看的。
老同事这时候通常会掏出新玩具:"把整个仓库丢给 Cursor / ChatGPT 不就行了吗?"
你试过就知道,上下文一爆,LLM 直接开始编。它会一脸自信地写出一个 SyncManager.run(),文件路径格式都对,就是项目里压根没这个类。你把这份答案转给新人,新人再去问老同事,三个回合下来,大家一起怀疑人生。
所以 DeepWiki、Sourcegraph Cody、Cursor 的 Codebase Indexing 这些产品火起来,背后不是因为模型变聪明了,而是因为他们想明白了一件事:
代码库不是文档,不能按字符切块;代码的灵魂在 AST 和调用关系里,而不是字面意思。
我自己折腾过一个麻雀虽小的 DeepWiki 平替,本地就能跑。写下来不讲具体代码,只聊方法论,背后就四件套:
Tree-sitter 解析 + Embedding 向量 + 图数据库 + LLM 生成。
读完你能抄走:整体流程、每一层的取舍、几个真踩过的坑,末尾一份 CheckList。
二、为什么"代码不是文稿"
先劝退一下最常见的 Demo 级做法:
- 读所有文件
- 用
RecursiveCharacterTextSplitter每 1000 字符切一段 - 丢进 FAISS / Chroma
- query embed 一下取 Top-5,扔给 LLM
这套流程在 PDF 手册、博客文章上还凑合,在代码库上基本废掉。毛病就三条:
- 切块破坏语义。一个函数刚好卡在 1000 字符边缘被劈成两半,embedding 看到的半截函数,语义跟完整函数差出十万八千里。就像把一篇议论文从中间咔嚓一刀,上半截看起来在喊口号,下半截看起来在讲段子,合起来才是原意。
- 缺少结构化过滤。你想问 "所有
Handle*开头的 HTTP handler",向量检索给不出来——它只会吐 "语义相似" 的东西,而不是 "类型=函数且名字以 Handle 开头" 。 - 丢失调用关系。代码的灵魂是 谁调用谁、谁实现了谁、谁 import 了谁 ,纯向量检索能找到 "长得像的代码" ,找不到 "
runSync是被谁触发的" 。
代码是系统,不是文稿。要做对,先把一段代码解析成带结构的实体,而不是字符串块。
三、整体架构:四件套各司其职
先上一张总图,后面每一节对应图里的一块:
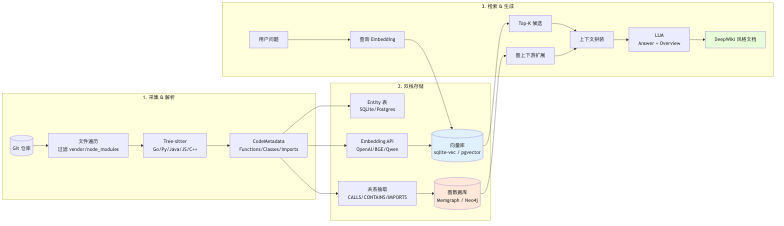
flowchart LR
subgraph Ingest["1. 采集 & 解析"]
Git[("Git 仓库")] --> Walker["文件遍历<br/>过滤 vendor/node_modules"]
Walker --> TS["Tree-sitter<br/>Go/Py/Java/JS/C++"]
TS --> Meta["CodeMetadata<br/>Functions/Classes/Imports"]
end
subgraph Store["2. 双栈存储"]
Meta --> Entity["Entity 表<br/>SQLite/Postgres"]
Meta --> EmbSvc["Embedding API<br/>OpenAI/BGE/Qwen"]
EmbSvc --> Vec[("向量库<br/>sqlite-vec / pgvector")]
Meta --> GraphB["关系抽取<br/>CALLS/CONTAINS/IMPORTS"]
GraphB --> Graph[("图数据库<br/>Memgraph / Neo4j")]
end
subgraph Query["3. 检索 & 生成"]
Q["用户问题"] --> EmbQ["查询 Embedding"]
EmbQ --> Vec
Vec --> TopK["Top-K 候选"]
Graph --> Expand["图上下游扩展"]
TopK --> Ctx["上下文拼装"]
Expand --> Ctx
Ctx --> LLM["LLM<br/>Answer + Overview"]
LLM --> Wiki["DeepWiki 风格文档"]
end
图看起来零件不少,其实就三条主干,先点出来,后面逐层展开:
- 双栈存储:向量库管 "模糊语义匹配" ,图数据库管 "精确结构关系" ,谁都替代不了谁。硬用一个干两件事,得一个四不像。
- Entity 是一等公民:不是 chunk,不是文件,是 "函数/类/文件" 这种有类型、有位置、有边界的东西。拿 chunk 当单位就像拿页码编索引,永远定位不到 "哪一行的那句话" 。
- 增量同步:Git diff 决定只重算变更部分。全量跑一次 10 分钟,增量能压到几秒——从"每次改完代码去喝杯咖啡再回来"到"保存即刷新",工程师体感直接换挡。
这种分工不是我拍脑袋定的。Yu 等人 2023 年那篇 LLMs for Knowledge Graph Construction and Reasoning 跑了八个数据集,结论很扎心: LLM 更适合当"推理助手",而不是"少样本抽取器" 。翻译成人话就是,别指望 LLM 替你抽实体、建边,那是脏活累活;让它在已经结构化好的图上做推理和回答,才是它擅长的。双栈存储里,图和向量干的就是"抽取和整理"那一半,LLM 只负责最后"说人话"那一段。各司其职。
核心数据模型
模型错了后面全歪,所以先把骨架定下来。整套系统其实只要五张"表"——详细 UML 放在下面折叠块里,正文只讲设计取舍:
| 表 | 关键字段 | 干啥的 |
|---|---|---|
| Repository | id / branch / last_successful_commit |
每个仓库一行,记住"上次同步到哪了" |
| Entity | id / type / name / file_path / start_line / end_line / signature / doc |
一等公民:函数、类、文件 |
| EmbeddingVector | entity_id → vector[dim] |
和 Entity 一对一,向量库单独存 |
| Relation | source_id → target_id (type, weight) |
CALLS / CONTAINS / IMPORTS 等,入图库 |
| KnowledgeDoc | repo_id / doc_type / content |
生成出来的 Overview、Repo Map 等 |
三条不起眼但决定生死的设计规则:
- Entity ID 必须是内容 hash(例如
sha256(repo + path + type + name + start_line)前 8 字节)。 不可变、可重现 是增量同步的前提——自增 ID 一上量就撞车。 - 向量表和 Entity 解耦 。换 sqlite-vec 还是 pgvector,Entity 本体不该感知到。
- Relation 进图库、不进主库 。一个函数既被 CONTAIN、又 CALL 别人,关系表一张根本扛不住,图库天生就是干这个的。
完整 UML(点开看)
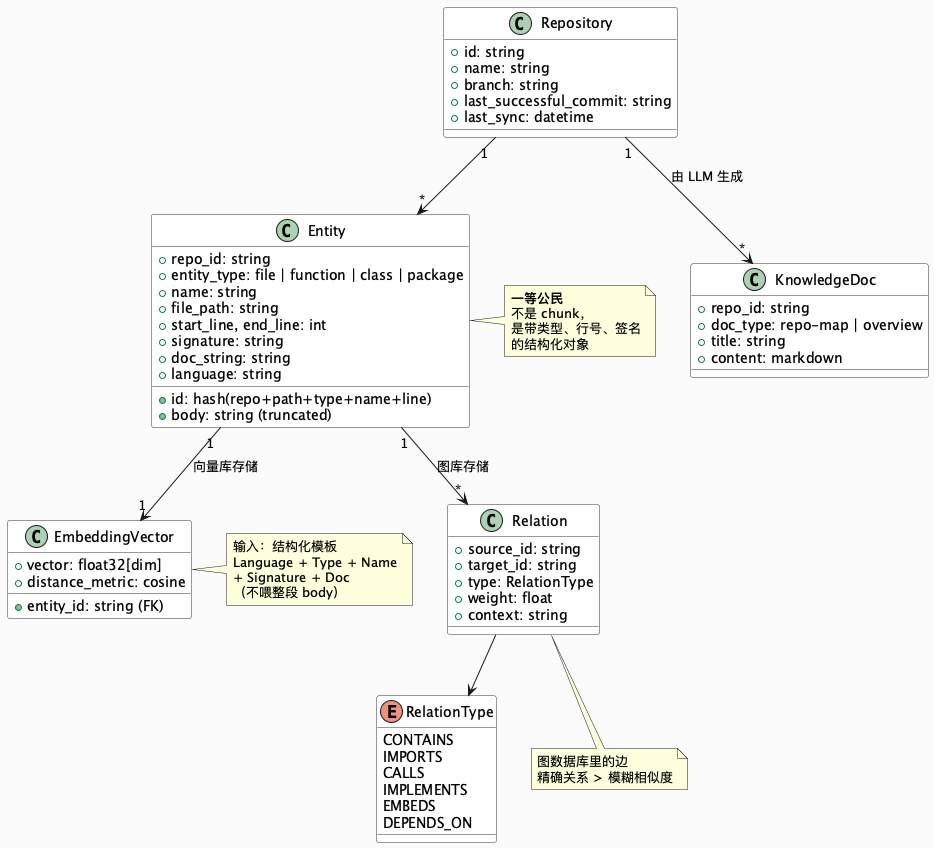@startuml
skinparam backgroundColor #FAFAFA
class Repository {
+ id: string
+ name: string
+ branch: string
+ last_successful_commit: string
+ last_sync: datetime
}
class Entity {
+ id: hash(repo+path+type+name+line)
