Obsidian 加 LLM,个人知识库的正确打开方式
Posted on 三 08 4月 2026 in Journal
| Abstract | Obsidian 加 LLM,个人知识库的正确打开方式 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-05-10 |
| License | CC-BY-NC-ND 4.0 |
Obsidian 加 LLM,个人知识库的正确打开方式
短大纲
- 一句话:Obsidian 的本地 Markdown 文件,天然就是 LLM 最容易吃进去的格式。个人知识库不是"给笔记工具加个 AI 按钮",而是把你的本地文件系统变成 LLM 的工作目录。
- 三种集成模式:插件式(Smart Connections / Copilot)、MCP 式(Claude Code / Cursor 直连 vault)、编译式(Karpathy 的 LLM Wiki 思路)。按需选,可以组合。
- 核心观点:知识库的价值不在于存了多少,而在于你能多快找到、串起来、用出去。LLM 是加速器,但目录结构和写作习惯才是地基。
正文
你的笔记在哪里
干了二十多年程序员,我最怕的事情之一就是"找笔记"。
Evernote 里有一批,Notion 里有一批,公司 Confluence 里有一批,本地散落着几十个 .md 和 .txt,微信收藏夹还有一堆"稍后再看"。每次想找某个技术方案,先得回忆"我当时是记在哪里的",这个回忆过程本身就已经消耗了一半的耐心。
更痛的是,现在 AI 这么强,ChatGPT、Claude 什么都能聊,可它们对你的笔记一无所知。你问它"我上次那个 Redis 集群迁移的方案是什么",它只能一脸无辜地说"我没有这个上下文"。
问题出在哪?你的知识散落在 N 个平台和格式里,没有任何一个 AI 能同时看到它们。
在 AI 时代之所以选、 Obsidian 的原因——不是因为它最漂亮,也不是因为它功能最多,而是因为它做了一个在 AI 时代变得格外重要的决定:所有内容就是本地目录里的 Markdown 文件,不多不少。
为什么 Obsidian 是 AI 时代的好底座
市面上笔记工具几十种,为什么偏偏 Obsidian 适合拿来做 LLM 知识库?说到底就三条:
第一,纯文本,LLM 天然能吃。 Obsidian 的 vault 就是一个文件夹,里面全是 .md 文件。不需要导出、不需要 API、不需要格式转换。你把文件夹路径丢给 LLM,它直接就能读。这个看似简单的特性,在实际使用中省掉了巨大的摩擦——Notion 的笔记要先通过 API 导出,Evernote 的笔记格式更是一言难尽。
第二,本地优先,数据在你手里。 你的日记、工作笔记、技术方案、个人反思,这些东西你未必希望全传到云上让某个 AI 公司帮你"分析"。Obsidian 的数据就在你的硬盘上,配合本地 LLM(比如 Ollama 跑 Llama),从头到尾数据都不出你的电脑。
第三,双向链接和标签构成了天然的知识图谱。 Obsidian 的 [[双向链接]] 和 #标签 不只是好看的功能,它们本质上是结构化元数据。当 LLM 在你的 vault 里搜索时,这些链接关系能帮它理解"哪些笔记和哪些笔记有关",比纯粹的全文搜索精准得多。
一句话总结:Obsidian vault = 一个 LLM 友好的、带结构化链接的、本地 Markdown 文件系统。 这不是笔记工具的巧合,这是 AI 时代的刚需。
先把目录理清楚——地基比工具重要
在折腾各种 AI 插件之前,先做一件更重要的事:把你的 vault 目录结构想清楚。
很多人一上来就装插件、调模型,结果 vault 里的笔记命名混乱、分类模糊、标签体系三天两头改。AI 再聪明,面对一个乱七八糟的文件夹,也只能给你乱七八糟的回答。
我自己用了一段时间,摸出来一个还算顺手的结构:
vault/
├── 0-inbox/ # 速记、剪藏、待整理的碎片
├── 1-journal/ # 日志、周报、随想
