什么是 Louvain 算法——graphology-communities-louvain 背后的那点事
Posted on 一 20 4月 2026 in Journal
| Abstract | Louvain 社区发现算法的原理、实现与工程取舍 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-04-20 |
| License | CC-BY-NC-ND 4.0 |
什么是 Louvain 算法——graphology-communities-louvain 背后的那点事
短大纲
- 开头:一个"谁和谁是一伙的"真实场景,为什么你需要社区发现
- 直觉:Louvain 到底在优化什么——模块度(Modularity)
- 两阶段循环:局部挪一挪,全局缩一缩
- graphology-communities-louvain 的最小可运行例子
- 参数与坑:
resolution、随机性、权重图、有向图 - 什么时候别用 Louvain(Leiden、Label Propagation、Infomap 的取舍)
- 工程落地 CheckList
一张图摆面前,你要怎么下手
前几天一位朋友拉我看他的项目:他把公司内部 Slack 几个月的 @mention 关系建成了一张图,节点是人,边是"你 @ 过我"。两万多节点,十几万条边。他问:"能不能自动告诉我这里面有几个部门/小团体?"
这不是社交网络专属问题。你把它换一下皮就遍地都是:
- 电商里用户和商品共同出现的二部图——自动归类"喜欢相似东西的人"
- 代码依赖图——把一个巨型 monorepo 自动拆成高内聚的模块
- 金融反欺诈——一群共享手机号、设备、IP 的账号,自动抱团
- 知识图谱——相关实体聚成主题簇,喂给 RAG 做粗召回
问题的学名叫 社区发现(Community Detection):在一张图里找到若干子集,使得子集内部边很密、子集之间边很稀。听起来简单,算起来要命——因为"怎么分"本身是个组合爆炸问题,全局最优是 NP-hard。
而 Louvain 算法,就是 2008 年比利时鲁汶大学(Université catholique de Louvain,算法因此得名)那帮人搞出来的近似解。它不追求最优,它追求又快又好。快到什么程度?百万级节点,单机分钟级能跑完。这也是为什么 Gephi、NetworkX、igraph、Neo4j GDS、graphology 都把它作为默认社区发现算法。
Louvain 到底在优化什么:模块度
要看懂 Louvain,先得看懂它盯着的那个"分数"——模块度(Modularity, Q)。
一句话人话版:"实际连接强度"减去"随机情况下的期望连接强度"。 分数越高,说明这种分组相比"瞎分"越显著。
公式长这样:
[ Q = \frac{1}{2m} \sum_{i,j} \left[ A_{ij} - \frac{k_i k_j}{2m} \right] \delta(c_i, c_j) ]
别急,一项项拆:
- (A_{ij}):节点 i 和 j 之间真实的边权(无边就是 0)
- (k_i):节点 i 的度数(所有连出去的边权之和)
- (m):图里所有边权之和
- (\frac{k_i k_j}{2m}):如果我把所有边打散重连,i 和 j 之间期望有多少边。这是所谓的"零模型"
- (\delta(c_i, c_j)):i 和 j 在同一个社区就是 1,否则是 0
所以 Q 在问:"同社区内部的实际边,比随机情况下多出了多少?"
- Q ≈ 0:你这分法跟瞎猜差不多
- Q > 0.3:开始有点意思了
- Q > 0.7:社区结构非常明显(现实世界很少达到,除非图本身就很"分块")
Louvain 就是一个不断调整分组来贪心地提高 Q 的过程。
两阶段循环:局部挪一挪,全局缩一缩
Louvain 的精髓,不在模块度公式,而在它怎么优化。它用了一个特别朴素但特别有效的两阶段循环:
@startuml
!theme plain
skinparam backgroundColor #FFFFFF
start
:每个节点单独是一个社区;
repeat
:Phase 1: 局部移动;
note right
遍历每个节点,
尝试把它加入"邻居所在社区",
选 ΔQ 增益最大的那个。
反复扫直到没有节点再能受益。
end note
:Phase 2: 社区折叠;
note right
把同一社区内的节点合并成一个"超级节点",
社区之间的边变成超级节点之间的加权边。
然后回到 Phase 1。
end note
repeat while (ΔQ > 阈值?) is (是)
->否;
:输出最终社区划分;
stop
@enduml
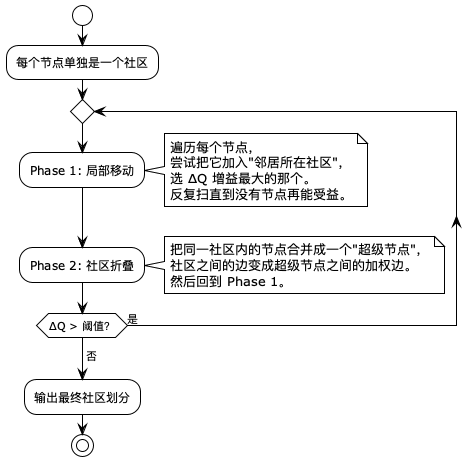
Phase 1(局部移动):每个节点看看自己的邻居,计算"我搬到邻居 X 所在的社区,Q 能涨多少?"选涨得最多的那个社区搬过去。没有增益就原地不动。一轮一轮扫,直到没人愿意动了。
Phase 2(社区折叠):把当前所有社区"压扁"成一个节点。原来社区内部的边变成自环(带权),社区之间的边变成两个超级节点之间的加权边。得到一张更小的新图。
然后——在这张新图上,再跑一次 Phase 1。