+ repo_id: string
+ entity_type: file | function | class | package
+ name: string
+ file_path: string
+ start_line, end_line: int
+ signature: string
+ doc_string: string
+ body: string (truncated)
+ language: string
}
class EmbeddingVector {
+ entity_id: string (FK)
+ vector: float32[dim]
+ distance_metric: cosine
}
class Relation {
+ source_id: string
+ target_id: string
+ type: RelationType
+ weight: float
+ context: string
}
enum RelationType {
CONTAINS
IMPORTS
CALLS
IMPLEMENTS
EMBEDS
DEPENDS_ON
}
class KnowledgeDoc {
+ repo_id: string
+ doc_type: repo-map | overview
+ title: string
+ content: markdown
}
Repository "1" --> "*" Entity
Entity "1" --> "1" EmbeddingVector
Entity "1" --> "*" Relation
Relation --> RelationType
Repository "1" --> "*" KnowledgeDoc
@enduml
四、解析层:Tree-sitter 才是切块的正确姿势
为什么是 Tree-sitter
能做源代码 AST 解析的工具其实不少:LSP、go/ast、javaparser……但能用同一套 API 解析 N 种语言的,Tree-sitter 几乎是唯一解:
- 多语言统一接口
- 增量解析,快
- 对"烂代码"容错——半截代码、语法错误也能解析出能用的 AST
- 有现成的 Go / Python / Java / JS / C++ grammar
解析要吐出什么?
解析器的目标不是"把代码读一遍",而是吐出一份语言无关的中间表示。每个文件输出一个结构体,大致长这样:
CodeMetadata {
file_path: relative path
language: go | python | java | ...
functions: [ { name, signature, doc, start_line, end_line, body } ]
classes: [ { name, doc, methods, start_line, end_line } ]
imports: [ ... ]
comments: [ ... ]
}
然后把这份中间表示转成统一的 Entity 列表,扔进主存储。所有语言到这一层就被抹平了——下游的向量化、建图、检索,完全不用关心底层是 Go 还是 Python。
三个关键细节
- 保留行号:
start_line / end_line一定要透传到最后。生成回答时才能精确指给用户"去看xxx.go:123-145",幻觉空间压到最小。 - Body 截断:单个函数体截到 3000–4000 字符够用。超过这个长度往往是"God function",本身就该重构,硬塞进 embedding 意义不大。
- 跳过二进制与无关目录:
vendor/、node_modules/、__pycache__/、dist/、build/、.git/一定要在遍历时就 skip,否则你会 embed 几万个第三方库函数,账单炸穿。
容易踩的坑
- Tree-sitter 的
tree.Close()要记得释放,不然大仓库扫下来能吃掉几 G 内存。 - 闭包、匿名函数拿不到稳定 identifier,直接丢弃,不要硬塞一个
anonymous_42进去。 - 多语言 grammar 的节点名不一样(Go 是
function_declaration,Python 是function_definition),每种语言写一个薄 visitor,不要试图写一个大而全的"通用访问器"。
这一层的底线:吐出来的 Entity 必须 语言无关、带精确位置、可重入 。做到这三件,下游每一层都省事;做不到,后面怎么补都补不回来。
五、向量层:Embedding 不是"把代码丢进去"那么简单
结构化输入才是关键
很多人第一次做代码向量化,直接把函数源码丢进 embedding。能用,但召回质量差。原因是 embedding 模型训练时主要看的是自然语言 + 少量代码,你扔一整段代码进去,它能抓的"概念信号"被符号稀释了。
正确做法是结构化输入模板,只喂"高浓缩信号":
Language: Go
Type: function
Name: runSync
Signature: func (s *Service) runSync(repo *Repository, ...) error
Doc: runSync performs a full repository scan, parses all code files,
generates embeddings and builds the code graph. Called by
TriggerSync when no incremental diff is available.
别看这几行模板土,效果差别很大:名字、签名、doc string 这三个东西 语义密度最高 ,embedding 一看就懂。函数体反而是噪音——把噪音留给全文检索或图检索去啃。
经验法则:Embedding 吃"高浓缩信号",关键字/图吃"完整细节"。一个工具别指望它干所有活,就像让架构师去接电话一样不合理。
sqlite-vec vs pgvector:真的要选吗?
两个都值得了解,但选型判断并不复杂:
| 场景 | 选它 | 理由 |
|---|---|---|
| 单用户、本地 IDE 插件、个人项目 | sqlite-vec | 零运维、无依赖、打包进单个二进制。100 万向量以内性能完全够用 |
| 团队共享、服务端、>100 万向量 | pgvector | 生态最强,IVFFlat / HNSW 索引成熟,能复用现有 PG 基础设施 |
| 超大规模、多租户、复杂过滤条件 | 专用向量库(Qdrant/Milvus/Weaviate) | 绝大多数团队用不到 |
sqlite-vec 一个被忽视的好处:它是 SQLite 的虚拟表扩展,检索结果可以直接和普通 SQL JOIN。你拿 entity_id 回捞 Entity 元数据——语义检索 + 关系型过滤,一条 SQL 搞定,完全不需要单独维护一个向量数据库实例。
批量、重试、限流:工程化三件套
Embedding API 很容易被你"打爆"。上生产前,下面三件事必须到位:
- 批量:一次 50 条一起发,省 token 也省 RTT。
- 指数退避重试:第 N 次重试等
base * 2^N毫秒,避免雪崩。 - 速率限制:按 RPM(每分钟请求数)算最小间隔,尤其对自建 BGE / Qwen-Embedding 的团队。
看起来像八股,真上生产缺一不可。
这一层的底线 : 向量只吃高浓缩信号,绝不吃整段函数体 。做对了,Top-K 召回质量直接翻倍;做错了,后面怎么调 K 都救不回来。
六、图层:为什么代码非得有图不可
一个具体场景
回到开头那个问题:"runSync 从哪里被调用?"