├── 2-projects/ # 按项目组织的工作笔记
├── 3-areas/ # 持续关注的领域(技术、健康、理财等)
├── 4-resources/ # 参考资料、读书笔记、课程笔记
├── 5-archive/ # 已完成/不再活跃的内容
├── templates/ # 笔记模板
└── attachments/ # 图片、PDF 等附件
这个结构借鉴了 PARA 方法(Projects / Areas / Resources / Archive),加了一个 inbox 做缓冲。关键点不在于目录名叫什么,而在于:
- 每篇笔记有且只有一个"家",不用纠结"这篇到底放哪"。
- inbox 是临时中转站,定期清理,不让它变成垃圾场。
- 文件名带日期前缀(如
2026-04-08_obsidian-llm.md),方便排序和去重。
另外,给每篇笔记加上 YAML frontmatter 是个好习惯:
---
title: Obsidian 加 LLM 实践
date: 2026-04-08
tags: [obsidian, llm, knowledge-base]
status: draft
---
这些元数据看起来是给自己看的,其实 AI 插件也会读。tags 帮 AI 理解主题,status 帮你过滤哪些笔记是成熟的、哪些还在草稿阶段。
三种模式:从轻到重
好了,地基打好了,现在聊怎么接入 AI。按侵入性从低到高,大致有三种模式。
模式一:Obsidian AI 插件——最省心的起步
如果你只想"在 Obsidian 里能和 AI 聊天,而且 AI 知道我的笔记内容",装个插件就够了。目前比较成熟的有两个:
Smart Connections:核心能力是语义搜索。它把你的笔记做 embedding(向量化),然后你问问题时,它用 RAG(检索增强生成)的方式,先找到相关笔记,再让 LLM 基于这些笔记回答。
- 自带本地 embedding 模型(bge-micro-v2),不需要 API key 也能用
- 搜索结果会显示"和当前笔记相关的其他笔记",用来发现笔记之间的隐藏关联很有用
- 所有 embedding 数据存在 vault 本地(
.smart-env/目录)
Copilot:更像一个聊天助手。它在侧边栏提供 Chat 界面,你可以和它对话,它会检索你的 vault 内容来回答。
- 支持多种模型(OpenAI、Claude、本地 Ollama 等)
- 有 ghost-text 自动补全功能,写笔记时能给建议
- 设置相对简单
两者怎么选?简单说:Smart Connections 擅长"发现",Copilot 擅长"对话"。 前者帮你找到你自己都忘了的笔记和关联,后者帮你针对具体问题快速得到答案。两个一起装也不冲突。
不过有一点要提前想好:这些插件的 embedding 索引需要时间和算力。 如果你的 vault 有上万篇笔记,第一次建索引可能要跑几分钟到十几分钟(M 系列 Mac 快一些)。之后每次只增量更新修改过的文件,就快多了。
模式二:MCP 打通外部 AI Agent——给 AI 一把钥匙
如果你平时用 Claude Code、Cursor 这些带 Agent 能力的 AI 工具写代码、做分析,那有一个更强大的玩法:用 MCP(Model Context Protocol)把你的 Obsidian vault 暴露给 AI Agent。
MCP 是 Anthropic 在 2024 年底推出的开放协议,到现在已经成为 AI 工具和外部数据源之间的标准接口。简单说,它让 AI Agent 能够通过标准化的方式读写你的文件、搜索你的笔记、遍历你的知识图谱。
具体怎么做?装一个 Obsidian MCP Server。目前比较成熟的有 obsidian-mcp-pro(23 个工具,支持图谱遍历和标签索引)和 obsidian-ts-mcp(37 个工具,覆盖笔记管理、搜索、元数据等)。
配置大致长这样(以 Claude Code 为例):
