AI 写的代码:华丽袍子下面,也可能都是虱子
Posted on 三 01 7月 2026 in Journal
| Abstract | AI 写的代码:华丽袍子下面,也可能都是虱子 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v0.2 |
| Updated | 2026-07-01 |
| License | CC-BY-NC-ND 4.0 |
AI 写的代码:华丽袍子下面,也可能都是虱子
短大纲
- AI 写代码很快,快到让人误以为“工程能力”也被一起生成了
- 这次不是低配实验:Claude Opus 4.8、GPT 5.5、Golang 项目、各种 harness 都用上了
- 看起来能跑,不等于设计干净、边界清楚、长期可维护
- 顶级大模型也会写出“局部正确、整体别扭”的代码
- harness 能拦住编译、竞态、测试、安全,却不一定能拦住命名、品味和语义漂移
- 问题不在于用不用 AI,而在于有没有把 AI 当成一个刚毕业的博士生来带
- 大模型懂得多,却不知道什么最适合你的产品、环境、业务和那座“屎山”
- 上岗要备齐五样:指导手册、设计与代码规范、架构原则、编码规范、验收清单,一个都不能少
- AI 代码进主干之前,必须过需求、设计、测试、可读性、可维护性几道关
- 最后给一套可抄的 AI 代码验收清单
一、代码看起来很美,心里却有点发毛
最近做一个 Golang 新项目,前期设计我自己先搞定,模块怎么拆,接口怎么定,主要数据流怎么走,边界在哪里,心里大致有数。到了编码阶段,我想做个实验:既然 AI 编程这么火,那就干脆让它多写一点。
这次用的也不是三流工具,而是 Claude Opus 4.8 和 GPT 5.5,堪称当今 AI 编程的顶流了。Golang 项目的各种 harness 手段,我也尽量都用上了,像 gofmt、go vet、go build、go test -race、golangci-lint、AGENTS.md、边界约束、测试闸门这些,之前在《Go 服务用 AI 写代码:工具链白送了半套 harness,你只是没拧紧》里专门写过。
于是我把设计文档、接口约定、一些关键约束喂进去,让它开始写。不得不说,第一眼看上去,效果很好。目录有了,包有了,函数名也像那么回事,注释还挺周到。跑一下基本路径,仿佛也没问题。那一刻,我这个老程序员甚至有点恍惚:难道以后真不用挽袖子写代码了?
但仔细看下去,心情就变了。
借用那句老话:华丽的袍子下面,都是虱子。
不是说它完全不能用。恰恰相反,很多地方能用,甚至局部写得还不错。问题在于,它的坏不是那种一眼就能看出来的坏,而是“看起来很合理,连起来很别扭”。像一间样板房,灯光一打,沙发一摆,拍照很好看;真住进去才发现,插座在柜子后面,卫生间门打不开,厨房动线绕得像迷宫。
更扎心的是,这不是“模型太弱”“上下文没给够”“工程约束没上”的锅。顶流模型、Go 工具链、harness 闸门都在场,可结果依然不尽如人意。
所以问题来了:怎么办?