纯向量检索会给你一堆"看起来跟 sync 有关"的函数。对,但没用——新人要的是精确的调用链:谁触发的、里面又调了谁、失败了走哪条路。
这就是图数据库出场的理由。推荐用 Memgraph(跟 Neo4j 的 Bolt 协议兼容,但单机性能更猛、纯内存),已有 Neo4j 的团队直接用也可以。
边的类型必须有限可枚举
不要试图用一个通用的 "RELATED" 搞定所有关系。代码世界里真正有用的边就那么几种:
RelationType :=
CONTAINS # file 包含 function/class
IMPORTS # file 导入 package
CALLS # function 调用 function
IMPLEMENTS # class 实现 interface
EMBEDS # struct 嵌入另一个 struct
DEPENDS_ON # 模块级别依赖
RETURNS # 函数返回某类型
ACCEPTS # 函数接受某类型作为参数
一开始先搞定 CONTAINS / IMPORTS / CALLS 三种,80% 的查询场景就能覆盖了。其他的慢慢加。
调用关系的"穷人版"检测
理论上调用关系应该用 LSP / 编译器做静态分析,拿到精确的符号表。但实际工程里经常为了速度选择正则匹配,流程大致是:
- 扫一遍所有函数,建一张
functionByName的索引 - 对每个函数 body,用
\b<name>\s*\(这样的正则去匹配 - 命中的就建一条 CALLS 边
这种做法一定会有假阳性(同名方法、注释里提到名字、字符串里出现函数名)。但好处是:
- 不需要语言级的符号解析
- 跨语言一套代码搞定
- 实现成本十分之一
对"帮新人建立直觉"、"生成 DeepWiki 式文档"来说,精度 80% 够用了。如果后续要做精确的 refactor 推荐或 dead code 检测,再换成 LSP 也不晚。
降噪:别把内置类型塞进图里
这个点特别容易被忽视——不加过滤的图,90% 都是垃圾节点。
Go 里的 string / int / len / make、Python 里的 list / dict / print、Java 里的 String / Integer……这些符号每个文件都出现,如果都建节点,打开图你只会看到一团乱麻。
降噪策略两条:
- 维护一张语言内置类型/函数黑名单,直接过滤
- 过滤掉小写开头且短于 2 字符的符号(一般是循环变量、临时变量)
过滤之后,图的第一感受应该是"哦,原来模块是这么组织的",而不是"怎么全是 len"。
全量 upsert 的一个小反直觉
图库同步时,不要傻乎乎地算 diff。更简单、更快的做法是:按 repo_id 全量 DETACH DELETE,然后重建。
理由:
- 代码里的调用关系变化是非局部的。你改一个函数名,可能牵连几十条 CALLS 边。算 diff 比重建还贵。
- Memgraph 是内存数据库,重建几万节点几万边也就 1–2 秒。
- 业务上可以接受"几秒的不一致窗口",查询端加个重试就好。
七、检索层:混合检索才靠谱
解析、向量、图三个存储都备齐之后,检索这一层的核心原则就一句话—— 不同检索器各有长短,永远混着用,别指望一根绳子挂所有灯笼 。
最小可行三板斧
按优先级来:
- 向量优先:query embed → KNN → Top-K 候选。
- 关键字兜底:embedding 服务挂了、key 没配,就退回 "名字匹配 3 分、正文匹配 1 分" 的朴素打分。朴素打分有个好处是永远不会挂。
- 图扩展:拿 Top-K 实体去图上取邻居(
CALLS/CONTAINS的 1–2 跳),一起打包给 LLM。
第三步才是 DeepWiki 能答"为什么"类问题的招牌动作——用户问一个函数,你给 LLM 的是 它加上它的上下游 ,而不是一个孤零零的函数体。
进阶版:BM25 + 向量 RRF 融合
工业级做法是 BM25 + 向量做 RRF(Reciprocal Rank Fusion) :两个检索器各出一份排序,按 1/(k+rank) 加权合并。公式不难,RRF 专门写过一篇,可以翻前面那篇。
真想再往前一步,2025 年 CodeFuse 团队在 NeurIPS 上发的 CGM(Code Graph Model,arXiv 2505.16901)给了一条更完整的流水线——他们叫 R4 chain:Rewriter 改写问题、Retriever 在代码图上取候选子图、Reranker 挑出最可能要改的文件、Reader 生成补丁。拆开看每一步都不神秘,但串起来在 SWE-bench Lite 上拿到了开源模型第一(43% 解决率)。 关键启发不是"上更强的模型",而是"把检索这步再拆细一层" ——Rewriter 和 Reranker 各自解决一个你原本靠运气解决的问题。
再进阶:Graph RAG —— 当图本身成为检索入口
前面三板斧里图只是"配角"——向量先命中入口函数,图顺着 CALLS/CONTAINS 扩一两跳邻居,锦上添花。但要问出 DeepWiki 级别 的问题,图必须升级成一等公民,这个范式学术圈叫 Graph RAG 。
为什么向量 RAG 答不了这类问题?想象同事这么问:
- "这个项目的鉴权体系整体是怎么设计的?"
- "支付模块和订单模块之间的所有耦合点列一下。"
答案 不在某一段代码里 ,而是散落在几十上百个文件里,需要 先全局、后局部 。向量只会吐最相似的 top-k 切片,LLM 拿着这堆碎片拼不出图景——微软的 Edge et al. (arXiv 2404.16130, 2024) 把这类问题正名为 query-focused summarization (QFS) ,论文题目 From Local to Global 本身就是答案。
Graph RAG 的配方就两步 :建图时用 社区检测(Leiden/Louvain)把图切成"实体团",对每个团 预生成一段摘要 ,逐层上卷成一棵摘要树;查询时不走 top-k ,而是让每个相关社区的摘要 各出一份部分答案,再 map-reduce 归并 。在 1M tokens 的全局问题上,这套打法在"答得全不全、角度多不多样"两项都明显压过朴素 RAG。
代码场景天然好切——package / module / 目录就是现成的社区,让 LLM 给每个 module 写一段"设计意图摘要"(50–200 字)存进图节点,全局问题走 module 摘要召回,局部问题退回向量+图扩展,再上强度就把 CGM 的 R4 chain 接在后面。
Graph RAG 对 DeepWiki 的意义:普通 RAG 做出来的是"代码碎片搜索引擎";而 Wiki 承诺的是 "能从目录翻到章节、从章节读到段落"的可导航层级 ——这个层级恰好就是 Graph RAG 的产物。缺了它你顶多做成加强版 ctags;有了它,才配叫 Wiki。
不过作为第一版, "向量优先 + 关键字兜底" 完全够用, debug 也友好。Graph RAG 是 达到 "DeepWiki 级体验" 前的最后一道坎 , 不是第一版该上的 。先让系统跑起来,再优化召回指标。
八、生成层:把检索结果拼成"像样的 DeepWiki 文档"
最后一步才轮到 LLM——第三节已经讲过它的定位是"翻译官"、不是主角,这里只补怎么让它稳。上下文不对,它再聪明也白搭。
Prompt 必须带定位信息
两条写进 system prompt 的硬规则:
- 强制引用路径+行号:
Always cite specific function/file locations. - 允许说不知道:
If the code context is insufficient, say so honestly.
第二条比第一条更关键。给 LLM 留一个"我不确定"的台阶,它就不会硬编;不留,它就开始创作。同一个模型、同一份上下文,给不给台阶,回答质量差一个量级。这条规律在我试过的 GPT、Claude、Qwen 上都成立,没有例外。
上下文拼装格式
每段上下文前加结构化头,让 LLM 清楚看到类型、位置、范围:
### [1] function `runSync` (service.go:166-276)
```<code-body>```
### [2] function `TriggerSync` (service.go:123-164)
```<code-body>```
对比一下"把 5 段代码直接粘一起"这种随手拼,前者的回答引用准确率能翻倍。
生成 DeepWiki 风格概览:结构化 Prompt
生成一份 "Project Overview" 文档,用固定结构的 system prompt:
You are a senior engineer writing a concise project overview.
Follow this structure:
1. Purpose — what problem the project solves (1-2 sentences)
2. Technology Stack — languages, frameworks, databases
3. Architecture — high-level module structure
4. Key Components — most important modules and their roles
5. Entry Points — where the app starts, main routes, CLI commands
Be specific. Reference actual file paths and function names.
Keep it under 500 words. Use Markdown.