{
"mcpServers": {
"obsidian": {
"command": "npx",
"args": ["-y", "obsidian-mcp-pro"],
"env": {
"OBSIDIAN_VAULT_PATH": "/Users/yourname/obsidian-vault"
}
}
}
}
配好之后,你在 Claude Code 或 Cursor 里就能直接说:
- "帮我搜一下 vault 里关于 Redis 集群迁移的笔记"
- "把今天的会议纪要写成一篇笔记,保存到 1-journal 目录"
- "分析一下我最近一个月的日志,有什么反复出现的主题"
这种模式的好处是 AI Agent 能直接读写你的 vault,不只是搜索和回答,还能帮你创建笔记、整理内容、更新链接。坏处是你得信任这个 Agent 不会把你的笔记搞乱——所以建议先在一个测试 vault 里跑一跑,确认行为符合预期再用在主 vault 上。
模式三:编译式知识库——Karpathy 的 LLM Wiki 思路
这是目前最"硬核"的玩法,也是我觉得最有前途的方向。
2025 年,Andrej Karpathy 提出了一个思路叫"LLM Wiki"——不是让 AI 每次都从原始笔记里检索答案(传统 RAG),而是让 AI 把原始材料编译成一个结构化的 wiki。
传统 RAG 的问题在于:每次你问一个问题,AI 都要重新搜索、重新理解、重新组织。它没有"记忆",也没有"积累"。就像每次考试都要从头翻课本,而不是翻自己整理好的笔记。
LLM Wiki 的做法不一样,它分三步:
raw/ ──→ wiki/ ──→ outputs/
(原始材料) 编译 (结构化 wiki) 查询 (回答/报告)
- raw/ ——丢进去你的原始材料:网页剪藏、PDF、会议纪要、碎片笔记,什么格式都行。
- wiki/ ——让 LLM 读 raw 里的内容,写成百科全书式的 wiki 页面:有标题、有摘要、有双向链接、有来源标注。这一步是"编译",不是一次性的,而是增量更新。
- outputs/ ——当你需要回答问题或生成报告时,AI 在 wiki 里搜索,而不是去翻 raw。
这个思路的精髓在于:wiki 是 LLM 自己写的、自己维护的、人可读的 Markdown 文件。 不是黑箱的向量数据库,不是你看不懂的 embedding。你随时可以打开任何一篇 wiki 页面,检查 AI 的理解对不对,必要时手动修正。
在 Obsidian 里实践这个思路,你可以这样组织:
vault/
├── raw/ # 原始材料(剪藏、PDF、粗笔记)
├── wiki/ # LLM 编译生成的结构化页面
│ ├── concepts/ # 概念解释
│ ├── howto/ # 操作指南
│ └── decisions/ # 决策记录
├── outputs/ # 生成的报告、摘要等
└── scripts/ # 编译脚本
编译脚本可以是一个简单的 Python 脚本,遍历 raw/ 目录里的新文件,调用 LLM API 生成 wiki 页面:
import os
from pathlib import Path
from openai import OpenAI
client = OpenAI()
RAW_DIR = Path("raw")
WIKI_DIR = Path("wiki/concepts")
SYSTEM_PROMPT = """你是一个知识库编译器。
给你一份原始材料,请提取关键概念,写成一篇结构化的 wiki 页面。
要求:
- 标题用 # 开头
- 开头有一段 50 字以内的摘要
- 用 [[双向链接]] 标注相关概念
- 末尾标注来源文件
- 输出纯 Markdown"""
def compile_to_wiki(raw_file: Path):
content = raw_file.read_text(encoding="utf-8")
