AI 写得太快,肉眼看不过来:当 Code Review 成为新瓶颈
Posted on 三 24 6月 2026 in Journal
| Abstract | AI 写得太快,肉眼看不过来:当 Code Review 成为新瓶颈 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Status | v1.0 |
| Updated | 2026-06-24 |
| License | CC-BY-NC-ND 4.0 |
短大纲(给忙人)
- 痛点:Claude Code/Codex 一天能生成几千行代码,reviewer 一天能看几百行,这账算不平
- 核心观点:review 的瓶颈不在"看得快不快",而在"敢不敢点 Approve"。要解决的是信心,不是阅读速度
- 三个错误姿势:逐行看(不可持续)、闭眼批(不负责)、全交给 AI(同源污染)
- 解法:三层防线 + 一份 reviewer note + 一个 ready-to-review 自检表
- 配套工具:分维度 AI review、按逻辑边界拆大 MR、用测试用例当 Gate Verdict、未解决评论自动转 issue、PKB 沉淀架构上下文
- 关键转变:从"审代码"转向"审意图、审边界、审验证"
一个真实的场景
上周和一个朋友聊天,他是某团队的 tech lead。他说他现在最怕的不是写代码,是周一早上打开 GitLab。
"上周五一天,团队提了 17 个 MR。其中 12 个是 Claude Code 写的,剩下 5 个是 Codex 写的。每个 MR 平均 600 行。我周末本来想休息,结果一打开邮箱我就崩溃了。"
我问他:"那你都看了?"
他笑得很苦:"看个屁。我抽了 4 个我觉得风险高的认真看了,剩下的我扫了一眼 diff,跑了一下 CI,绿了我就点 Approve 了。"
"你心虚吗?"
"虚得很。但是不点的话,整个团队就堵在我这。"
这就是 2026 年很多团队的真实状态。写代码这件事的速度已经被 AI 推到了 5 倍以上,但 reviewer 的阅读速度还是肉眼那个阅读速度。 这个速度差不会自动消失,会变成 bug、变成技术债、变成线上事故,最后变成你的奖金。
Anthropic 自己公布过一个数据:在他们引入 AI 辅助 review 之前,团队里只有 16% 的 PR 收到过真正有意义的评审反馈。其他 84% 是怎么过的?扫一眼,绿了,merge。
人家是 Anthropic。人家是写出 Claude 的公司。人家的工程师都做不到逐行审查。你别太苛求自己。
先说一句扎心的话:你以前的 review 也没你想的那么仔细
容我泼一盆冷水。AI 不是把 review 这件事从"严谨"变成"潦草",而是把一件本来就潦草的事,潦草地放大了。
你回忆一下你过去三年点过的 Approve:
- 有多少是认真逐行看过的?
- 有多少是看了一眼 diff 就过了?
- 有多少是因为提 MR 的人是同事/老朋友/老板,所以你不好意思打回去?
- 有多少是周五下午五点半,你只想下班?
