传统 Java 项目用 AI 写代码总翻车?先把 harness 修好
Posted on 日 07 6月 2026 in Tech
| Abstract | 传统 Java 项目用 AI 写代码总翻车?先把 harness 修好 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v0.1 |
| Updated | 2026-06-07 |
| License | CC-BY-NC-ND 4.0 |
传统 Java 项目用 AI 写代码总翻车?先把 harness 修好
短大纲
- AI 写小函数像换了个人,写大功能却像喝多了——问题多半不在模型,在 harness
- harness 是什么:把 AI 当一个聪明、手快、但失忆、看不到全局、不敢负责的新外包
- 为什么 Spring Boot + MyBatis + MySQL + Kafka 这套尤其难啃
- PKB / SDD / DDD / TDD / BDD / MDD:不是六个时髦缩写,是 harness 的六块拼图
- 别六味药一起灌:一个传统 Java 项目的渐进落地顺序
一、小函数封神,大功能翻车
先说个我自己反复遇到的场景。
让 AI 写一个工具方法——金额格式化、时间窗口计算、把一段 JSON 拍平——它行云流水,几乎不用改。可一旦把它放进真正的业务里:"给订单服务加一个退款流程,要写 Controller、Service、MyBatis Mapper,发一条 Kafka 消息通知履约,还要处理幂等和事务回滚"——它就开始上头了。
典型翻车现场有这么几种:
- 改 A 坏 B。 它给你加了退款逻辑,顺手把旁边一个共享的状态枚举改了,结果另一条支付链路悄悄挂了。
- 凭空发明。 Mapper 里调了一个根本不存在的方法,或者编了一个看起来很像、其实没有的工具类。
- 绕过约定。 项目里事务边界、幂等键、Kafka 消费的去重规则都有不成文的规矩,它一个都不知道,写出来"能编译、能跑、就是不对"。
- 顾此失彼。 你提醒它注意幂等,它就忘了事务;你强调事务,它又把日志里打了一堆敏感字段。
很多人第一反应是:"是不是模型不够强?换个更贵的?"
我的看法正相反:大部分翻车,换模型救不了,得修 harness。 模型是发动机,harness 是底盘、轨道和护栏。发动机再猛,没有轨道,照样冲下悬崖。小函数之所以稳,是因为它"上下文自足"——一个方法的全部信息就在那几行里。大功能之所以崩,是因为它的关键信息根本不在代码里,而在老员工的脑子里、在散落的 XML 里、在三年前某次线上事故的教训里。AI 看不见这些,自然就抓瞎。
二、harness 到底是什么
一句话:harness 就是你给 AI 准备的工作环境和约束系统,让它即使失忆、即使看不全局,也能干出靠谱的活。
要理解它,最好的办法是把 AI 当成一个具体的人来看待。我带过外包、带过实习生,AI 现在的状态特别像一个聪明、手快、但失忆、看不到全局、还不敢负责的新外包:
- 聪明、手快:给定清晰的小任务,它写得又快又好。
- 失忆:每次对话都像第一天上班,昨天讲过的约定它不记得。
- 看不到全局:它只能看到你喂给它的上下文,看不到整个系统是怎么转的。
- 不敢负责:它不会半夜被电话叫醒,也不为线上故障背锅,所以它对"会不会出事"没有切肤之痛。
那么问题就清楚了:你怎么让一个这样的新人,在你那套盘根错节的老系统里干好活?