response = client.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": SYSTEM_PROMPT},
{"role": "user", "content": content},
],
temperature=0.3,
)
wiki_name = raw_file.stem + ".md"
(WIKI_DIR / wiki_name).write_text(
response.choices[0].message.content, encoding="utf-8"
)
for f in RAW_DIR.glob("*.md"):
if not (WIKI_DIR / (f.stem + ".md")).exists():
compile_to_wiki(f)
print(f"compiled: {f.name}")
这只是一个起步版本。实际用的时候,你还需要增量检测(只编译新增或修改过的文件)、冲突处理(wiki 页面已存在时怎么合并)、以及定期的"lint"步骤——让 LLM 检查 wiki 的一致性和完整性。
我自己就用类似流程整理过一批 WebRTC 相关笔记。原来它们是一堆散落的 Markdown 文件:有的是 ICE、DTLS、SRTP 的概念摘录,有的是 SDP offer/answer 的排查记录,还有一些是会议媒体链路里的零碎经验。单独看每篇都还有点用,放在一起就像一个没人整理过的仓库,东西都在,但找起来全靠缘分。
后来我把这些原始笔记先按主题粗分,再让 LLM 编译成 wiki 页面:每篇页面只讲一个核心概念,保留来源文件,并用双向链接把相关主题串起来,比如 [[ICE]]、[[DTLS]]、[[SRTP]]、[[SDP]]、[[Jitter Buffer]]。编译完之后,知识不再是"一堆文件",而变成了一张能顺着查下去的网。要排查一个媒体连接问题时,我可以从 [[ICE Candidate]] 一路跳到 [[NAT Traversal]]、[[TURN]]、[[Connectivity Check]],比在文件夹里翻旧笔记舒服多了。
这件事让我意识到:LLM 最有价值的地方,不是替我凭空写知识,而是把我已经积累的碎片重新编排成结构。它像一个有耐心的图书管理员,不一定比你更懂 WebRTC,但它很擅长把散落在地上的书捡起来、分类、贴标签、放回架子。
我自己的搭配
说了三种模式,我自己怎么用的?坦白说,没有哪一种是银弹,我是组合着来的:
- 日常写笔记:Obsidian + Copilot 插件。写的时候偶尔问一下"我之前关于这个主题写过什么",它能帮我翻出来。
- 写代码时查笔记:Cursor + MCP 连 vault。写代码的时候不想切窗口,直接在 IDE 里问"我上次那个连接池配置怎么写的",它能找到我的笔记并且引用出来。
- 整理知识:每周花半小时,把 inbox 里的碎片用编译脚本跑一遍,生成 wiki 页面,再人工过一遍。
说实话,第三步我经常偷懒。但只要能坚持做,效果确实比单纯的搜索好——因为 wiki 页面是"精炼过的知识",而 raw 里的碎片是"原始信息"。前者查起来快,也更容易串联。
把旧笔记搬进来——迁移实战
再好的知识库,如果你的旧笔记进不来,那就是空中楼阁。迁移是绕不过去的体力活,但好在工具链已经比较成熟了,不至于全靠手动复制粘贴。
Obsidian Importer 插件——官方一键搬家
Obsidian 官方出了一个 Importer 插件(在社区插件市场搜 "Importer" 即可),支持一键导入以下来源:
| 来源 | 格式 | 说明 |
|---|---|---|
| Evernote | .enex |
先从 Evernote 导出笔记为 .enex,再用 Importer 导入,附件和图片会一并处理 |
| Notion | .zip(Notion 导出包) |
从 Notion 导出 Markdown & CSV 格式的 zip 包,Importer 能保留大部分结构 |