承认这件事的好处是:我们要解决的不是"AI 让 review 退化了",而是"AI 把 review 这个旧问题放大到无法忽视了"。
视角一转,问题就不一样了。我们不是要把每一行 AI 代码都看一遍——那个目标本来就达不到,AI 出现之前也达不到。我们要做的是:把有限的"高质量注意力"投到最关键的地方。
三种常见的错误姿势
在给方案之前,先把三种我看过的错误姿势摆出来。如果你正在用,请立刻停下来。
姿势一:硬扛——逐行人肉看
特征:把自己当成人形 linter,看到 600 行的 MR 就咬牙看完。
代价:
- 一个 MR 看 90 分钟,一天最多看 4 个
- 看到第三个就开始走神,第四个等于没看
- 自己的开发任务全部停滞,team 抱怨你拖慢节奏
- 久而久之,你会变成一个又累又焦虑、还经常漏掉 bug 的瓶颈
这是最让人尊敬的姿势,也是最不可持续的姿势。
姿势二:摆烂——闭眼点 Approve
特征:CI 绿了就过,看一眼 diff 长度就过,对方说"这个我测过了"就过。
代价:
- 第一次 bug 上线,你心虚
- 第二次 bug 上线,老板找你谈话
- 第三次 bug 上线,你开始怀疑自己适不适合做 tech lead
这是看起来最舒服的姿势,但其实最难受——因为你自己知道自己心虚。
姿势三:同源污染——全交给 AI 审
特征:"让 Claude 写代码,让 Codex 审代码,让另一个 Agent 写测试,人类只负责点 Merge。"
听起来很美。但这里有个隐患叫同源污染:当生成代码和审查代码的模型来自同一类训练分布,它们对"什么是正确的代码"有非常相似的盲区。
打个比方,你雇了一个司机开车,又雇了他的双胞胎兄弟在副驾驶监督他。两个人都觉得"红灯可以闯一下"——你猜结果会怎样?
AI review 是好东西,但它不能是唯一的那道关。后面会展开讲。
我的解法:三层防线
思路不复杂,但每一层都不能省,省了就会塌。
@startuml
title Code Review 三层防线
skinparam defaultFontName "PingFang SC"
skinparam shadowing false
skinparam roundCorner 12
skinparam ArrowColor #555555
skinparam ArrowFontColor #555555
skinparam rectangle {
BackgroundColor<<L1>> #E3F2FD
BorderColor<<L1>> #1E88E5
BackgroundColor<<L2>> #FFF8E1
BorderColor<<L2>> #FB8C00
BackgroundColor<<L3>> #E8F5E9
BorderColor<<L3>> #43A047
FontSize 13
}
rectangle "**第一层:作者自审**(必做,不能跳)\n\n- 提交前跑一遍 ready-to-review 自检表(5 个问题)\n- AI 起草 Reviewer Note,作者本人看懂并背书" as L1 <<L1>>
rectangle "**第二层:AI Reviewer**(自动触发)\n\n- 本地 Codex /review、PR 端 Claude Code Review\n- 分维度审:安全 / 并发 / 可读性 / 测试覆盖\n- 测试用例当 Gate Verdict:跑过的部分不用人看" as L2 <<L2>>
rectangle "**第三层:人类 Reviewer**(按风险分配注意力)\n\n- 只看意图、边界、验证,不逐行读\n- 风险分级:🟢 扫一眼 / 🟡 看关键路径 / 🔴 逐段读\n- 大 MR 一律打回去拆" as L3 <<L3>>
L1 -down-> L2 : 作者签字后\n进入 AI 初审
L2 -down-> L3 : 机械问题已清光\n人类只看判断题
note right of L1
解决「闭眼批」:
作者答不上 5 个问题
= 这个 MR 还没准备好
end note
note right of L2
解决「同源污染」:
AI 是过滤器,不是裁判
end note
note right of L3
解决「逐行看」:
Approve 越来越值钱,
注意力必须省着花
end note
@enduml
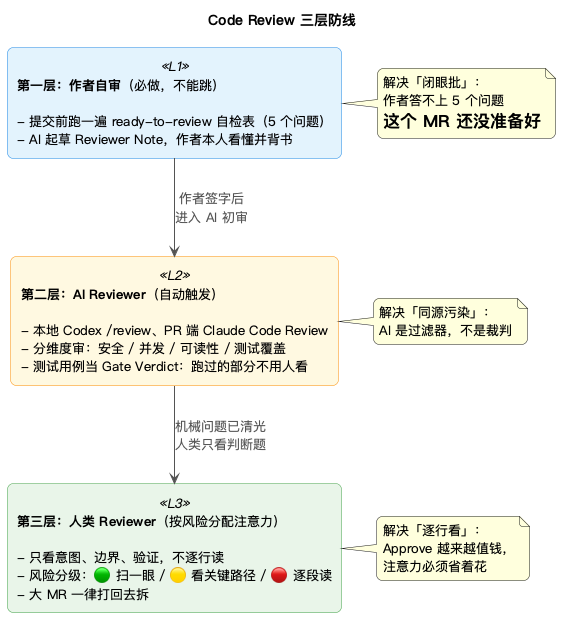
下面一层一层拆。
第一层:作者必须先"读懂自己提的代码"
这是最容易被忽略、也最关键的一层。