二、AI 代码最危险的地方,是“差不多能跑”
传统新人写坏代码,很多时候坏得很朴素。变量名乱,异常没处理,边界没想,测试没有,老手扫一眼就知道哪里不对。AI 写坏代码不一样,它坏得更“体面”。
它会给你合理的文件名,整齐的缩进,看似周全的分层,甚至还会在注释里写出一副很懂架构的样子。你如果只看表面,很容易被它的“职业形象”骗过去。
我这次看到的问题,大概有几类。
第一类:命名不知名达意。
这件事最让我惊讶。命名要“知名达意”,听起来是编程入门第一课:变量名、函数名、包名要让人看出它表示什么、负责什么、边界在哪里。可 AI 偏偏会在这里翻车。它会写出一些看似标准、实际空泛的名字,比如 handler、manager、processor、data、result,每个词都没错,合在一起却像会议纪要里的“相关事项”。
Go 代码尤其怕这个。Go 本来就鼓励短命名,但短不等于糊。ctx、err、req 这些短,是因为上下文清楚;如果一个跨越三层业务语义的对象也叫 data,那就不是简洁,是把信息藏起来。命名一旦糊,后面的抽象、边界、测试也会跟着糊。
第二类:局部函数能看,整体结构乱。
单个函数拿出来,好像都说得过去。但模块之间职责交叉,有的逻辑放在 A 也行,放在 B 也行,最后就真的到处都放了一点。代码像城市里临时搭出来的小路,今天为了绕一个坑修一条,明天为了躲一棵树再修一条,半年后地图上全是羊肠小道。
第三类: happy path 很顺,异常路径很虚。
正常输入、正常返回、正常流程,AI 很擅长。可是工程里麻烦的从来不是“太阳出来了,大家上班了”这种场景,而是网络抖了、数据脏了、依赖超时了、权限不够了、重复请求来了、用户手一抖点了两次。AI 常常会写一点异常处理,但更像在门口贴了张“注意安全”的纸,真出事时不一定挡得住。
第四类:重复和变体很多。
它不怕复制。你让它写三个类似功能,它可能生成三套长得像兄弟但不完全一样的代码。短期看,功能都有;长期看,维护者会开始怀疑人生:这个字段为什么这里叫 status,那里叫 state?这个错误为什么这里抛异常,那里返回空值?这个校验为什么三处逻辑都不一样?
第五类:抽象要么太少,要么太多。
有时它像刚学会设计模式的新同学,恨不得给一只鸡蛋配一个工厂、一个策略、一个上下文;有时又像赶作业的学生,把所有逻辑塞进一个大函数。它知道很多“形”,但不总能把握“度”。
一句话,AI 很会写“像代码的代码”,但工程要的是“能长期活下去的代码”。这两者不是一回事。
三、不要把 AI 当神,也不要把它当废物
遇到这种情况,有两种极端反应。
一种是继续迷信:跑了就行,AI 写得比人快,别矫情。另一种是彻底否定:你看,AI 不靠谱,以后还是手写吧。
我觉得都不对。
AI 不是神。它不知道你的组织历史,不知道上一代系统埋过什么雷,不知道某个字段为什么不能改名,不知道一个线上故障会让谁半夜接电话。它也没有真正的“责任感”。代码合进主干后,是人来背锅,不是模型来值班。
但 AI 也不是废物。它很适合写样板代码、搭原型、补测试草稿、生成迁移脚本、解释陌生代码、枚举边界场景。很多活以前是“体力活 + 一点脑力”,现在可以交给它先跑一遍。
关键是角色要摆正。
我现在更愿意把 AI 当成一个刚毕业的博士生:论文读了一大堆,算法信手拈来,各种范式如数家珍,简历漂亮得能闪瞎人。可是你把他放进你的团队,让他动手干活,你会发现一个残酷的落差——他知道的很多,却不知道什么是最合适的。
他不知道你这个产品的用户到底是谁,不知道哪几个接口是祖传的、动不得,不知道那段看起来很蠢的 if 是三年前一次线上事故换来的血泪补丁。他更不知道你们代码库里那座积了五年的“屎山”——哪块能碰,哪块碰了就塌,哪块看着丑但其实是承重墙。
书本上的“最佳实践”,到了具体的产品、环境、业务和历史包袱面前,常常水土不服。博士懂全局最优,工程要的是约束下的可行解。这个落差,不是再多读几篇论文能补上的,只能靠人给他讲、带他走、盯他改。
所以问题不是“这个博士生行不行”,而是“你有没有把他当新人来带”。你会怎么带一个刚入职的博士生?