| Apple Notes | 直接读取本地数据库 | macOS 上可以直接导入,不需要手动导出 |
| Google Keep | .zip(Google Takeout) |
通过 Google Takeout 导出,再导入 |
| Bear | .bear2bk |
Bear 的备份文件格式 |
| HTML 文件 | .html |
通用兜底,任何能导出 HTML 的工具都可以先导 HTML 再转 |
用法很简单:装好插件后,打开命令面板(Ctrl/Cmd + P),搜索 "Import data",选择来源类型,指定文件路径,点导入。插件会自动转成 Markdown 并放到你指定的目录。
不过话说回来,自动转换的 Markdown 质量不会是完美的。Evernote 的富文本格式有些嵌套表格和复杂排版转过来会丢格式,Notion 的数据库视图也没法原样保留。导入之后,建议花时间过一遍重要笔记,手动修一修。
Pandoc——格式转换的瑞士军刀
如果你有大量 Word(.docx)、PDF、HTML、LaTeX、EPUB 等格式的文档要导入,Pandoc 是最靠谱的命令行工具。它能在几十种文档格式之间互相转换,Markdown 是其中之一。
装好之后(brew install pandoc 或去 pandoc.org 下载),批量转换就一行命令的事:
# 单个 Word 文件转 Markdown
pandoc input.docx -t markdown -o output.md
# 批量转换目录下所有 .docx
for f in *.docx; do
pandoc "$f" -t markdown -o "${f%.docx}.md" --extract-media=attachments
done
# HTML 转 Markdown
pandoc page.html -t markdown -o page.md
# PDF 转 Markdown(效果取决于 PDF 结构,扫描件效果差)
pandoc input.pdf -t markdown -o output.md
--extract-media=attachments 这个参数很关键——它会把文档里嵌入的图片提取出来,放到 attachments 目录,Markdown 里自动引用。不然图片就丢了。
PDF 转换有一个坑需要提前知道:Pandoc 处理的是"有文本层"的 PDF,如果你的 PDF 是扫描件(纯图片),它转出来就是空的。这种情况要先用 OCR 工具(比如 ocrmypdf)处理一遍,再转 Markdown。
网页剪藏——日常最高频的导入场景
比起一次性的大迁移,日常更常见的操作是"看到一篇好文章,剪藏到 vault 里"。这里推荐两个工具:
Obsidian Web Clipper(官方浏览器扩展):一键把网页转成 Markdown 保存到 vault。支持 Chrome、Firefox、Safari、Edge。可以自定义保存目录和模板,比如所有剪藏自动加上日期前缀并丢到 0-inbox/ 目录。
MarkDownload(浏览器扩展):如果你觉得 Obsidian Web Clipper 太重,这个更轻量。一键把当前网页转成 .md 文件下载,再手动移到 vault 里。
不管用哪个,剪藏之后记得做一件事:花 30 秒给这篇笔记加个标签或一句话摘要。 不然三个月后你在 vault 里看到一篇标题是 "2026-04-08_clip" 的笔记,根本想不起来当时为什么存的。这 30 秒的投入,将来给 AI 做 RAG 时也会受益——有标签的笔记比没标签的检索准确率高不少。
用 LLM 帮你清洗和整理
如果你要迁移的笔记量很大(几百上千篇),手动清理格式不现实。这时候可以用 LLM 做一轮批量清洗:
import os
from pathlib import Path
from openai import OpenAI
client = OpenAI()
IMPORT_DIR = Path("0-inbox/imported")