很多团队的隐性假设是:"反正后面有人 review,我先提上去再说。" 这种心态在 AI 时代是致命的。因为:
- AI 写的代码作者自己都不一定看懂
- reviewer 又是另一个不熟悉这段代码的人
- 结果两个不懂的人在那"对暗号",最后谁也不负责
我的硬规则是:任何一个 MR 提上来之前,作者必须能回答这五个问题。回答不上来,就不要 ready-for-review。
| # | 问题 | 不能回答说明什么 |
|---|---|---|
| 1 | 这个改动到底改变了什么行为? | 你没搞清楚自己提了什么 |
| 2 | 哪些场景不应该受影响? | 你没思考过 blast radius |
| 3 | 这段代码的关键执行路径是哪条? | 你没读懂自己的代码 |
| 4 | 最大的风险点在哪? | 你没做风险评估 |
| 5 | 如果上线出问题,怎么回滚? | 你没准备 plan B |
这套自检表的灵感来自 Reddit 上一个工程师的 "Ready for Review" 假设:测试验证代码做了什么;自检表验证作者懂不懂自己做了什么。
执行起来很简单:在 MR 模板里加一段,作者必须填,填不出来的 MR 不进 review 队列。
第二层:让 AI 替你过一遍机械活
人类擅长判断,AI 擅长扫描。这是基本分工。
我现在用的姿势:
1. Codex CLI 的 /review:提 MR 之前在本地跑一遍。Codex 会看整个仓库上下文,不只是 diff。常见命令:
codex
> /review
它会跑一轮初审,给出严重程度排序的问题列表。作者先解决一轮,再提 MR。
2. PR 端的自动 review:GitHub 这边可以开 Codex 的 PR review(一键开关),GitLab 这边可以用 Claude Code Review 或者团队自己写的 review skill。Anthropic 自己公布的数据是:上了 AI Code Review 之后,收到有意义反馈的 PR 从 16% 涨到 54%——一个 238% 的提升。
3. 分维度审,而不是一次性把所有问题喷出来。我自己写了一个 gitlab-mr-review skill(开源在 lazy-rabbit-skills,下文提到的 GitLab MR 系列 skill 都在这个仓库里),专门干这件事:传一个 MR URL 或者 namespace/project!iid 进去,它从 GitLab API 拉 diff 和上下文,然后一次只审一个维度——这一轮看安全,下一轮看并发,再下一轮看可读性,最后看测试覆盖。
这个"一次一个维度"的设计不是为了慢,是为了让 reviewer 的脑子能跟上。一次性喷 50 条混在一起的评论,等于没评论——人脑根本无法分类处理。分轮次出,每一轮的评论数量可控、主题集中,作者也好响应。
4. 关键的"信噪比":好的 AI reviewer 要的是少而准,不是多而吵。Anthropic 公布的数据是他们的系统漏报率以下、误报率低于 1%。如果你的 AI reviewer 一个 MR 喷 50 条意见,那它不是在帮你 review,它是在帮你制造噪音,需要换或者调 prompt。
5. 把测试当成质量门(Gate Verdict):我另一个 skill gitlab-mr-testcase 干的是这件事——结合 MR diff 和设计文档(或者从关联的 Jira 里自动捞),生成结构化的集成/验收测试用例,每个用例自带一个 Gate Verdict 块。
它的核心想法很简单:当所有生成的用例都跑过,reviewer 可以放心 ship 一个 AI 写的 MR 而不必逐行读;只要有一个用例挂了,那个挂掉的用例就精确指向了还需要人看的代码路径。
这正好接住了文章一开头的痛点——不看不放心,全看没时间。中间这条路不是"凭感觉点 Approve",而是"用测试把不需要看的部分挡掉,把人的眼睛留给真正需要判断的地方"。
这一层的产出是什么?是把所有"机械问题"清光——空指针、未处理的异常、明显的并发问题、漏写的日志、SQL 注入隐患——并且把"需要人看"和"可以不看"清晰地分开。人类 reviewer 不应该再花时间看那些 AI 能搞定的部分。
第三层:人类 reviewer 只看"判断题"
到了人这一层,你的注意力是最稀缺的资源。绝对不能再花在"找拼写错误"上。
人类 reviewer 该看什么?我总结成三个词:意图、边界、验证。
- 意图:这个改动想做什么?做的事和需求对得上吗?有没有顺手做了不该做的事?