- 你不会只丢一句“帮我把系统写了”,然后三天后直接上线。
- 你会先给他一份上岗手册,把规范、边界、例子、验收标准都摆清楚。
- 你会先拆任务,让他复述一遍,确认他没理解偏。
- 你会看设计,看 diff,看测试,看日志,看回滚方案。
- 你会让他改几轮,而不是第一次提交就说“辛苦了,合并”。
对 AI 也一样。区别只在于,博士生带一年就出师了,AI 每开一个新会话,几乎又变回那个“什么都懂、什么都不熟”的第一天。所以那份上岗大礼包,你得反复喂,喂进每一次对话里。
四、AI 代码要分三层验收
以前我们 review 人写的代码,常常从 diff 开始。AI 时代,只看 diff 不够,因为它生成得太快,量太大,而且表面太工整。咱们得把验收往前挪一点,分三层看。
| 层次 | 要问的问题 | 常见风险 |
|---|---|---|
| 需求层 | 它解决的是不是正确的问题?边界有没有被写清楚? | 功能看似完成,其实偏题 |
| 设计层 | 模块职责、数据流、依赖方向是否清楚? | 局部能跑,整体难维护 |
| 代码层 | 可读性、测试、异常、安全、性能是否过关? | 袍子漂亮,里面长虱子 |
第一层,需求验收。
AI 最怕需求含糊。你说“实现一个用户管理模块”,它就会按互联网平均印象给你生成一套。可你的系统里,“用户”可能不是登录账号,而是租户下的成员;删除用户可能不是物理删除,而是解绑关系;状态变更可能要触发审计日志和通知。这里差一个词,后面就差一条街。
所以在让 AI 写代码前,先让它复述需求。不是礼貌,是校准。让它说清楚:输入是什么,输出是什么,不做什么,异常怎么处理,哪些地方需要人工确认。它复述错了,就不要让它写。方向错了,代码越多,债越厚。
第二层,设计验收。
设计不是画几条线给别人看,而是把复杂度安放到合适的位置。AI 生成代码前,最好先让它给出模块结构和调用关系。你要盯住几个问题:依赖方向对不对?领域逻辑有没有被 UI 或 API 层吃掉?数据访问有没有泄漏到业务层到处都是?错误处理有没有统一策略?
这一步不要嫌慢。设计阶段慢十分钟,可能省掉后面两天骂街。
第三层,代码验收。
到了代码层,不要只问“能不能跑”。要问:别人能不能读懂?我三个月后能不能改?测试能不能保护关键行为?异常信息够不够排障?日志有没有泄露敏感信息?依赖升级会不会牵一发动全身?
代码是写给机器执行的,也是写给人维护的。机器只在乎语法和结果,人还要在乎意图、边界和代价。
五、为什么 harness 都用上了,还是不尽如人意
按理说,Golang 项目加上 harness,已经比很多项目好伺候了。gofmt 管格式,go vet 抓低级问题,go build ./... 治幻觉 API,go test -race 抓竞态,golangci-lint 管错误、资源、依赖、安全,AGENTS.md 给上下文,测试和 CI 负责红绿灯。
这些东西有用吗?当然有用。没有它们,AI 写出来的代码可能更像野外生长的灌木丛,风一吹就东倒西歪。
但它们也有边界。harness 更擅长拦“可判定的问题”,不擅长拦“品味问题”和“语义问题”。编译不过,它能拦;竞态被测试跑出来,它能拦;错误没处理,lint 能拦;日志泄露敏感信息,安全规则能拦。可是函数名是不是准确?一个概念是不是被拆成了三个近义词?一个包的职责是不是慢慢漂移?这些东西,工具不一定看得见。
原因大概有三点。
第一个原因:AI 擅长局部相似,不等于理解整体语义。