CLEAN_PROMPT = """请清理这篇从其他工具导入的笔记:
1. 修复 Markdown 格式问题(坏掉的链接、多余的 HTML 标签等)
2. 在文件开头添加 YAML frontmatter(title, date, tags)
3. 如果能判断主题,加上合适的标签
4. 保留原始内容,不要删减或改写
输出纯 Markdown。"""
for f in IMPORT_DIR.glob("*.md"):
content = f.read_text(encoding="utf-8")
if content.startswith("---"):
continue # 已经有 frontmatter 的跳过
resp = client.chat.completions.create(
model="gpt-4o-mini",
messages=[
{"role": "system", "content": CLEAN_PROMPT},
{"role": "user", "content": content},
],
temperature=0.2,
)
f.write_text(resp.choices[0].message.content, encoding="utf-8")
print(f"cleaned: {f.name}")
这个脚本用便宜的 gpt-4o-mini 就够了——清洗格式不需要太强的推理能力。跑完之后还是得抽检一下,确保它没有把某些特殊格式(比如代码块里的 HTML)误当成"坏格式"给删了。
迁移的节奏:别想一口气搬完
最后一个建议:不要试图在一个周末把所有旧笔记全部迁移完。
实际经验是,先把最近三个月用到的、确定还有价值的笔记迁过来,跑起来再说。剩下的旧笔记可以留在原来的工具里,需要的时候再一篇篇搬。很多笔记你以为很重要,其实搬过来之后再也不会打开。与其花一个月做"完美迁移",不如先花一天把新的工作流跑通。
代价与坑
说了这么多好处,也得说说代价,不然就成了软件推销。
1. 初始整理仍然需要时间
上面虽然给了不少工具,但工具只能解决格式转换的问题,"这篇笔记到底该放在哪个目录"、"标签体系怎么统一"这些决策还是得你自己做。好在这是一次性成本,结构定下来之后,后面的笔记就按规矩走了。
2. AI 插件的质量参差不齐
Obsidian 的插件生态虽然丰富(2700+),但 AI 相关的插件更新频率和质量差距很大。某些插件的 embedding 模型一更新就不兼容了,某些插件的 prompt 工程做得粗糙,给出的回答驴唇不对马嘴。建议只装成熟的、有活跃维护的插件(看 GitHub star 和最近 commit 时间)。
3. 本地 LLM 对硬件有要求
如果你想全程不碰云端 API,用 Ollama 跑本地模型,那你需要: - 16GB 以上内存(跑 7B 参数的模型至少要这个数) - Apple Silicon M 系列或 NVIDIA RTX 3060 以上(没有 GPU 也能跑,就是慢到让你怀疑人生) - 30GB 左右的磁盘空间(模型本身就不小)
如果只是做 embedding 和轻量问答,要求会低一些。但如果想跑 70B 级别的模型做复杂推理,那就是另一个量级的投入了。
4. "编译式"知识库需要持续投入
Karpathy 的 LLM Wiki 思路很好,但它不是装好就能自动跑的。你得定期喂它新材料,定期检查 wiki 页面的质量,定期更新编译脚本来适配新的模型和 prompt。这更像是养一个花园,不是装一个电器。
5. 隐私和安全不能马虎
用云端 API(OpenAI、Claude)时,你的笔记内容会被传到服务器上。如果笔记里有敏感信息(公司机密、个人隐私),要么用本地模型,要么在发送前做脱敏处理。MCP 模式下,AI Agent 有读写 vault 的权限,要确保它的操作范围是你预期内的。
总结
- Obsidian 的核心优势:纯 Markdown + 本地文件 + 双向链接,天然适合做 LLM 的知识输入。