- 边界:改动的范围是不是它声称的那个范围?有没有偷偷碰到了 auth/billing/migration 这种危险地带?
- 验证:测试覆盖了关键路径吗?跑过了吗?万一出问题怎么发现、怎么回滚?
注意,这三件事都不需要逐行读代码。读 diff 的目的不是"理解每一行做什么",而是"看一眼有没有意料之外的东西"。
按风险分配深度
人脑就这么多,必须分层。我的简单分类:
| 风险等级 | 判断标准 | 深度 |
|---|---|---|
| 🟢 低 | 文档、测试、UI 微调、< 50 行 | 扫一眼 diff + 看 CI |
| 🟡 中 | 业务逻辑改动、< 500 行 | 看意图 + 关键路径 + 关键测试 |
| 🔴 高 | 涉及 auth / 支付 / 数据迁移 / 协议变更 / > 1000 行 | 逐段读 + 拉作者过来讲一遍 |
这套不是教条,是给你一个心理上的"许可"——你不需要把每个 MR 都当成高风险来审,那是不可能完成的任务。
大 MR 的特殊处理:拆
如果一个 MR 1000 行以上,第一反应不应该是"我要 1500 分钟来审它",而应该是:"作者,请你把这个 MR 拆成 3 个"。
这不是刁难,是保护双方。Anthropic 的数据是:1000 行以上的 PR,84% 有问题,平均每个发现 7.5 个真实 bug。这个 bug 密度说明,大 MR 的认知负担已经超出了"安全审查"的边界。
但你会遇到一个现实问题:作者也不知道怎么拆。代码已经写完了,几十个文件错综交织,机械按文件分组通常会把一个完整的改动撕成两半,谁也跑不通。
我为这件事写了一个 gitlab-mr-split skill:它的设计前提就是"机械的文件分组不够用,需要 reviewer 的判断"。AI 会读整个 MR 的 diff 和上下文,按逻辑边界(而不是文件边界)提出几个可能的拆分方案,每个方案标注"哪一个子 MR 可以独立 review、独立合并、独立回滚"。作者拿到方案后,挑一个执行就行。
人的判断在前("要不要拆"、"拆成几个"),AI 的体力活在后("算出可行的拆法")。这才是正确的人机分工。
拒绝合并大 MR,是 tech lead 最该坚持的硬规则之一。有了 AI 帮忙拆,这条规则的执行成本从"得罪人"降到了"动动手指"。
一个具体的工具:Reviewer Note
这是我最近用得最顺手的小东西。
每个 MR 在 ready-for-review 之前,作者要附一个 Reviewer Note——不是写给 PM 看的需求描述,是写给 reviewer 看的"看这个 MR 的导览图"。
模板长这样:
## Reviewer Note
### 这个 MR 改了什么
(一段话,不超过 3 行)
### 关键改动文件
- `src/auth/login.go`:核心逻辑,重点看
- `src/utils/format.go`:纯重命名,扫一眼即可
- `tests/auth/login_test.go`:新增覆盖
### 风险点
- 改了 token 的过期逻辑,老 session 可能被踢
- 引入了一个新的依赖 X,需要确认 vendor 许可证
### 我做了哪些验证
- [x] 本地跑通所有单测
- [x] 手工测了登录/登出/超时三种场景