这就是整个算法的灵魂:"先在小尺度上搞清楚谁和谁抱团,然后把抱好团的当成一个整体,去解决更大尺度的抱团问题"。像不像公司架构?先分小组,小组长开会决定部门怎么分,部门总监再开会决定事业部怎么分。Louvain 就是这么一层层"官僚"上去的。
这也解释了它为什么快:每一轮迭代,图都在指数级缩小。一百万节点的图,跑三四轮可能就缩成几千个"超级节点"了。
一个极简例子
假设有 6 个人,连接关系如下:
graph G {
layout=neato
node [shape=circle, style=filled, fillcolor="#FFE4B5"]
A -- B
A -- C
B -- C
D -- E
D -- F
E -- F
C -- D [style=dashed, color=gray]
}
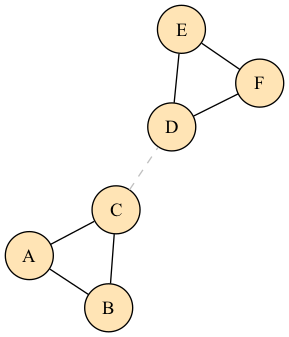
肉眼一看,{A, B, C} 是一团,{D, E, F} 是一团,C—D 那条虚线是连接两团的"桥"。Louvain 跑一遍:
- Phase 1:A 试着加入 B 或 C 所在社区,ΔQ 为正,合并;D、E、F 同理合并。C 要不要加入 D 所在社区?算一下 ΔQ——因为 C 和 {A, B} 之间有 2 条边,和 {D, E, F} 之间只有 1 条,留在原地 Q 更高,不动。
- Phase 2:{A, B, C} 压成一个超级节点,{D, E, F} 压成一个超级节点,两者之间一条权重为 1 的边。
- Phase 1(第二次):两个超级节点要不要合并?不合并的 Q 更高,不动。收敛。
最终输出:两个社区。干净利落。
graphology-communities-louvain:JS 生态里的那把趁手刀
说完原理,轮到工程实操。如果你在 Node.js / 浏览器里画关系图,graphology 几乎是绕不过的库——它是一套"图数据结构 + 算法生态",跟 D3、Sigma.js 生态打通得最好。
Louvain 的实现在独立包 graphology-communities-louvain 里。
最小可运行例子
npm install graphology graphology-communities-louvain
import Graph from 'graphology';
import louvain from 'graphology-communities-louvain';
const graph = new Graph();
['A', 'B', 'C', 'D', 'E', 'F'].forEach(n => graph.addNode(n));
graph.addEdge('A', 'B');
graph.addEdge('A', 'C');
graph.addEdge('B', 'C');
graph.addEdge('D', 'E');
graph.addEdge('D', 'F');
graph.addEdge('E', 'F');
graph.addEdge('C', 'D');
const communities = louvain(graph);
console.log(communities);
// { A: 0, B: 0, C: 0, D: 1, E: 1, F: 1 }
console.log('Modularity:', louvain.detailed(graph).modularity);
三行核心代码:建图、加边、调用 louvain(graph)。返回一个 { node: communityId } 的字典。就这么直给。
加权图、分辨率、随机种子
真实场景里,边往往带权重(通信次数、交易金额、相似度分数),而且你希望结果可复现。这时候就要用到 Louvain 的参数:
import louvain from 'graphology-communities-louvain';
graph.addEdge('A', 'B', { weight: 5 });
graph.addEdge('B', 'C', { weight: 2 });
// ...
const communities = louvain(graph, {
getEdgeWeight: 'weight',
resolution: 1.0,
randomWalk: false,
rng: () => 0.5,
});
几个参数要特别注意:
getEdgeWeight:告诉它去哪个属性读权重。不设置就当无权图处理。resolution(分辨率参数 γ):大于 1 倾向于更多、更小的社区;小于 1 倾向于更少、更大的社区。默认是 1。这个参数背后是模块度的一个变体 (Q_\gamma),是 Louvain "解决不了小社区(resolution limit)"问题的一个常见补丁。rng:Louvain 的节点遍历顺序会影响结果,传一个固定的随机数生成器可以让结果可复现。线上系统很需要这个。.detailed():返回{ communities, modularity, count, resolution, ... },比直接调用多给你一堆指标。做调优的时候用这个。
一个容易踩的坑:多次运行结果不一样
新手最常见的困惑:"我跑两次怎么社区数量都不一样?"