你不会指望他无师自通。你会给他入职文档(让他看得见全局)、划定他负责的模块(让他别乱碰别人的地盘)、给他明确的任务单和验收标准(让他知道做成什么样算对)、配一套自动化测试和 CI(让他一旦改坏了立刻被拦住)、再用一些指标盯着整体质量别滑坡。
把这几件事做到位,就是修 harness。PKB、SDD、DDD、TDD、BDD、MDD,本质上就是在补这套环境的不同短板。
三、为什么传统 Java 项目特别难
同样是用 AI,为什么 Spring Boot + MyBatis + MySQL + Kafka 这套传统企业级 Java 比一个小巧的 Go 服务难伺候得多?因为它隐性知识密度太高,而这些知识恰恰不在 AI 能看到的地方。
| 技术点 | 藏起来的隐性知识 | AI 容易踩的坑 |
|---|---|---|
| Spring 依赖注入 | 谁注入谁、AOP 切在哪、事务代理在哪一层生效 | 在内部方法直接调用导致 @Transactional 失效 |
| MyBatis | SQL 散落在一堆 XML 里,动态 SQL、resultMap 映射全靠约定 | 编一个不存在的 Mapper 方法,或写出 N+1 查询 |
| MySQL | 索引、唯一约束、隔离级别、分库分表规则 | 写出走不到索引的慢查询,或撞唯一键 |
| Kafka | 消费幂等、重试、死信、分区顺序、at-least-once 语义 | 消费不去重,重复消息导致重复退款 |
| 分层架构 | Controller/Service/Mapper 的职责边界与命名约定 | 业务逻辑写进 Controller,或绕过 Service 直连 Mapper |
你看,这些坑没有一个是"算法难",全是"规矩多"。规矩多而不成文,正是 AI 的天敌,也是老项目交接给新人时最疼的地方。AI 只是把这个老问题,用更快的速度、更大的规模,重新演了一遍给你看。
结论:传统 Java 项目用 AI 的瓶颈,不是智能,是上下文和约束。 而上下文和约束,正是 harness 要解决的。
四、六味药:把缩写还原成 harness 的拼图
PKB、SDD、DDD、TDD、BDD、MDD 单独看是六个流派,容易让人觉得"又来一堆方法论"。但如果用 harness 这个视角串起来,它们其实各补一块短板,谁也替不了谁。
| 缩写 | 全称 | 补的是 harness 哪块短板 | 解决 AI 的什么毛病 |
|---|---|---|---|
| PKB | Project Knowledge Base | 上下文:把隐性知识显性化 | 失忆、看不到全局 |
| DDD | Domain-Driven Design | 边界:划清领域和模块 | 改 A 坏 B、blast radius 太大 |
| SDD | Spec-Driven Development | 规约:先定义再实现 | 大功能没拆解、目标含糊 |
| TDD | Test-Driven Development | 回归网:先有红绿灯 | 改坏了没人拦、不敢重构 |
| BDD | Behavior-Driven Development | 行为契约:业务可执行化 | 业务语义对不上、边界 case 漏掉 |
| MDD | Metrics-Driven Development | 度量:量化反馈闭环 | 不知道质量在涨还是在滑 |
下面挨个说,怎么落到一个真实的 Java 项目里。重点不是定义,而是怎么用。
1. PKB:先把"老员工脑子里的东西"写下来
这是性价比最高、也最该第一个做的。AI 最大的痛点是失忆和看不见全局,那就给它一份它每次都能读到的入职文档。
实操:在仓库根目录建一个 AGENTS.md(或 CLAUDE.md),但别写成正确的废话。 我见过太多团队的 AGENTS.md 写的是"本项目采用分层架构,请遵循最佳实践"——这种话 AI 看了等于没看。真正有用的,是写下那些只有踩过坑的人才知道的、不成文的规矩。一个能直接抄的骨架:
# AGENTS.md — order-service
## 系统地图
- order-api:对外 REST,只做参数校验和编排,禁止写业务逻辑
- order-domain:核心业务,退款/状态机都在这
- order-infra:MyBatis Mapper、Kafka 生产者、外部 RPC
## 必须遵守的约定(踩过坑的)
1. 事务只加在 *Service 的 public 方法上;同类内部方法互调会让 @Transactional 失效,要拆到另一个 Bean。
2. 所有 Kafka 消费必须幂等,幂等键 = bizType + bizId,落 t_idempotent 表,唯一索引兜底。
3. 金额一律用 BigDecimal + 分为单位的 long,禁止 double。
4. 日志禁止打 手机号/身份证/卡号,用 LogMask.of(xxx)。
5. Mapper 方法命名:selectXxxByYyy / insertXxx / updateXxxByZzz,别自创。
## 标准样板:一个带 Kafka 通知的写操作
见 RefundService.refund() —— 改任何写链路前先读它,照着这个结构来。
三件事最值得写:系统地图(谁依赖谁)、踩过坑的约定(事务/幂等/金额/脱敏)、一个可抄的样板方法。再加一个 docs/adr/ 放架构决策记录,把"为什么用 Kafka 不直接 RPC""为什么这张表不能加外键"留下来,AI 才不会好心办坏事。