结构化 prompt 比开放式 prompt 稳定一个量级。你要的是一篇能放进 wiki 的文档,不是聊天,所以先告诉它"要分这五段,每段都要带真实路径和函数名"。
九、把整条流水线串起来:一张时序图
前面八节分头讲了每一层,最后用一张时序图把索引和查询两个阶段串起来:
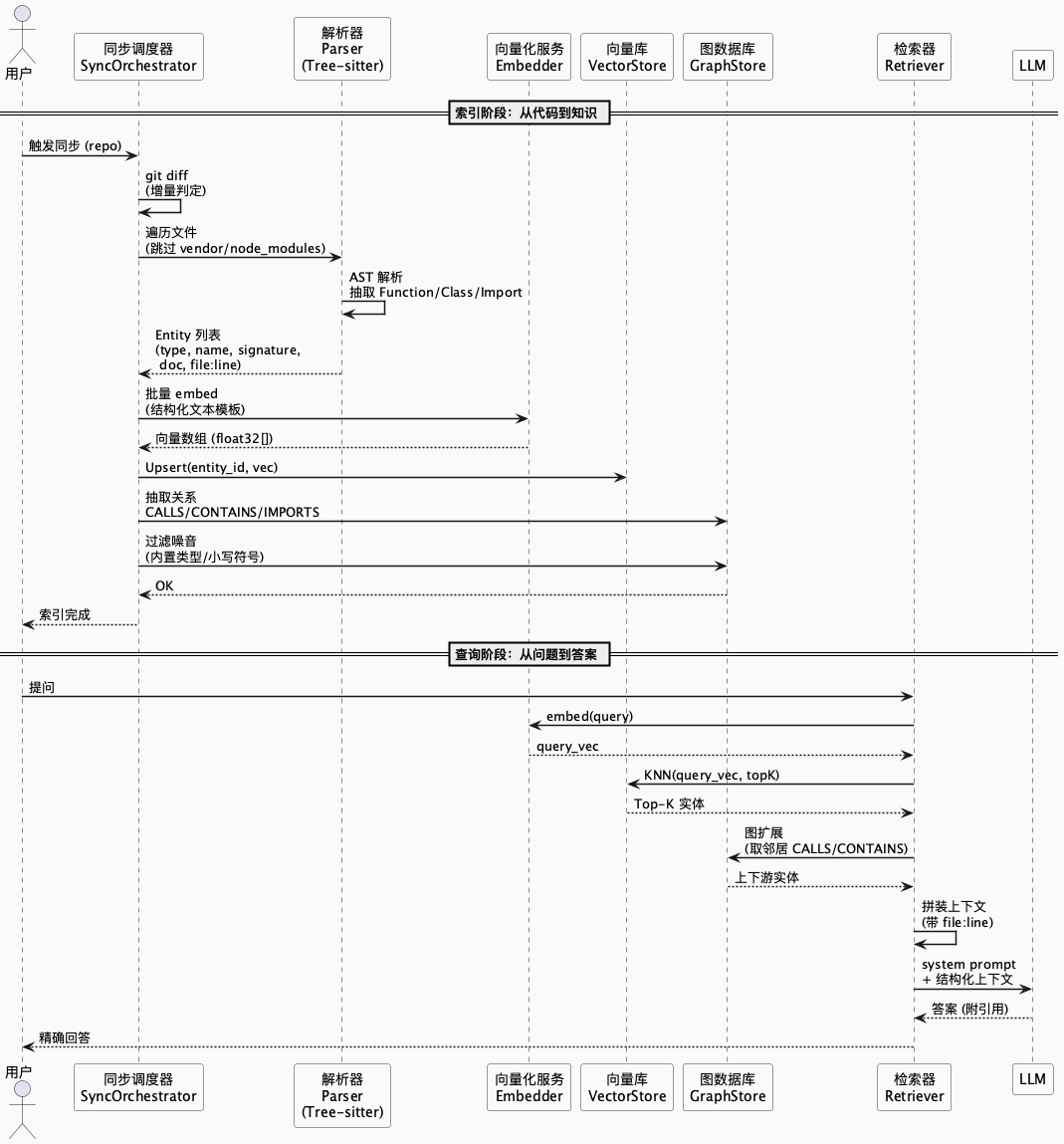
@startuml
skinparam backgroundColor #FAFAFA
actor 用户 as U
participant "同步调度器" as S
participant "解析器\n(Tree-sitter)" as P
participant "向量化服务" as E
participant "向量库" as V
participant "图数据库" as G
participant "检索器" as R
participant "LLM" as L
== 索引阶段:从代码到知识 ==
U -> S: 触发同步 (repo)
S -> S: git diff\n(增量判定)
S -> P: 遍历文件\n(跳过 vendor/node_modules)
P -> P: AST 解析\n抽取 Function/Class/Import
P --> S: Entity 列表\n(type, name, signature,\n doc, file:line)
S -> E: 批量 embed\n(结构化文本模板)
E --> S: 向量数组
S -> V: Upsert(entity_id, vec)
S -> G: 抽取关系\nCALLS/CONTAINS/IMPORTS
S -> G: 过滤噪音
G --> S: OK
S --> U: 索引完成
== 查询阶段:从问题到答案 ==
U -> R: 提问
R -> E: embed(query)
E --> R: query_vec
R -> V: KNN(query_vec, topK)
V --> R: Top-K 实体
R -> G: 图扩展\n(取邻居 CALLS/CONTAINS)
G --> R: 上下游实体
R -> R: 拼装上下文\n(带 file:line)
R -> L: system prompt\n+ 结构化上下文
L --> R: 答案 (附引用)
R --> U: 精确回答
@enduml
这张图里有两件事值得咀嚼:
- 索引阶段是"写多读少":parse → embed → upsert → 建图。瓶颈在 embedding API。
- 查询阶段是"读多写少":embed query → KNN → 图扩展 → 拼 prompt → LLM。瓶颈在 LLM。
两个阶段的性能瓶颈不同,优化路径也不同—— 不要混在一起调 。再往下拆,整条流水线真正值得琢磨的变量就两个: 索引阶段能不能做增量,查询阶段能不能装下正确的上下文 。前者决定你能不能上生产,后者决定答案质量——下一节讲前者。
十、工程化关键:增量同步才是上生产的分水岭
前面讲的一切都有一个前提—— 代码每天都在变 。代码一改就全量重跑?扫一次 5 分钟,embed 一次 10 分钟,上线第一天工程师就提桶跑路了。所以增量同步不是可选优化, 是能不能上生产的分水岭 。
这条路上 2024 年清华团队的 RepoAgent(arXiv 2402.16667)已经替咱们蹚过一遍,它的三件套正好是 "AST 解析 + 跨文件调用关系 + 监听 Git 变更做增量更新" ——和咱们接下来要讲的几乎一模一样。读完那篇你会发现,结论不是"哪种实现最优",而是 "不做增量同步的代码知识库都只能活在 Demo 里" 。
10.1 用 Git 当变更源:diff 而不是 log
第一反应是"遍历 git log 把每个 commit 的变更合一合",别——这是给自己加戏。 log 给的是 提交历史 , diff 给的是 最终态差集 。同一个文件在十个 commit 里被改了十次,用 diff 只需要处理一次;用 log 聚合,碰到"先加后删、先删后加、先改后 revert"这种诡异链,自己写聚合必翻车。 git diff <from>..HEAD --name-status 已经帮你把最终态算好了,直接用。
核心闭环就三步:
- 跑
git diff <last_successful_commit>..HEAD --name-status - 按变更类型分别处理(下面那张表)
- 全部阶段成功,才把
last_successful_commit推进到HEAD
状态图把这个闭环画清楚了:
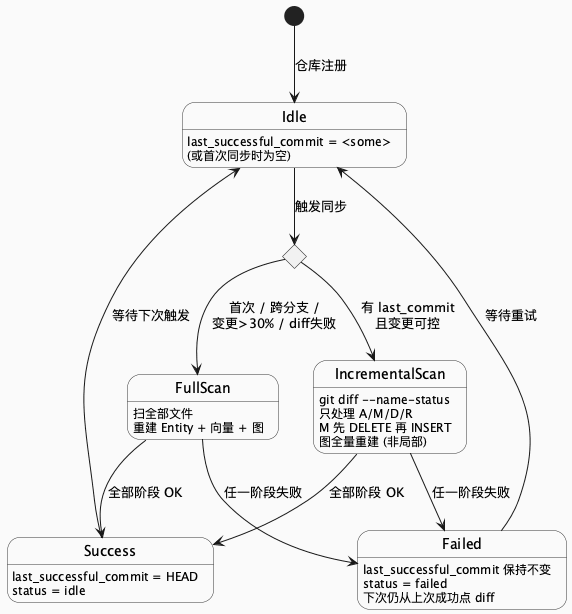
@startuml
[*] --> Idle : 仓库注册
state Idle {
Idle : last_successful_commit = <some>
Idle : (或首次同步时为空)
}
Idle --> Decide : 触发同步
state Decide <<choice>>
Decide --> FullScan : 首次 / 跨分支 /\n变更>30% / diff失败
Decide --> IncrementalScan : 有 last_commit\n且变更可控
state IncrementalScan {
IncrementalScan : git diff --name-status
IncrementalScan : 只处理 A/M/D/R
IncrementalScan : M 先 DELETE 再 INSERT
IncrementalScan : 图全量重建 (非局部)
}
FullScan --> Success : 全部阶段 OK
IncrementalScan --> Success : 全部阶段 OK
FullScan --> Failed : 任一阶段失败
IncrementalScan --> Failed : 任一阶段失败
state Success {
Success : last_successful_commit = HEAD
}
state Failed {
Failed : last_successful_commit 保持不变
Failed : 下次仍从上次成功点 diff
}
Success --> Idle
Failed --> Idle
@enduml
10.2 四种变更,四种姿势
git diff --name-status 吐出来的状态码就那几种,落到处理逻辑上正好四类:
| 状态 | 动作 |
|---|---|
A 新增 |
parse → 生成 Entity → embed → 建图边 |
M 修改 |
按 file_path 先整体 DELETE,再 parse 重建 (下面专门说) |
D 删除 |
删 Entity + 向量条目 + 图节点 |
R 改名 / C 复制 / T 类型变化 |
拆成 "D 旧 + A 新" 或按 M 处理 |
最容易踩的坑是 M ——直觉会告诉你"update 就行了嘛",错。 Entity ID 是 hash(repo + path + type + name + start_line) ,一个函数从第 100 行挪到第 120 行,哪怕一个字符都没改,start_line 变了 ID 就跟着变。 upsert 永远命中不上旧记录,脏数据一堆。
所以 M 的正确姿势只有一种: 按 file_path 先整体 DELETE,再把新解析出来的 Entity 批量 INSERT 。丑,但稳。
10.3 最大的坑:图里的"悬空边"