它见过无数 Go 项目,知道一个 repository 大概怎么写,一个 service 大概怎么写,一个 handler 大概怎么写。问题是,你这个项目里的 Session、Task、Job、Run、Execution 到底有什么区别,它未必真的吃透。它会用训练数据里的平均命名来填你的业务空白。平均命名看起来安全,实际上最容易把领域语义磨平。
第二个原因:harness 管的是“红线”,不是“审美”。
红线很重要。没有红线,工程就会变成菜市场。但红线只能告诉你“不许这样”,很难告诉你“这样更好”。比如 ProcessData() 不是非法函数名,lint 不会因为它俗气就打你手心;Manager 也不是编译错误,只是它常常说明作者没想清楚职责。很多坏代码不是违法建筑,而是户型奇怪、采光很差、住久了憋屈。
第三个原因:AI 没有长期维护的痛感。
它不需要三个月后回来改这段代码,不需要半夜查日志,不需要跟同事解释为什么这里有两个类似的概念。人写代码会被历史教育,模型不会。它可以生成一段“此刻看起来合理”的代码,但工程质量常常来自“未来维护者的痛感”。这个痛感,暂时还得人来补。
所以,问题不在于 harness 没用,而在于我们容易高估 harness 的覆盖范围。harness 是护栏,不是司机;是体检表,不是生活习惯;是红绿灯,不是城市规划。
它能让 AI 少犯低级错误,但不能自动给 AI 长出工程品味。
六、给 AI 一份“上岗大礼包”,一个都不能少
回到那个博士生的比喻。你带一个新人,绝不会光说一句“好好干”就撒手。你会给他一整套东西:上岗手册、规范文档、架构原则、编码约定、还有一份验收清单,告诉他“做完了拿这个对一遍”。
对 AI,也得备齐这一套。它知识面广,但对你的产品、环境、业务和那座“屎山”没有清醒认识。你不给它这些,它就只能拿训练数据里的“行业平均值”来填空——而平均值,恰恰是最不适合你这个具体项目的东西。
我把这套东西叫“上岗大礼包”,一共五样,缺一样,AI 就会在那一样上自由发挥。
第一样:指导手册(它是谁、要干什么、不许干什么)。
一段话讲清楚这个项目是做什么的、用户是谁、当前最要紧的目标是什么、哪些是明确的非目标。再加一段“坑点地图”:哪些模块是祖传代码不许乱动,哪个字段改名会引发线上事故,哪个依赖已经准备下线别再往上加东西。这就是让博士生“认清现实”的那一课,AI 尤其需要。
第二样:设计与代码规范(长什么样才算对)。
给它看范例,比跟它讲道理有用得多。挑一两个你团队里“写得最正”的模块,作为标杆贴给它:目录怎么组织,分层怎么分,错误怎么包装,日志怎么打,命名用什么词汇表。AI 极擅长模仿,你给它一个好样板,它照着抄的成功率,远高于你给它一堆抽象原则。
第三样:架构原则(复杂度往哪儿放)。
把几条不可谈判的架构约束写死:依赖方向只能从外往里,领域逻辑不许被 API 层或 UI 层吃掉,数据访问只能走 repository 层,跨模块通信只能通过定义好的接口。这些原则决定了系统三年后是能演进还是会板结。AI 不会主动替你守,因为它没有“三年后”这个概念,只能靠你写进约束里。
第四样:编码规范(细到能照着抄)。
越具体越好,含糊的规范等于没有。比如:函数超过 50 行就要考虑拆;导出的类型和函数必须写文档注释;错误一律用 fmt.Errorf("...: %w", err) 包装并带上下文;同一个概念全项目只准用一个名字(status 还是 state,先定死);测试文件必须覆盖主路径 + 至少两条异常路径。这些规则 golangci-lint 能兜住一部分,兜不住的,就写进手册当红线。
第五样:检查与验收清单(做完了拿什么对)。
这是最容易被省略、也最不该省略的一样。你得给 AI 一份“交付前自检表”,让它在提交前先自己过一遍;你自己再拿一份“验收清单”把关。清单长什么样,本文第八节那张表就是现成的模板,直接抄。