这是特性,不是 bug。Louvain 是贪心算法,节点扫描顺序不同,局部最优解就不同。解决办法:
- 固定
rng(上面提过) - 多跑几次,挑 modularity 最高的那次(
louvain.detailed(graph)拿到分数) - 升级到 Leiden 算法(后面讲)
什么时候别用 Louvain
这是全文最值钱的部分。Louvain 再好,也有三大死穴:
1. 分辨率极限(Resolution Limit)
模块度天生偏爱"大社区"。当你的图里有很多小而紧密的社区时,Louvain 会把它们强行合并,哪怕它们内部结构明显不同。典型表现:你凭经验知道应该有 50 个小圈子,Louvain 给你合成 10 个大圈子。
补救:调大 resolution,或者换 Leiden。
2. 可能产生"内部断裂"的社区
Louvain 的 Phase 1 是节点级别的贪心移动,它不保证一个社区在图上真的是连通的。你有概率拿到一个"这几个人被分到同一个社区,但他们之间其实根本没连通"的诡异结果。
补救:用 Leiden 算法。Leiden 是 2019 年 Traag 等人对 Louvain 的改进,核心改动是在 Phase 1 之后加了一步"社区内部再分裂检查",从数学上保证每个社区都是连通的,而且 modularity 通常还更高一点。graphology 生态里有 graphology-communities-leiden 对应实现。如果你不确定选哪个,默认选 Leiden。
3. 有向图与异质图
Louvain 原生是为无向、加权图设计的。有向图(比如 Twitter follow 关系)强行跑一遍也能出结果,但模块度公式的"零模型"就不太对路了。
补救:要么把有向边折叠成无向(损失信息),要么用 Infomap 这种基于随机游走和信息论的算法——它天生支持有向图,对"信息流动结构"特别敏感。
一张对比速查表
| 算法 | 最适合的场景 | 缺点 |
|---|---|---|
| Louvain | 无向加权大图,追求速度和够用就行 | 分辨率极限,社区可能不连通,结果不稳定 |
| Leiden | 同 Louvain,但要求更稳、更好 | 实现更复杂,略慢 |
| Label Propagation | 超大图,只要求粗粒度划分 | 结果极度依赖随机性,质量较差 |
| Infomap | 有向图、追求"信息流"结构 | 慢,参数不直观 |
| GNN 聚类(如 DMoN) | 节点有丰富特征,追求语义社区 | 需要训练、算力、调参 |
工程落地 CheckList
攒了这么多,最后给一个小抄清单:
- [ ] 先看数据规模:节点 <1k,管他用啥都行;1k–10M,Louvain/Leiden;>10M,考虑分布式(PowerGraph、GraphX)。
- [ ] 有向图别直接套 Louvain:先想清楚方向信息要不要,要就用 Infomap,不要就手动转无向并小心处理权重。
- [ ] 默认用 Leiden:如果你的库支持,优先 Leiden。
graphology-communities-leiden/python-igraph的la.leiden/cdlib都行。 - [ ] 固定随机种子:生产环境每次结果必须可复现,否则出报告都是灾难。
- [ ] 先跑一次看 Q:Q < 0.3 就说明这图本来社区结构就不明显,别硬 claim;Q > 0.4 再认真解读结果。