这是我自己踩过最贵的一个坑——只看文件 diff 不够。
看下面这个场景:
文件 A.go 没改
文件 B.go 改了一个函数名:doAuth → authenticateUser
Git diff 只会报 M B.go。但文件 A.go 里原本有一条 CALLS → doAuth 的边,现在目标函数根本不存在了。如果你只重建 B.go 的图节点,A.go 指向的那条边就成了悬空边——查询时一脚踩空,给用户返回一个 ID 但捞不到实体。
两种解决方案,我推荐后者:
- 朴素法:M 文件里涉及函数签名变化的,把它和它的反向依赖一起重扫。在图库里跑一次
MATCH (s)-[:CALLS]->(t {file_path: 'B.go'}) RETURN DISTINCT s.file_path拿到反向依赖列表。 - 激进法(推荐):向量增量 + 图全量重建。每次同步,向量按 diff 精细更新;图库按
repo_id整体DETACH DELETE再重建。
为什么选 2?因为代码关系是非局部的,纠结局部更新不划算。图全量重建几万节点几万边也就 1–2 秒(Memgraph 是内存数据库),换来一行悬空边都没有的安心,血赚。
10.4 什么时候该放弃增量、回到全量
增量不是银弹。三种情况老老实实走全量:
- 首次同步:
last_successful_commit为空,没 diff 可做。 - 分支切换:
git diff main..HEAD能算出几千个变更,增量反而更慢。 - 大范围改动:diff 文件数超过总文件数的 30% ,增量的 overhead 已经接近全量。
一句话经验: 别高估 diff 算法,早早退回全量,心平气和 。
此外还有两条必须守住的工程底线:
- 失败绝不推进
last_successful_commit。一张SyncJob表记status / phase,失败时status = failed,last_successful_commit保持不变。哪怕中间失败 10 次,下次触发仍从上次成功点继续 diff,不会漏文件。 - 给 panic 一条生路 。
defer recover()把 panic 兜成 failed,否则一次 OOM 能把后续所有增量同步带崩——更惨的是状态表里留一个"永远 running"的脏记录,没人敢重启。
10.5 真实性能收益
一个几万行 Go 的中等仓库实测,全量约 3 分钟,增量能做到:
| 场景 | 增量耗时 | 提速 |
|---|---|---|
| 改 3 个文件 | ~5 秒 | 36× |
| 合并一个 PR(20 文件) | ~20 秒 | 9× |
| 切换到别的分支(>30% 变更) | — | 退回全量 |
瓶颈几乎永远在 embedding API—— 省下来的每一次 embed 调用,都是省下来的时间和钱 。
十一、从 DeepWiki 学到的:代码是 source of truth,文档该怎么活?
把代码库"搬进"一个可检索的知识库之后,一个更根本的问题就冒出来了:
既然代码加上从代码推导出来的 wiki,已经能回答 80% 的"这个项目是干什么的 / 这段逻辑从哪来",那我们过去精心维护的那些项目文档,还该不该写、该怎么写?
DeepWiki 的回答很激进:代码才是 source of truth,文档是代码的投影。 这个观点看似极端,但我认真想过之后,越来越觉得它指了一条更可持续的路。
11.1 传统文档的四个老毛病
先吐槽,以免下面的方案听起来像"空中楼阁"。我见过绝大多数团队的文档有这四个通病:
- 一写完就过时:README 停在 v0.1,API 文档停在上一季,实际代码早已另起炉灶。
- 信息双写:代码里改了参数,文档里忘了改;注释写一遍,wiki 再抄一遍。
- 搜索靠运气:Confluence 里三年前的设计文档、聊天记录里的"最终方案"、代码里的真实实现——三处不一致,问了新人也不知道信哪个。
- "没人看" 的自证预言:因为不准所以没人看,因为没人看所以更没人维护——死循环。
DeepWiki 和代码知识库的存在,直接把第 1、2 条釜底抽薪。但它们替代不了第 3、4 条对应的那部分文档——也就是代码里不体现的东西。
11.2 DeepWiki 值得借鉴的四个核心理念
把 DeepWiki 抽象一下,有四点特别值得搬进自家项目:
- 代码优先(Code-first):任何结论都得能点进某个
file:line,否则就是空口说白话。 - 自动化(Auto-generated):从代码推导出来的那一部分文档,绝对不手写,也绝对不人工审校文字,你审的是"生成规则",不是生成结果。
- 结构化(Structured):Repo Overview → Module → File → Function,层级清晰,可检索可引用。
- 对话式(Conversational):不是让人读完整本手册再干活,而是"带着问题来,带着答案+引用走"。
这四条看起来朴素,但每一条都是在跟过去十年的文档习惯对着干——习惯了改 wiki 改了十年的团队,最难接受的就是第二条。没关系,先从一个小项目开始试,感受一下"文档不用手改"的爽,你就回不去了。
11.3 四层文档架构:哪些该自动生成,哪些必须人写
我的建议是,把项目文档按"变化频率"和"能否从代码推导"分成四层,每层走不同的维护策略:
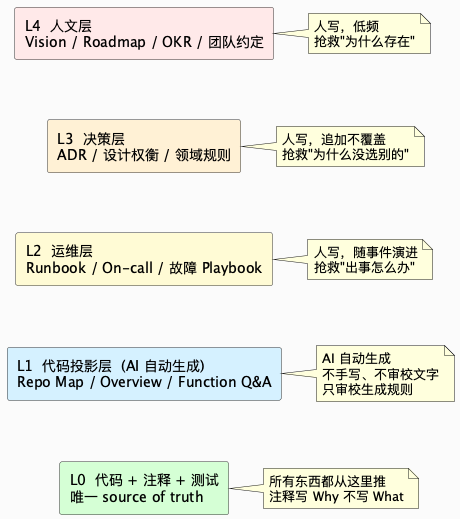
各层的取舍如下:
| 层 | 内容 | 维护方式 | 变化频率 | 典型载体 |
|---|---|---|---|---|
| L0 代码 + 注释 + 测试 | 实现本身 | 人写,注释只写 Why | 高 | Git 仓库 |
| L1 代码投影层 | Repo Map / 模块概览 / 函数 Q&A / 依赖图 | AI 自动生成,不手写 | 随 L0 自动刷新 | DeepWiki 风格 wiki |
| L2 运维层 | Runbook / On-call 手册 / 故障 Playbook | 人写,随事件演进 | 中 | Confluence / Git |
| L3 决策层 | ADR(架构决策记录)/ 设计权衡 / 领域规则 | 人写,追加不覆盖 | 低 | 仓库内 docs/adr/ |
| L4 人文层 | Vision / Roadmap / OKR / 团队约定 | 人写,低频 | 极低 | Wiki / Notion |
几条判断原则:
- 能从代码推出来的,别人写。让 AI 生成 L1,你省下来的时间用来写 L2/L3。
- 代码不体现"为什么"。L3 的 ADR 是唯一能抢救"当初为什么这么选"的地方。哪怕再简陋,追加一条总比丢失要好。
- 运维知识不要只留在脑子里。L2 的 Runbook 关键在"出事的时候能找到"——放在离代码最近的地方(仓库内或 MkDocs),比散落在 IM 聊天记录里靠谱十倍。
- L1 永远不要人肉修订文字。发现生成结果不对,改 prompt、改召回、改过滤,而不是改生成后的文本——否则下次重建就全丢了。
11.4 ADR:代码知识库最大的"补充品"
ADR(Architecture Decision Record)这个东西特别重要,单独拎出来说。代码回答得了 "是什么"(what)和 "怎么做"(how),但回答不了 "为什么不选另一种"(why-not)。
一个最小 ADR 模板就够了:
# ADR-0007: 为什么用 pgvector 而不是 Milvus
Date: 2026-04-16
Status: Accepted
Deciders: @walter, @alice
[Context]