还有个被忽略的实操点:喂上下文要精准。 让 AI 改退款时,与其让它"自己去仓库里找",不如直接把相关文件拍给它——RefundService.java、RefundMapper.xml、RefundMessage.java、对应的 @KafkaListener。AI 不是检索引擎,你喂得准,它才答得准。
一句话:PKB 是把交接文档写给 AI 看。 顺带好处是,新来的人也省事了。
2. DDD:给 AI 划一块它能负责的地盘
AI 改大功能翻车,很多时候是因为它不知道边界在哪,于是越改越远,把不该碰的也碰了。DDD 的限界上下文(Bounded Context)和模块化,正好给它画一个圈:"你只在订单域里折腾,支付域、履约域别动。"
落地不必一步到位上聚合根、领域事件那一整套。在传统 Java 项目里,先做三件最朴素、ROI 最高的事:
第一,按领域分包,让目录结构本身就是边界。 AI 一看路径就知道自己该待在哪:
com.example.order
├── order # 订单域:下单、查询
├── refund # 退款域:本次要改的就是这块
│ ├── api # RefundController
│ ├── service # RefundService(业务都在这)
│ ├── domain # RefundOrder 状态机
│ └── infra # RefundMapper、RefundProducer
└── fulfillment # 履约域:退款只能通过事件通知它,不许直接调
第二,跨域只走显式接口,不许直连别人的 Mapper。 退款要通知履约,就定义一个接口,而不是在 RefundService 里 @Autowired FulfillmentMapper:
// 退款域只依赖这个接口,看不见履约域的实现细节
public interface FulfillmentNotifier {
void onRefunded(long orderId);
}
第三,用一条会失败的测试把边界焊死(这其实是第 6 味 MDD 的预演,ArchUnit 是什么、怎么用,下面第 6 味会展开讲),用 ArchUnit:
@ArchTest
static final ArchRule 退款域不许直连履约的Mapper =
noClasses().that().resideInAPackage("..refund..")
.should().dependOnClassesThat().resideInAPackage("..fulfillment.infra..");
边界画清楚、还有测试守着之后,AI 即使犯错,爆炸半径也被关在一个房间里,而不是炸穿整栋楼。
3. SDD:把"大功能"先拆成有验收标准的规约
AI 写大功能差强人意,一个朴素原因是:你给的就是个大需求,它只能一边猜一边写。Spec-Driven Development 的思路是先写规约,再让 AI 实现——而且规约最好由人把关。
实操:在动手之前,先和 AI 一起把一页规约写出来,存成 docs/specs/refund.md,你审完再让它写代码。 与其甩一句"给订单加个退款",不如先逼出这页东西:
# Spec: 订单退款
## 状态流转
已支付 → 退款中 → 已退款 / 退款失败
(只有"已支付/已完成"可发起;"退款中"不可重复发起)
## 验收标准(每条对应一个测试)
- [ ] AC1 正常全额退款:状态→已退款,发 RefundedEvent
- [ ] AC2 重复退款请求:第二次直接返回首次结果,不重复退款
- [ ] AC3 未支付订单退款:抛 BizException(ORDER_NOT_REFUNDABLE)
- [ ] AC4 退款金额 > 可退金额:拒绝
- [ ] AC5 下游扣款失败:事务回滚,状态不变
## 非功能
- 幂等键 = "refund:" + orderId;t_idempotent 唯一索引兜底
- 事务边界:RefundService.refund() 整体一个事务
- Kafka:topic=order.refunded,消息含 orderId/amount/refundId
关键一步是把它拆成任务清单(很多 AI 工具支持 spec → tasks → implement 这个流程),让 AI 一个任务一个任务做、你一个一个验:
1. 建 t_idempotent 表 + Mapper(DDL + XML)
2. RefundOrder 状态机:canRefund() / markRefunding() / markRefunded()
3. RefundService.refund():幂等检查 → 状态流转 → 落库 → 发消息(对应 AC1/AC2/AC5)
4. RefundController + 参数校验(对应 AC3/AC4)
5. order.refunded 的生产与消费
把一个它做不好的大功能,变成五个它能做好的小任务——这正好把 AI 的长板(小任务)和短板(大局观)对齐了。每个任务都有对应的 AC,做完就能验,谁也别想糊弄过去。
4. TDD:给 AI 装一套红绿灯
"改 A 坏 B"这种事,靠人眼 review 是兜不住的,越是老项目越兜不住。唯一可靠的护栏是回归测试网。
用 AI 时,TDD 还有个额外好处:测试就是最精确的 prompt。与其用自然语言反复描述"我要什么",不如先把上一节的验收标准翻译成测试,把期望钉死,再让 AI 去实现,直到变绿。
实操:先写测试,再让 AI 实现。 比如把 AC2(重复退款)写成一个测试,这就是给 AI 的"题面":
@Test