- [ ] 没测:双因素认证(环境搭不起来,求 reviewer 帮忙跑)
### 如果回滚
revert 单次 commit 即可,无数据迁移
这个 note 可以让 Claude/Codex 帮你起草,但作者要本人审阅一遍——因为这是你的签字背书,不是 AI 的。
效果是什么?据一些团队的反馈,加上 Reviewer Note 之后,reviewer 不再浪费时间猜"这个 MR 在干嘛",可以直接进入判断模式,平均审查时间下降、漏过的 bug 反而变少。具体数字因团队而异,建议自己跑一段时间,做个前后对比。
我自己最直观的感受是:以前打开一个不熟的 MR,前 5 分钟都在搞清楚"它到底想干嘛";有了 Reviewer Note 之后,这 5 分钟省下来了,注意力可以直接花在判断上。
一个常被忽略的细节:把规则写进 AGENTS.md
最后这一条,是 freeCodeCamp 那篇博客里一个工程师写的,我觉得特别对。
他原来是团队的 review 瓶颈,每天看不过来。后来他发现:他在 review 里反复留下的同一类评论,本质上应该写进 AGENTS.md / CLAUDE.md / .cursor/rules/,让 AI 在生成代码时就遵守。
举几个真实的例子:
- 你团队规定 controller 不能直接调 repository?写进
AGENTS.md,Claude 下次写代码就不会犯。 - 你团队规定日志不能打用户手机号?写进
AGENTS.md,下次 AI 会自动脱敏。 - 你团队规定 SQL 必须走预编译?写进
AGENTS.md,下次 AI 不会拼字符串。
每一条反复出现的 review comment,都应该被写成规则,让它从"事后纠错"变成"事前预防"。
这个动作的本质是:用 AI 的 leverage 反过来减少 review 的工作量。AI 写得快,那就让它一开始就按你的规矩写。
注意 freeCodeCamp 那篇文章里强调的两条经验:
- Rules 要短:长 rules 文件 = AI 会跳过的文件。一条规则超过两段就拆出去链接。
- Rules 要写成祈使句:
Controllers must not call repositories比Try to keep controllers thin强一万倍。第一句可测试,第二句是装饰。
顺手再补一个下游的小动作。review 里经常会留下一堆"这次先不改,下次再说"的悬而未决的评论。这些评论最容易烂掉——评论在 MR 上,事情没人跟,三个月后大家都忘了。我写了个 gitlab-mr-issue skill 解决这个:扫一遍 MR 上未解决的 review thread,挑出"应该变成 follow-up 工单"的那些,生成 issue 草稿,让作者确认后一键创建到对应 repo。review 不是终点,没解决的评论必须有去处。
再补一刀:让 AI 帮你建一份"活着的"项目知识库
AGENTS.md 解决的是新代码不犯老错,但 review 还有另一个大头时间——看不懂这块代码原本长什么样。
reviewer 打开一个陌生模块的 MR,最耗神的从来不是看 diff,而是补上下文:
- 这个模块在整个系统里处于什么位置?
- 它依赖谁?谁依赖它?
- 当初为什么这么设计?有没有 ADR 可以查?
- 这条调用链跑下来会路过哪些服务?