代码知识库需要一个支持 10M+ 向量、多租户隔离、能做 JOIN 的向量库。
[Decision]
选 pgvector。已有 Postgres 运维栈,无需新增基础设施。
[Consequences]
- (+) 复用现有备份、监控、权限体系
- (+) 可以和 Entity 元数据表 JOIN 过滤
- (-) ANN 性能略逊于 Milvus,但在 10M 规模下够用
- (-) HNSW 索引构建较慢,接受
[Alternatives Considered]
- Milvus: 性能更强但要单独运维一套
- Qdrant: Rust 性能好但团队没人熟
把 ADR 放在仓库 docs/adr/ 下,和代码一起走 code review,这才是真正可持续的架构文档。
11.5 让"问 wiki" 成为新的日常
有了 L0 ~ L4 的分层,配合代码知识库,团队的工作流可以演进成这样:
- 新人第一周:不再扔一堆链接让 ta 读,而是让 ta 直接和代码知识库对话——"这个服务的入口在哪?"、"登录流程经过哪些模块?",AI 带着
file:line回答,新人直接跳过去看源码。 - 设计评审前:先让 AI 基于当前代码库回答 "如果我要加 X 功能,影响哪些模块?",把"拍脑袋改动"变成"有图有真相"。
- 故障复盘:代码知识库给"是什么改变了",Runbook 给"该怎么处置",ADR 给"为什么当时这么设计"。三者合起来才是完整复盘。
文档不是更少了,是更聚焦了——人写的每个字都在回答"代码回答不了的问题",这才是文档该有的样子。
十二、最值得做的事:让知识库反过来 harness AI 编码
如果只把代码知识库用作"查询工具",那只发挥了 30% 的价值。它真正的威力,在于反过来成为 AI 编码的基础设施——让 Cursor / Copilot / Claude Code 生成的代码,符合你项目的规范,而不是符合"互联网平均水平"。
这个想法一点都不玄:今天大部分 AI 编码助手之所以"写得不像你们项目的代码",根本原因就是它缺上下文。上下文从哪来?就从代码知识库来。
12.1 AI 编码的四大痛点,本质都是"上下文不足"
现在用 AI 写代码,最让人抓狂的几个场景:
- 不知道项目已有的工具函数:让它写 "解析时间字符串",它立刻从零手撸一个,无视你项目里已有的
utils/time.go。 - 不遵守项目约定:你们项目所有 Service 都返回
(result, error),它偏给你生成panic或抛异常。 - 不懂领域规则:你的"订单状态机"有 8 个状态,它随手
if status == "paid"就改,完全没看 ADR 里那张图。 - 调用不存在的 API:幻觉调用了一个根本不存在的
repo.FindByUserID(),让你背调试锅。
这四条痛点,全都是"上下文不足" + "AI 不知道去哪找上下文" 导致的。代码知识库恰好是"项目上下文的结构化载体"——把它喂给 AI,问题立刻缓解一大半。
12.2 AI 编码增强闭环:知识库如何 harness AI
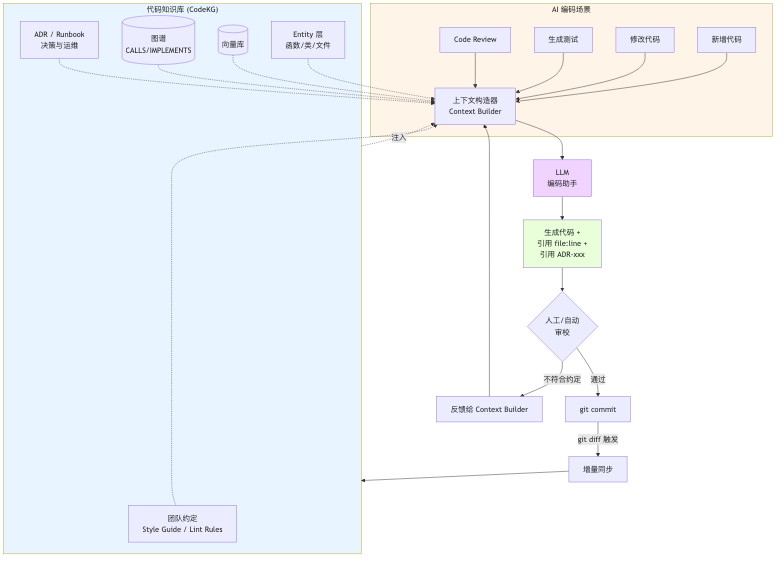
核心思路只有一句话:AI 生成代码前,先从知识库取出相关上下文拼进 prompt;AI 生成代码后,git commit 的 diff 又反哺回知识库。
这个闭环里有几个关键组件:
- Context Builder(上下文构造器):不是简单的 "RAG Top-K",而是按任务类型定制检索策略。
- 生成约束(Citation + Style):强制 AI 在输出里带
file:line引用和ADR-xxx引用。 - 增量同步回流:每次 commit 触发
git diff增量更新,让知识库永远反映最新的项目状态。 - 反馈回路:review 阶段发现 AI 违反了某条约定(比如又忘了加 ctx 参数),把这条约定固化到 Context Builder 的规则里,而不是骂一顿 AI 就完事。
12.3 针对不同编码任务,给 AI 喂不同的上下文
这是实操的核心。一刀切的 RAG 效果很差,得按任务类型配上下文:
| 任务类型 | Context Builder 要抓的东西 | 来自哪一层 |
|---|---|---|
| 新增功能 | 同目录的其他文件、Service 接口模板、相关 ADR | L0 + L1 + L3 |
| 修改代码 | 目标函数的调用方(图谱上游)+ 被调用方(图谱下游)+ 相关测试 | L0 + L1 graph |
| 重构 | 受影响的所有调用点、对应的单元测试、Style Guide | L0 + L1 + L4 |
| 修 bug | 报错栈涉及的函数及其上下游、最近 commit 的 diff、相似 bug 的历史 fix | L0 + L1 + Git |
| 写测试 | 被测函数签名、已有测试的风格、mock 基础设施 | L0 + L1 |
| Code Review | 改动点的调用链影响面、对应的 ADR / 安全规约 | L0 + L1 + L3 |
关键心法:改代码时,图谱比向量更重要。向量告诉你"谁长得像",图谱告诉你"改了这里会炸哪里"。AI 要做的是后者。
12.4 硬约束 Prompt:让 AI 不敢乱编
生成代码的 system prompt,该加几条像 SQL NOT NULL 那样的 硬约束 。骨架长这样(槽位填上面检索来的上下文):
规则:
1. 优先复用仓库已有函数——{similar_functions} 里有能用的必须调用。
2. 不要虚构 API——{available_apis} 里没有的就说 "不确定"。
3. 错误处理遵循项目约定 (来自 ADR-xxx)。
4. 涉及 {sensitive_areas} 的改动,必须先列出影响的调用方再动手。
上下文:
- 相似函数:{similar_functions}
- 调用方/被调用方:{graph_callers_callees}
- 相关 ADR:{relevant_adrs}
任务:{user_task}
其中 sensitive_areas (鉴权、支付、状态机转换)是性价比最高的那一项—— 让 AI 在这些区域先列影响面、再动手,能避免 80% 的"好心办坏事" 。 引用 file:line 和 "不确定就说不确定" 这两条第八节已经讲过了,这里只是把它们固化进 AI 编码场景。
12.5 落地路径:从 Cursor Rules 到内部 AI Agent
不是所有团队都能一上来就搞 AI Agent 平台,按投入从小到大,我建议分三步走:
第一步(一天上线):把知识库输出转成 Cursor/Claude Code 的 rules
把 ADR + Style Guide + 项目概览导出成 Markdown,放进 .cursor/rules/ 或 AGENTS.md。这样每次 AI 生成代码前都会"读过这些规则"。投入最小,收益立竿见影。
第二步(一周上线):给 IDE 插件做 MCP Server
把代码知识库包成一个 MCP Server(Model Context Protocol),暴露这几个 tool:
search_similar_functions(task_description)→ 向量检索get_callers(function_id)/get_callees(function_id)→ 图谱查询get_relevant_adrs(topic)→ 决策文档召回check_api_exists(symbol)→ 反幻觉校验
IDE 插件(Cursor / Claude Code)可以直接调这些 tool,AI 在推理中自己决定什么时候查知识库。这一步是最大的杠杆。