一句话:大模型懂得多,但它不知道什么最合适;那份“最合适”,得你以手册、规范、原则、清单的形式,一条条喂给它。 你喂得越具体,它自由发挥的空间就越小,跑偏的概率也越低。
这五样东西,最好沉淀成项目里的固定文件,比如一份 AGENTS.md 或 CONVENTIONS.md,每开一个新会话就先喂进去。不然你今天讲一遍,明天换个对话,它又变回那个“什么都懂、什么都不熟”的第一天。
七、我的做法:让 AI 先写,但不让它最后说了算
经过这次折腾,我觉得比较靠谱的工作方式是:AI 负责加速,人负责定标。
整个流程串起来是这样一个圈:先备齐大礼包,让它出计划、对齐需求,再小步生成、补测试、做 review,过了验收清单才准合并;哪一步发现虱子,就退回去捉干净再往下走。
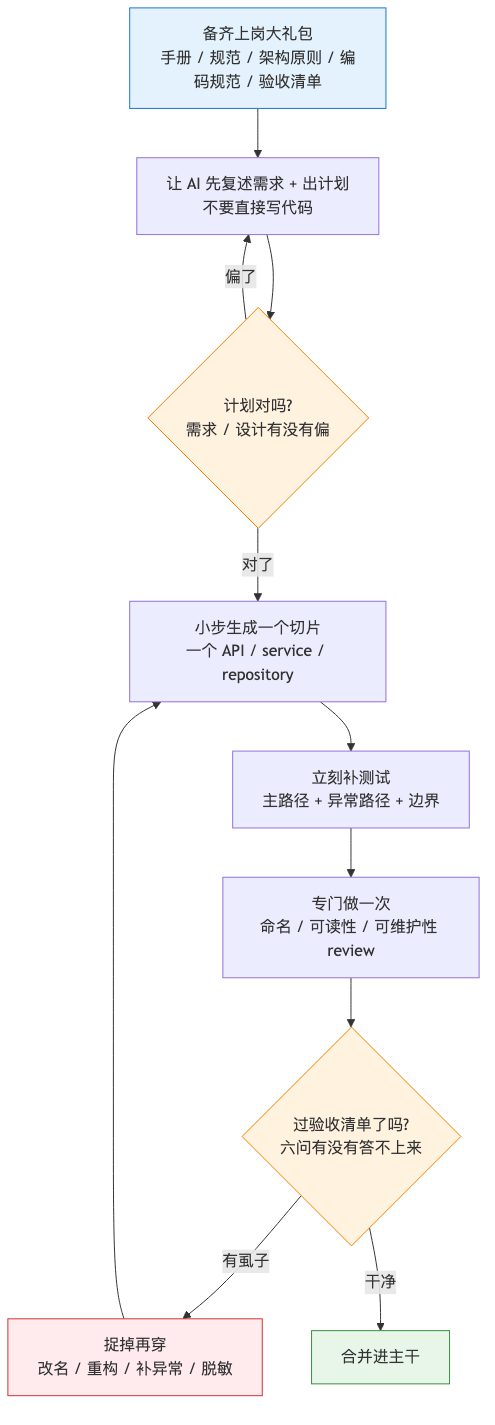
flowchart TD
A["备齐上岗大礼包<br/>手册 / 规范 / 架构原则 / 编码规范 / 验收清单"] --> B["让 AI 先复述需求 + 出计划<br/>不要直接写代码"]
B --> C{"计划对吗?<br/>需求 / 设计有没有偏"}
C -- "偏了" --> B
C -- "对了" --> D["小步生成一个切片<br/>一个 API / service / repository"]
D --> E["立刻补测试<br/>主路径 + 异常路径 + 边界"]
E --> F["专门做一次<br/>命名 / 可读性 / 可维护性 review"]
F --> G{"过验收清单了吗?<br/>六问有没有答不上来"}
G -- "有虱子" --> H["捉掉再穿<br/>改名 / 重构 / 补异常 / 脱敏"]
H --> D
G -- "干净" --> I["合并进主干"]
具体一点,我会把流程拆成几步。
第一步:先把“上岗大礼包”喂进去。
不要一上来就让 AI 写代码。先把上一节那五样东西——手册、规范、架构原则、编码规范、验收清单——整理成固定文件喂给它。至少要讲清楚:
- 目录结构怎么放
- 模块边界怎么划
- 错误处理用什么风格
- 日志里不能出现什么数据
- 测试至少覆盖哪些路径
- 哪些设计已经定了,不允许自己发挥
- 哪些地方不确定,需要先问人
这套东西就像护栏。没有护栏,AI 很容易在知识海洋里自由泳,游得很开心,最后不知道游到哪个国家去了。
第二步:让 AI 先出计划,不要直接出代码。
我现在更喜欢这样的提示:
先不要写代码。
请根据下面的设计,列出你准备修改/新增的文件、每个文件的职责、主要函数、关键异常路径和测试点。
如果有不确定的需求,请列出来,不要自行假设。
它的计划如果乱,代码大概率也乱。计划阶段改它,比代码阶段改它便宜得多。
第三步:小步生成,小步 review。
不要一次让它生成半个系统。一次只让它做一个明确切片:一个 API、一个 service、一个 repository、一个测试文件。每次生成后马上 review。坏味道越早发现,越容易改。
AI 生成代码的速度很快,但人的理解速度没有跟着翻倍。如果一次丢给自己两千行 diff,那不是提高效率,是把 review 变成刑罚。
第四步:先跑测试,再做重构。
AI 写完后,不要急着夸它。先补测试,至少覆盖主路径、异常路径、边界输入、重复调用、依赖失败。测试像钉子,先把行为钉住,再去整理结构。
然后做一次专门的重构 review,只看可读性和维护性:命名是不是一致,职责是不是单一,重复是不是该抽,抽象是不是过度,函数是不是太长,错误是不是统一。