这些问题如果每次 review 都现场问作者、现场翻代码、现场画图,时间一定爆。
我自己写了一个 Project Knowledge Base(PKB)的 skill(同样开源在 lazy-rabbit-skills),就是为了解决这件事。它让 AI 把一个 repo 嚼一遍,自动产出一套给人和 AI 都能读的项目知识库:
- Repo Map:仓库结构、关键模块、入口点
- C4 架构叙述:从 Context 到 Component 一层层画清楚(PlantUML / Mermaid 图自动生成)
- ADR(Architecture Decision Records):把"当初为什么这么设计"沉淀下来
- Runbook:常见操作、故障处理、回滚步骤
- 最后用 Sphinx + MyST 发布成 HTML,可以双语,可以搜索
它的关键不是"生成一份漂亮文档放着",而是:
- 图 + 文比纯代码好读 10 倍:reviewer 看 MR 之前先扫一眼 C4 Container 图,5 秒钟知道这次改动落在哪一块
- AI 自己也能读 PKB:你下次让 Claude 帮你写代码,它先读 PKB,写出来的东西就贴合你的架构,而不是凭空捏造
- 活文档:每次大的改动都触发 PKB 更新,文档不会腐烂
这套东西的本质,是把"可理解性"这件事从口口相传变成可索引的资产。reviewer 不再需要每次问作者"这块代码为什么这样",他可以直接查 PKB;作者也不再需要每次都口头讲一遍架构,他指给 reviewer 看一张图。
review 慢,很多时候慢在"补上下文"。把上下文沉淀下来,review 就快了。
如果你团队还没有这种东西,强烈建议搭一个。开源工具不少,我自己那套 skill 后面专门写一篇展开聊。
总结:从"看代码"到"管 review"
这篇文章的核心观点压缩成一句话:
当 AI 把"写代码"的速度提升 10 倍时,你不能再用同样的姿势去 review。你必须从"逐行审代码"升级到"分层管 review"。
这是一种心态切换。从工匠(每一行代码亲眼看过)变成产品经理(在有限注意力下做最优分配)。
不是降级,是升级。
行动清单(明天就能用)
- [ ] 给团队加一个 MR 模板,强制作者填 ready-to-review 自检表(5 个问题)
- [ ] 给每个 MR 强制附 Reviewer Note,AI 起草,作者背书
- [ ] 开启 Codex
/review或 Claude Code Review,把机械问题挡在人类之前 - [ ] AI Reviewer 分维度审,一次一个主题,别一次喷 50 条
- [ ] 用测试用例当 Gate Verdict,能跑过的部分不用人逐行看
- [ ] 给 MR 加风险分级(🟢🟡🔴),按风险分配深度
- [ ] 给 1000 行以上的 MR 设硬上限,超过的强制拆分(让 AI 按逻辑边界给方案)
- [ ] review 留下的未解决评论,统一转成 follow-up issue,不要烂在 MR 里
- [ ] 把每周高频出现的 review 评论,整理进
AGENTS.md/CLAUDE.md - [ ] 给项目搭一份 PKB(Repo Map + C4 图 + ADR + Runbook),让 reviewer 不用每次现场补上下文
- [ ] 一个月后回头看:reviewer 平均时间 vs. 漏过的 bug 数,量化复盘一次
一句话送给所有 tech lead
你的 Approve 按钮越来越值钱了。从今天起,按下去之前,问自己三个问题:意图清楚吗?边界守住了吗?验证够吗?
如果三个都答得上来,放心点。答不上来,把 MR 打回去——这不是不近人情,这是对线上系统的尊重。
延伸阅读
- AI coding is no longer the bottleneck. Review readiness is. (Reddit)
- How to Unblock Your AI PR Review Bottleneck (freeCodeCamp)
- AI Reviews Your Code Before You Even Open the PR (dev.to)
- 本文涉及的所有 skill 都开源在:walterfan/lazy-rabbit-skills(
gitlab-mr-review/gitlab-mr-split/gitlab-mr-testcase/gitlab-mr-issue/project-knowledge-base) - 本站姊妹篇:AI 辅助编程的三大护法:可验证性、可观测性、可理解性