第三步(一季度上线):CI/CD 里的 AI 门禁
MR 提交时,自动用知识库上下文做一次 AI review,重点检查:
- 有没有重复造轮子(和
search_similar_functions召回结果比对) - 有没有违反 ADR
- 有没有"改了上游忘改下游"(用图谱做影响面分析)
- 敏感区域有没有对应的测试
把 AI 变成团队的"初级 reviewer",人类 reviewer 把精力放在设计和业务正确性上。
12.6 一条必须守住的底线:AI 是加速器,不是自动驾驶
讲到这里我得踩一脚刹车。 代码知识库 + AI 编码,不等于"不用人审" ,这话说十遍都不过分。几条血泪教训:
- AI 能 "更准地写代码" ,但它 不知道你昨天和 PM 在工位口头改了需求 。审 AI 输出时,先问 "需求对不对" ,再看 "代码对不对" ,顺序别反。
- AI 引用的
file:line, 一定要点进去看 。它会偶尔把函数名引对、行号给错一两位——和前面说的 LLM 幻觉是一个毛病,只是换了种姿势。 - 涉及 敏感操作 (删数据、改权限、发钱)的代码, 永远加一道人工闸门 。AI 越像那么回事,人越容易放松警惕,这种时候最容易出事。把 "AI 写的就一定靠谱" 当假设,跟把 "实习生写的就一定靠谱" 当假设没啥区别。
- 知识库本身要有 版本与可追溯 。某次生成出了问题,你得能回头查到当时 AI 拿到的是哪个 commit 的上下文,不然事故就是一场玄学。
一句话:代码知识库让 AI 变得"更像你们团队的同事",但它永远是那位需要人 review 的初级同事。靠谱的老同事不是不会出错,是知道哪里该停下来问一声。
十三、站在巨人肩上:三篇值得逐字读的论文
写到这里,其实没什么是我一个人拍脑袋想出来的。下面这三篇论文,是我在折腾这套东西的时候反复翻的"基石文献"。之所以单独列一节,不是为了凑参考文献,而是因为它们每一篇都能回答一个咱们绕不过去的问题。顺序是我推荐的阅读顺序,从"为什么"到"怎么做"。
13.1 LLMs for Knowledge Graph Construction and Reasoning(Yu et al., arXiv 2305.13168,2023)
回答的问题:LLM 到底在知识图谱这件事里能干啥、不能干啥?
作者跑了八个数据集,把 LLM 扔进 KG 的 抽取 / 补全 / 融合 / 推理 四个环节各测一遍,结论一句话:
LLM 是好的"推理助手",不是好的"少样本抽取器"。
说白了,你想让 GPT-4 替你从代码里一把把实体和边抽出来,它会偶尔惊艳、长期翻车;但你把图建好、把候选都摆在它面前,让它来回答 "runSync 是干啥的、为啥这么写" , 它比谁都会说人话 。他们后来还顺手提了个 AutoKG(多 agent + 外部源)的方案。
对我们的启发:别让 LLM 去担 "解析代码、建边" 这种脏活,那是 Tree-sitter + 正则干的事;把 LLM 留到检索结果拼好之后的 "翻译官" 位置。第八节说的"LLM 只是翻译官",不是我自己发明的个人偏好,是这篇论文在八个数据集上跑出来的。
13.2 RepoAgent: An LLM-Powered Framework for Repository-level Code Documentation Generation(Li et al., arXiv 2402.16667,EMNLP 2024 Demo)
回答的问题:项目级的代码文档,能不能自动生成并且随代码演进?
清华团队做的一个开源框架(GitHub 上开源在 OpenBMB/RepoAgent),三步:
- 全局结构分析:AST 解析,识别跨对象的调用/引用关系。
- 文档生成:不是给一个函数单独 "翻译" ,而是把它放进 全局上下文 (它的调用方、被调用方、所在模块)里一起喂给 LLM。
- Git 变更监听:A/M/D 触发对应对象的文档增量更新。
看到这三步有没有很眼熟?——这正是咱们前面第九节的时序图和第十节的增量同步策略。区别在于他们更聚焦"文档生成"这一个子问题,咱们多了图库和 AI 编码闭环。
对我们的启发:第十一节里那个大胆结论—— L1 永远别手改、只改 prompt 和召回——RepoAgent 的整条流水线就是这个理念的活样本。想找一个"活着的、正在被企业用"的参考实现,它是目前门槛最低的那个。
13.3 Code Graph Model (CGM): A Graph-Integrated LLM for Repository-Level Software Engineering(Tao et al., arXiv 2505.16901,NeurIPS 2025)
回答的问题:如果把代码图直接喂进 LLM,它能解决真实的 issue 吗?
CodeFuse 团队(蚂蚁集团)做的,思路很激进——不搞 agent 循环,直接把代码图当成 LLM 的一等公民输入。核心是 R4 chain:
| 组件 | 干啥 |
|---|---|
| Rewriter | 把用户的 issue 描述翻译成 "图里要找什么" |
| Retriever | 在代码图上以 anchor node 为中心,启发式取相关子图 |
| Reranker | 在子图的文件里,挑出最可能要改的那几个 |
| Reader | 可训练,基于图生成补丁 |
在 SWE-bench Lite 上拿到开源模型第一的 43% 解决率(V1.2 做到 44%)。更有意思的是, 他们证明了不做 agent、只靠更好的图检索就能打得很凶 ——agent 那套让 LLM 自己迭代的做法,未必是唯一解。
对我们的启发:第十二节里说 "改代码时图谱比向量更重要" ,CGM 直接用实验数据把这句话钉死了。如果你哪天想从 "回答问题的 DeepWiki" 升级到 "真的能替我改 bug 的 AI 工程师" ,CGM 就是下一步要抄的作业。
三篇串起来看 ,其实是在回答三个相互递进的问题: LLM 该干什么(Yu 2023)—— 工程上怎么把"生成"做稳(RepoAgent)—— 图建得够好时 LLM 能不能从助手变选手(CGM) 。三个台阶踩稳了,代码知识库这件事就不是玄学,是一条被顶会和工业界反复验证过的工程路径。剩下要做的只有两件: 把图建得再扎实一点,把检索拆得再细一层 。
十四、总结:一张思维导图看完整套体系
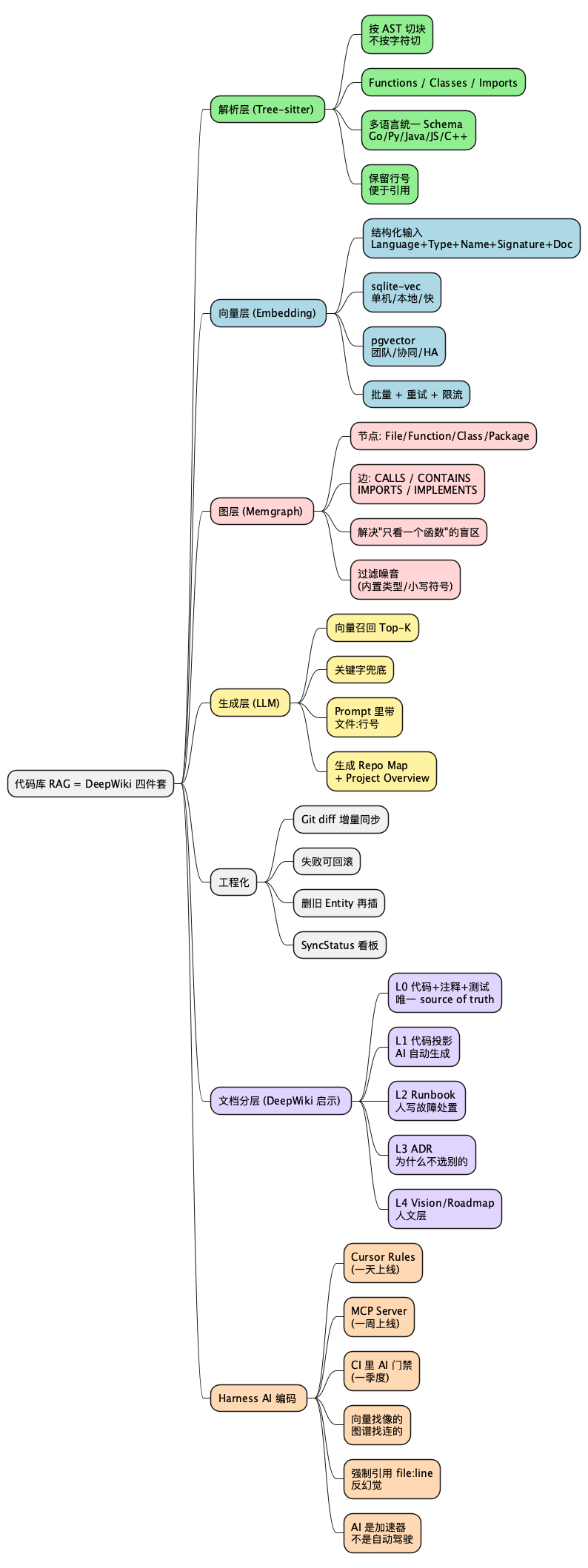
@startmindmap
<style>
mindmapDiagram {
.green * { BackgroundColor lightgreen }
.blue * { BackgroundColor lightblue }
.pink * { BackgroundColor #ffd4d4 }
.yellow * { BackgroundColor #fff3a0 }
.purple * { BackgroundColor #e0d4ff }
.orange * { BackgroundColor #ffd9b3 }
}
</style>
* 代码库 RAG = DeepWiki 四件套