void 重复退款请求_第二次不应再次退款() {
Order order = givenPaidOrder(1001L, 100_00);
refundService.refund(new RefundCmd(1001L, 100_00)); // 首次
RefundResult second = refundService.refund(new RefundCmd(1001L, 100_00));
assertThat(second.isDuplicated()).isTrue();
verify(refundProducer, times(1)).send(any()); // 只发一次消息,没退第二次
}
把这个(还有 AC1/AC3/AC5 对应的测试)一起丢给 AI:"让这些测试变绿。"它就有了客观的成功标准,不再自我感觉良好;一旦它碰坏了别处,对应的红灯立刻亮,而不是上线后才发现。
对老项目,还有个救命用法:在让 AI 重构前,先用它给老代码补一层"特征测试"(characterization test)。 不管现有逻辑对不对,先把它"当前的行为"固化成测试,再让 AI 重构——只要这些测试还绿,就说明它没改变现有行为。别想着一次补全,护栏跟着战线走,你让 AI 动哪块,就先给哪块织网。
5. BDD:把关键业务行为变成可执行契约
TDD 偏技术正确,BDD 偏业务正确。它用 Given / When / Then 把业务行为写成几乎是大白话的场景,特别适合 Kafka 消费、状态机这类"逻辑复杂、边界一堆"的地方。
实操:用 Cucumber 把核心业务流写成 .feature 文件,它既是文档也是测试。 比如退款消费的幂等场景:
# refund.feature
场景: 重复收到退款消息时不能退两次
假如 订单 1001 已经退款成功
当 系统再次收到订单 1001 的退款消息
那么 不应该再发起一次退款
并且 账户余额保持不变
然后写一次 step 定义把它接到代码上(之后所有场景复用):
@当("系统再次收到订单 {long} 的退款消息")
public void 再次收到退款消息(long orderId) {
refundListener.onMessage(new RefundMessage(orderId, 100_00));
}
@那么("不应该再发起一次退款")
public void 不应再次退款() {
verify(refundService, times(1)).refund(any());
}
这种场景对 AI 极其友好:它把容易被忽略的边界 case(重复消息、乱序、超时、死信)显式摆上台面,AI 不用猜业务语义,照着场景实现即可。对人也友好——产品、测试、开发看的是同一份契约,开会时不用再为"这种情况到底该咋办"扯皮。
BDD 不必全项目铺开(写多了维护成本不低)。只给那几条最怕出错、最难讲清楚、最容易扯皮的核心业务流写,比如退款幂等、状态机流转——就够本了。
6. MDD:用度量盯住 harness 有没有真在起作用
最后一块拼图,是度量驱动开发(Metrics-Driven Development)。这里得先澄清一个歧义:MDD 也常指 Model-Driven Development(模型驱动开发)。在 AI 协作这个语境下,我更愿意取度量驱动这层意思——这也是我那本《微服务之道:度量驱动开发》一直在讲的事。
前面五味药都做了,怎么知道它们真在起作用、而不是自我感动?靠指标,而且关键在于把指标接进 CI 变成会拦人的闸门,而不是挂在墙上看。
实操一:覆盖率不达标就构建失败。 用 JaCoCo 卡一条线,别再"覆盖率仅供参考":
<rule>
<element>BUNDLE</element>
<limits>
<limit><counter>LINE</counter><minimum>0.70</minimum></limit>
</limits>
</rule>
实操二:用 ArchUnit 把不成文的规矩变成会失败的测试。
这里多说几句 ArchUnit,因为它是把"架构约定"变成"自动闸门"的关键,很多人没用过。
一句话:ArchUnit 就是 JUnit。 它是一个普通的 Java 测试库(加一个 Maven/Gradle 依赖即可),你用它写的"架构规则"本质上就是测试用例,跟着 mvn test 一起跑,违反了就变红——和你熟悉的单元测试体验一模一样,只不过它断言的不是"某个函数返回值对不对",而是"代码的结构、依赖、命名守没守规矩"。
它的工作原理也很朴素,三步:
- 把字节码读进来——用
ClassFileImporter扫描你的包,得到一批JavaClasses(就是"所有类的元信息")。 - 声明一条规则——用近乎大白话的链式 API 描述"谁不许依赖谁""谁必须叫什么名"。
- 断言——
rule.check(classes),违反就抛异常、测试失败。
最省事的写法是用 @AnalyzeClasses + @ArchTest,框架自动帮你导入和执行:
@AnalyzeClasses(packages = "com.example.order") // 扫这个包
class ArchitectureTest {
// 规则1:Controller 不许直连 Mapper(必须经过 Service)
@ArchTest
static final ArchRule controller不许直连Mapper =
noClasses().that().resideInAPackage("..api..")