- 三种集成模式:插件式(Smart Connections / Copilot)最省心,MCP 式(Claude Code / Cursor)最强大,编译式(LLM Wiki)最有深度。按需选择,可以组合。
- 地基比工具重要:目录结构、命名规范、元数据习惯,这些"无聊的事"决定了 AI 能不能在你的知识库里高效工作。
- 不是银弹:初始整理有成本,插件质量参差,本地模型吃硬件,编译式需要持续投入。但这些代价换来的是一个真正属于你的、AI 能理解的知识库。
思维导图(源码见下节 PlantUML,以下为渲染图):
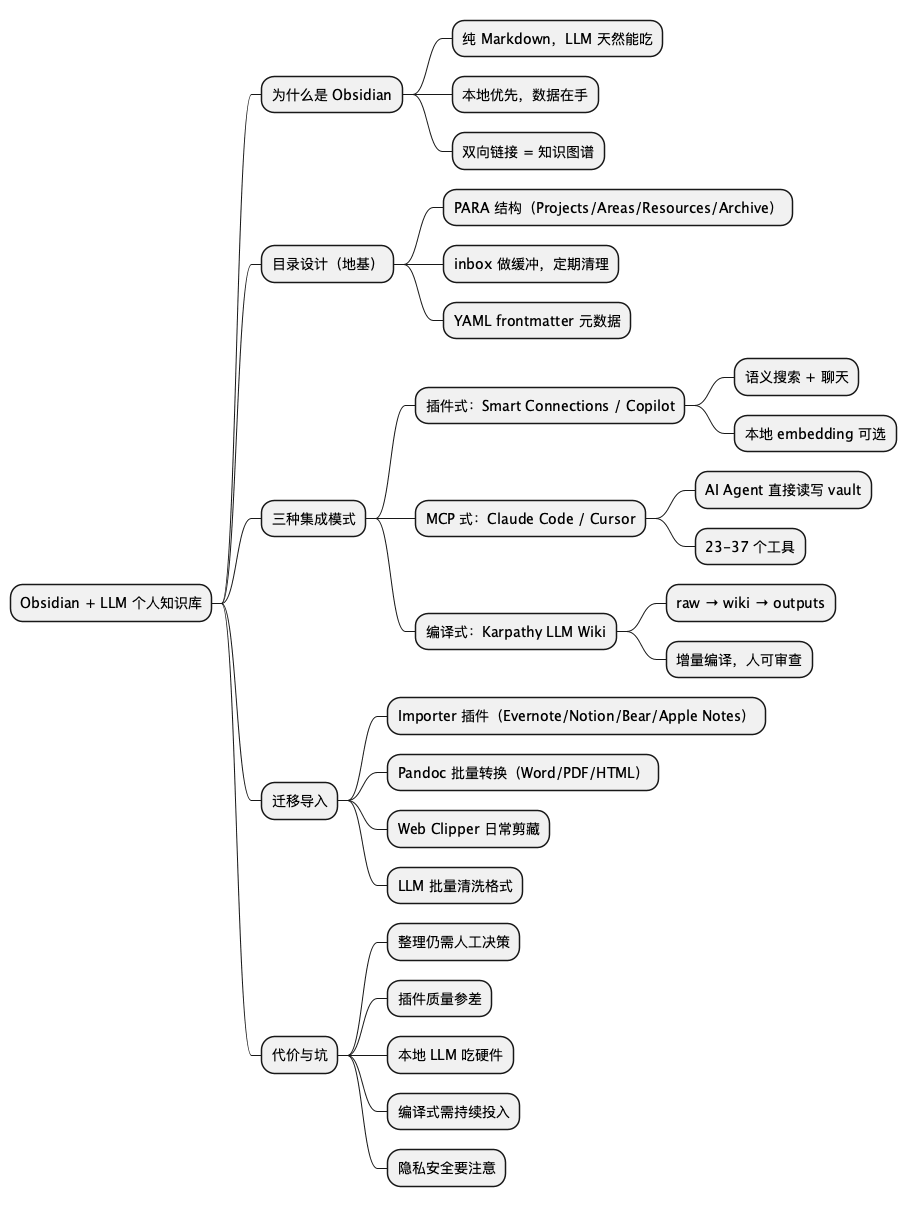
@startmindmap
* Obsidian + LLM 个人知识库
** 为什么是 Obsidian
*** 纯 Markdown,LLM 天然能吃
*** 本地优先,数据在手
*** 双向链接 = 知识图谱
** 目录设计(地基)
*** PARA 结构(Projects/Areas/Resources/Archive)
*** inbox 做缓冲,定期清理
*** YAML frontmatter 元数据
** 三种集成模式
*** 插件式:Smart Connections / Copilot
**** 语义搜索 + 聊天
**** 本地 embedding 可选
*** MCP 式:Claude Code / Cursor
**** AI Agent 直接读写 vault
**** 23-37 个工具
*** 编译式:Karpathy LLM Wiki
**** raw → wiki → outputs
**** 增量编译,人可审查
** 迁移导入
*** Importer 插件(Evernote/Notion/Bear/Apple Notes)
*** Pandoc 批量转换(Word/PDF/HTML)
*** Web Clipper 日常剪藏
*** LLM 批量清洗格式
** 代价与坑
*** 整理仍需人工决策
*** 插件质量参差
*** 本地 LLM 吃硬件
*** 编译式需持续投入
*** 隐私安全要注意
@endmindmap
可执行 CheckList(明天就能做)
- 先把 vault 目录理清:按 PARA 或你自己顺手的结构整理一遍,确保每篇笔记有"家"、有 frontmatter。
- 装一个 AI 插件试水:推荐先装 Smart Connections(语义搜索)或 Copilot(聊天),感受一下"AI 能读懂我的笔记"是什么体验。
- 如果你用 Claude Code 或 Cursor:花 10 分钟配一个 Obsidian MCP Server,让你在写代码时也能随时查笔记。
- 建一个
raw/目录开始积累素材:网页剪藏、PDF、会议纪要都往里丢,每周跑一次编译脚本(哪怕是手动调 ChatGPT 帮你整理)。 - 给自己定一个"每周整理 30 分钟"的习惯:知识库和健身一样,三天打鱼两天晒网比不做还糟糕。
- 隐私红线画清楚:决定哪些笔记可以发到云端 API,哪些只能走本地模型,别等出了事再后悔。
扩展阅读
- Obsidian 官网:https://obsidian.md/
- Smart Connections 插件:https://smartconnections.app/
- Obsidian MCP Pro:https://www.npmjs.com/package/obsidian-mcp-pro
- Karpathy 的 LLM Wiki 思路:https://x.com/karpathy/status/1886192505547280842
- Ollama(本地跑 LLM):https://ollama.com/
- PARA 方法(Tiago Forte):https://fortelabs.com/blog/para/
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。