** 解析层 (Tree-sitter) <<green>>
*** 按 AST 切块
*** 多语言统一 Schema
** 向量层 (Embedding) <<blue>>
*** 结构化输入
*** sqlite-vec / pgvector
** 图层 (Memgraph) <<pink>>
*** CALLS / CONTAINS / IMPORTS
*** 过滤内置类型噪音
** 生成层 (LLM) <<yellow>>
*** 向量 + 关键字混合
*** 强制引用 file:line
** 工程化
*** Git diff 增量同步
*** A/M/D/R 分状态处理
*** SyncJob 看板
** 文档分层 (DeepWiki 启示) <<purple>>
*** L0 代码 = source of truth
*** L1 AI 自动生成 wiki
*** L2 Runbook 人写
*** L3 ADR 抢救 why-not
*** L4 Vision 人文层
** Harness AI 编码 <<orange>>
*** Cursor Rules (一天)
*** MCP Server (一周)
*** CI AI 门禁 (一季度)
*** 图谱找"改这里会炸哪里"
*** AI = 初级同事 必须 review
@endmindmap
从零搭一套最小 DeepWiki 的 CheckList
照下面这十四条按序勾,基本能少走我走过的弯路:
解析与存储
- [ ] Entity schema 敲定:
id / repo_id / type / name / file / start_line / end_line / signature / doc / body / language; ID 用内容 hash,不用自增 。 - [ ] 遍历时 skip
vendor / node_modules / .git / dist / build,不然 embedding 账单能让你哭。 - [ ] Embedding 输入用结构化模板 (Language + Type + Name + Signature + Doc),别塞整段 body。
- [ ] 向量库按规模选 :<100 万 sqlite-vec,>100 万或多用户 pgvector;超大规模再考虑专用向量库。
- [ ] 图库用 Memgraph 或 Neo4j ;先建
CONTAINS / IMPORTS / CALLS三种边, 过滤内置类型与小写短符号 ,其余慢慢加。
检索与生成
- [ ] 检索做混合 :向量 Top-K + 关键字兜底 + 图上下游扩展;进阶再上 BM25 + RRF。
- [ ] Prompt 两条硬规矩 : 强制引用
file:line; system prompt 里明写 "If insufficient, say so" 。
增量同步(上生产的分水岭)
- [ ] 用
git diff --name-status增量 ,别用git log自己聚合;A/M/D/R 分状态处理,M必须先 DELETE 再 INSERT,不要 upsert 。 - [ ] 向量增量 + 图全量重建 ,避免悬空边;大范围改动(>30% 文件)或分支切换一律退回全量。
- [ ] 失败绝不推进
last_successful_commit,用SyncJob表记 status/phase;defer recover()兜住 panic,避免卡死。
文档与 AI 编码
- [ ] 文档四层分工 : L0 代码注释 / L1 AI 自动生成 / L2 Runbook / L3 ADR / L4 人文层; L1 永远不人肉改文字,只改 prompt 和召回 。
- [ ] 每次架构决策立即补 ADR ,放进
docs/adr/和代码一起走 code review。 - [ ] 先导
AGENTS.md/.cursor/rules/;再把知识库包成 MCP Server 暴露search_similar_functions / get_callers / check_api_exists等 tool。 - [ ] 敏感区域(鉴权/支付/状态机)AI 输出加人工闸门 ,永远别裸跑; 改代码时优先查图谱 ,比纯向量有效得多。
留给你的几个问题
- 你们团队的代码库,有没有一个"新人入职文档"的痛点?如果不靠人写文档,而靠从代码里自动生成,会不会更可持续?
- LSP 能拿到精确的调用关系,但集成复杂。用 regex 先跑起来,再慢慢升级到 LSP,这种 "先上车再买票" 的演进路径,你愿意接受吗?
- 如果只让你做一层,你选向量还是图?我选图——代码的灵魂在关系里,不在相似度里。相似度帮你找到"像谁",关系告诉你"牵一发动哪里",后者才是工程师每天真正缺的信息。
- AI 编码最让你抓狂的瞬间是哪一个?如果在 生成前 就把 "项目已有的同名函数""相关 ADR""调用方影响面" 喂给它,那次事故能避免吗?
欢迎评论区聊聊。写给新同事的一份 README,不如给新同事一个能对话的知识库——这不是在偷懒,而是把精力留在更值得写的那几页文档上。
扩展阅读
论文(按推荐阅读顺序)
- Yu et al. LLMs for Knowledge Graph Construction and Reasoning: Recent Capabilities and Future Opportunities. arXiv 2305.13168, 2023. https://arxiv.org/abs/2305.13168 — LLM 在 KG 四件事(抽取/补全/融合/推理)上能干啥、不能干啥的奠基综述
- Edge et al. From Local to Global: A Graph RAG Approach to Query-Focused Summarization. arXiv 2404.16130, 2024. https://arxiv.org/abs/2404.16130 | 代码:https://github.com/microsoft/graphrag — GraphRAG 的奠基论文,把 "社区检测 + 层次化摘要" 这套范式讲透
- Li et al. RepoAgent: An LLM-Powered Open-Source Framework for Repository-level Code Documentation Generation. arXiv 2402.16667, EMNLP 2024 Demo. https://arxiv.org/abs/2402.16667 | 代码:https://github.com/OpenBMB/RepoAgent — 项目级代码文档自动生成 + 增量更新的开源范例
- Tao et al. Code Graph Model (CGM): A Graph-Integrated LLM for Repository-Level Software Engineering Tasks. arXiv 2505.16901, NeurIPS 2025. https://arxiv.org/abs/2505.16901 | 代码:https://github.com/codefuse-ai/CodeFuse-CGM — 图 + LLM 在 SWE-bench Lite 上拿到开源第一的 R4 chain
工具与参考实现
- Tree-sitter 官方文档 — AST 解析的事实标准
- sqlite-vec — 把 SQLite 变成向量库的轻量扩展
- pgvector — Postgres 原生向量扩展,生态最强
- Memgraph Documentation — Cypher 兼容的内存图数据库
- DeepWiki by Cognition — 看看"成品"长什么样
- Sourcegraph Cody Architecture — 工业级代码搜索与 QA 的设计思路
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。