- [ ] 调
resolution做敏感性分析:从 0.5 到 2.0 扫一遍,看社区数量怎么变化,挑业务上讲得通的那个点。 - [ ] 社区大小要做截断:跑完往往有一堆 size=1 或 size=2 的碎屑社区,业务上一般当"其他"处理。
- [ ] 可视化用力:用 Sigma.js / Gephi / ForceAtlas2 画出来给产品看,数值人一般不买账,图他们会买账。
总结
Louvain 不是魔法,它只是把"社区发现"这个 NP-hard 问题用两个朴素循环做了一个又快又够用的贪心近似。理解了它,你就理解了半个图算法工程的路子——"全局最优拿不到?那就找一个稳定的局部最优,让它跑得快、结果能解释"。
graphology-communities-louvain 是把它搬到前端 / Node.js 的那个趁手工具,但请记住三件事:默认用 Leiden、固定随机种子、别无脑信 Q。
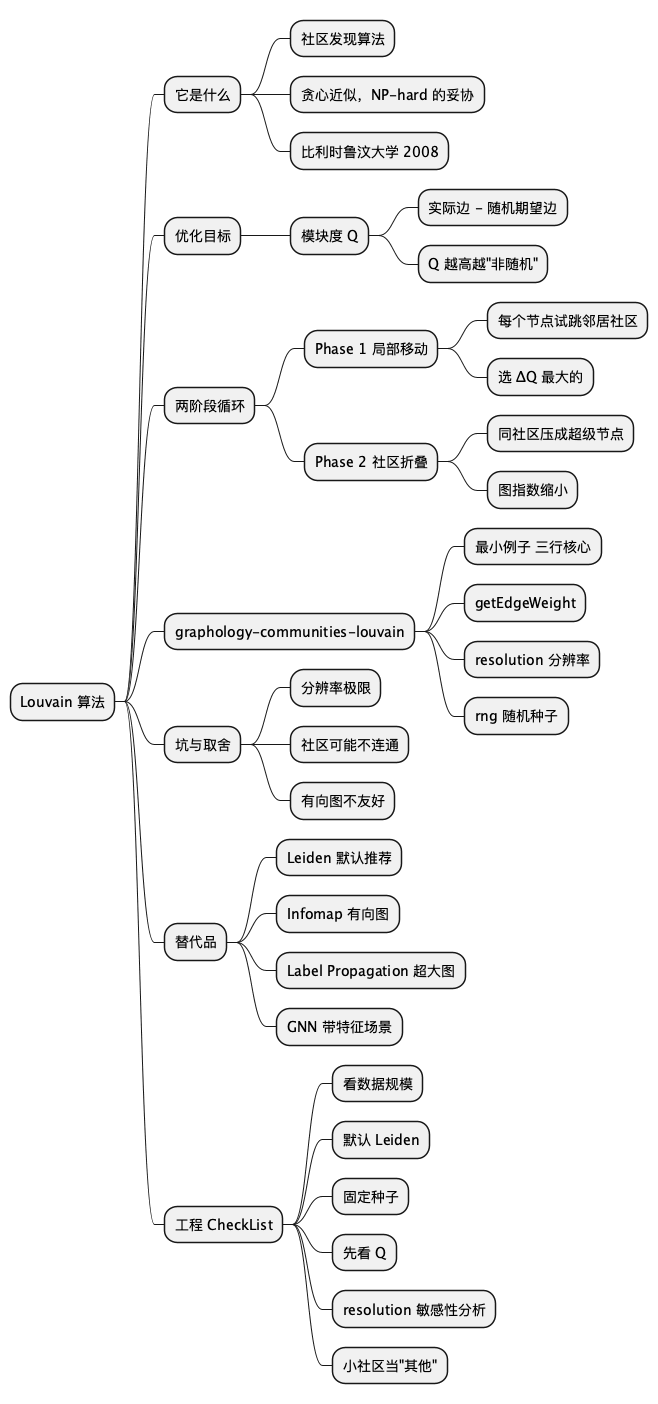
最后,一张思维导图帮你收纳本文:
@startmindmap
* Louvain 算法
** 它是什么
*** 社区发现算法
*** 贪心近似,NP-hard 的妥协
*** 比利时鲁汶大学 2008
** 优化目标
*** 模块度 Q
**** 实际边 - 随机期望边
**** Q 越高越"非随机"
** 两阶段循环
*** Phase 1 局部移动
**** 每个节点试跳邻居社区
**** 选 ΔQ 最大的
*** Phase 2 社区折叠
**** 同社区压成超级节点
**** 图指数缩小
** graphology-communities-louvain
*** 最小例子 三行核心
*** getEdgeWeight
*** resolution 分辨率
*** rng 随机种子
** 坑与取舍
*** 分辨率极限
*** 社区可能不连通
*** 有向图不友好
** 替代品
*** Leiden 默认推荐
*** Infomap 有向图
*** Label Propagation 超大图
*** GNN 带特征场景
** 工程 CheckList
*** 看数据规模
*** 默认 Leiden
*** 固定种子
*** 先看 Q
*** resolution 敏感性分析
*** 小社区当"其他"
@endmindmap
扩展阅读
- Fast unfolding of communities in large networks — Louvain 原始论文(2008)
- From Louvain to Leiden: guaranteeing well-connected communities — Leiden 论文,讲清了 Louvain 的坑
- graphology-communities-louvain 文档 — 本文用的库
- graphology-communities-leiden — Leiden 实现
- Gephi 的 Modularity 教程 — 可视化视角理解社区发现
- CDlib: Community Discovery Library — Python 生态里最全的社区发现算法合集
- The Map Equation(Infomap 官网) — 有向图社区发现的另一条路
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。