第五步:让另一个 AI 或另一个人挑刺。
同一个模型刚写完代码,再让它自己检查,常常会护短,像自己孩子写作文,怎么看都眉清目秀。可以换一个模型,或者换一种 prompt,让它站在 reviewer、tester、operator 的角度找问题。
当然,最后还是人拍板。AI 可以帮忙挑刺,但不能替你承担判断。
八、可抄的 AI 代码验收清单
下面这张表,是我以后准备贴在 AI 生成代码旁边的。每次合并前,至少扫一遍。
| 检查项 | 自问一句 | 不通过时怎么办 |
|---|---|---|
| 需求对齐 | 这段代码解决的是原问题吗?有没有偷偷扩大范围? | 回到需求,让 AI 复述并缩小任务 |
| 边界清楚 | 哪些场景明确不支持?异常输入怎么处理? | 补边界说明和测试 |
| 职责单一 | 每个模块是不是只做一类事? | 拆分职责,调整依赖方向 |
| 命名达意 | 名字能不能说明“它是什么、负责什么、边界在哪里”? | 改名,统一术语,必要时加 glossary |
| 命名一致 | 同一概念有没有多个名字? | 合并近义词,建立项目词汇表 |
| 重复可控 | 相似逻辑是不是复制了多份? | 抽出公共函数,但不要过度抽象 |
| 异常可排 | 出错时能不能定位问题? | 统一错误类型,补安全日志 |
| 测试有效 | 测试是在保护行为,还是只为覆盖率凑数? | 补关键路径和失败路径 |
| 安全合规 | 是否把 token、用户数据、内部细节写进日志? | 立刻删,改成脱敏和最小暴露 |
| 可维护性 | 三个月后我还愿不愿意改这段代码? | 重构,不要自我安慰 |
还有一个更短的版本,适合贴在屏幕边上:
AI 代码合并前六问:
1. 需求有没有被它理解错?
2. 设计有没有变形?
3. 命名有没有知名达意?
4. 异常路径有没有真的处理?
5. 测试有没有保护关键行为?
6. 三个月后我愿不愿意维护?
如果这六问有两问答不上来,就别急着合。代码不会因为你晚合一天就哭,技术债会因为你早合一天而笑。
九、AI 时代,老程序员更不能只当“代码搬运工”
AI 写代码越强,人的价值反而越要往上提一点。
以前一个程序员的价值,很大一部分体现在“我能把代码写出来”。现在这件事正在变便宜。不是不重要,而是不再稀缺。真正稀缺的是:你知不知道该写什么,不该写什么;你能不能看出漂亮代码里的烂味道;你能不能把一堆生成物整理成可演进的系统。
这有点像从手工抄书进入印刷术时代。抄得快不再是核心竞争力,选什么书、怎么校对、怎么装订、怎么流通,变得更重要。
程序员也一样。AI 可以帮我们打字、铺路、搬砖,但系统的方向、边界、品味、责任,还得人来守。
所以我的结论并不悲观。
AI 写得乱,说明我们不能偷懒;AI 写得快,说明我们更需要方法。以后工程师的基本功里,可能要多一项:管理 AI 生成的复杂度。
这项能力包括:会拆任务,会写约束,会设计验收,会读坏代码,会做重构,会补测试,会统一命名,会拒绝“看起来差不多”。
无他,还是那句老话:工具越锋利,手越要稳。
最后:别裸奔,也别弃疗
这次新项目给我的提醒很直接:AI 可以让项目启动得很快,也可以让技术债生成得很快。它像一台马力很足的车,油门一踩,推背感很强;但如果方向盘、刹车和后视镜都没人管,开得越快,越容易进沟。
我的建议很简单。
不要因为 AI 写得漂亮就放松警惕,也不要因为它写得丑就把它赶出门。把它纳入工程体系:先设计,后生成;先计划,后编码;先测试,后重构;先验收,后合并。
最后留一张行动清单,给明天就想继续用 AI 写代码的朋友,也给我自己:
- 新任务开始前,先备齐上岗大礼包:手册、规范、架构原则、编码规范、验收清单
- 每开一个新会话,先把这套约束喂进去,别指望它记得上次
- 让 AI 先输出计划,不要直接写代码
- 每次只生成一个小切片,避免巨型 diff
- 主路径跑通后,立刻补异常路径测试
- 专门做一次命名、可读性和可维护性 review
- 对安全、日志、权限、数据边界保持人工判断
- 合并前问自己:这段代码出了问题,半夜被叫醒的人是谁
如果答案是你自己,那就别被那件华丽袍子迷住。
掀开看看。
有虱子,就捉掉再穿。
附:一份可直接抄的 AGENTS.md 模板
光说“备齐五样”,落到手上还是有点虚。这里给一份现成骨架,对应前面说的五样大礼包。你把它放进项目根目录,改成自己的内容,每开一个新会话就先喂给 AI。别追求一次写全,先把最要命的几条填进去,后面边用边补。
# AGENTS.md
## 1. 指导手册:这个项目是什么
- 一句话说明:本项目是做什么的、给谁用的。
- 当前目标:这个迭代最要紧的是 X,不是 Y。
- 非目标:明确不做 A、B、C,别自作主张扩范围。
- 坑点地图(改动前必看):
- `xxx` 模块是祖传代码,不许重构,只许小补。
- `user.status` 字段不许改名,下游三个服务在读。
- `legacy/` 目录准备下线,不要往里加新东西。
## 2. 设计与代码规范:长什么样才算对
- 标杆模块:照着 `internal/order/` 的风格写,别自创一套。
- 目录组织:`cmd/` 入口,`internal/` 业务,`pkg/` 可复用。
- 分层:handler → service → repository,只能往下依赖。
- 错误:一律 `fmt.Errorf("do sth: %w", err)`,带上下文。
- 日志:结构化日志,禁止打印 token、手机号、身份证等敏感数据。
## 3. 架构原则:不可谈判的几条
- 依赖方向只能从外往里,领域逻辑不许被 API/UI 层吃掉。
- 数据访问只能走 repository,业务层不许直接写 SQL。
- 跨模块通信只能通过定义好的接口,不许直接引内部结构体。
- 新增外部依赖前先问人,不许自行 `go get`。
## 4. 编码规范:细到能照着抄
- 函数超过 50 行就考虑拆。
- 导出的类型和函数必须写文档注释。
- 同一概念全项目只用一个名字(先定死:用 `status` 不用 `state`)。
- 测试必须覆盖:主路径 + 至少两条异常路径 + 边界输入。
- 提交前必须跑通:`gofmt`、`go vet`、`go build ./...`、
`go test -race ./...`、`golangci-lint run`。
## 5. 检查与验收清单:交付前自己先过一遍
在你说“写完了”之前,逐条自检并回答:
1. 需求有没有理解错?(先复述,再动手)
2. 设计有没有变形?(依赖方向、分层边界还在吗)
3. 命名有没有知名达意?(有没有 data / manager / processor)
4. 异常路径有没有真的处理?(不是贴张“注意安全”)
5. 测试有没有保护关键行为?(还是只为覆盖率凑数)
6. 有没有把敏感数据写进日志?
7. 有不确定的地方吗?列出来,别自行假设。
## 工作方式
- 先出计划,不要直接写代码。
- 一次只做一个小切片,别给我两千行 diff。
- 拿不准就停下来问,宁可多问一句,别猜。
一句话:这份文件就是你带那个博士生的“上岗手册 + 验收表”合订本。 你把它维护得越具体,AI 跑偏的空间就越小,你半夜被叫醒的概率也越低。