.should().dependOnClassesThat().resideInAPackage("..infra.mapper..");
// 规则2:退款域不许碰履约域的实现,只能走接口
@ArchTest
static final ArchRule 退款域不许直连履约 =
noClasses().that().resideInAPackage("..refund..")
.should().dependOnClassesThat().resideInAPackage("..fulfillment.infra..");
// 规则3:命名约定——Service 实现类必须叫 *ServiceImpl
@ArchTest
static final ArchRule service命名约定 =
classes().that().resideInAPackage("..service..")
.and().areNotInterfaces()
.should().haveSimpleNameEndingWith("ServiceImpl");
// 规则4:分层依赖方向(api → service → infra,不许反向)
@ArchTest
static final ArchRule 分层依赖方向 =
layeredArchitecture().consideringOnlyDependenciesInLayers()
.layer("Api").definedBy("..api..")
.layer("Service").definedBy("..service..")
.layer("Infra").definedBy("..infra..")
.whereLayer("Api").mayNotBeAccessedByAnyLayer()
.whereLayer("Service").mayOnlyBeAccessedByLayers("Api");
}
为什么它在 AI harness 里这么值?因为 AI 改代码时最容易破坏的就是这种"看不见的结构约定"——它编译能过、功能能跑,但悄悄让 Controller 直连了 Mapper、让两个领域循环依赖了。AGENTS.md 里写的约定,AI 可能不读、读了也可能忘;但 ArchUnit 写的约定,AI 绕不过去——一违反,红灯就亮。等于把你脑子里的架构纪律,变成了一个不知疲倦、从不讲情面的自动审查员。
实操建议:别一上来写几十条。先把 3~5 条最常被破坏的规矩固化(分层方向、领域边界、Controller 不碰 Mapper、命名约定),跟着 CI 跑。报错信息很友好,会直接告诉你"哪个类违反了哪条规则",新人和 AI 都能照着改。
实操三:CI 里串成一道闸门,任意一条红就不许合并:
# .gitlab-ci.yml 片段
verify:
script:
- mvn test # TDD + BDD 用例
- mvn verify -Pcoverage # JaCoCo 覆盖率门槛
- mvn test -Parchunit # 架构 fitness
- mvn spotbugs:check # 静态/安全扫描
MDD 让 harness 从"靠自觉"升级成"靠闸门"。 闸门一立,AI(和人)就再没法绕过约定偷偷上线了——说到底,没有度量的改进,都是自我感动。
五、别六味药一起灌:一个渐进落地顺序
看到六个缩写就想全上,是最容易劝退团队的做法。它们投入产出比差很多,老项目又经不起折腾。按我的经验,给一个从止血到治本的顺序:
- PKB 先行(ROI 最高):写
AGENTS.md+ 系统地图 + 关键约定 + 一个全链路样板。一两天,立竿见影。 - TDD 兜底:给你接下来要让 AI 动的模块补回归测试,别贪全。
- DDD 划界:把目录/模块按领域理清,先把边界做出来,聚合根那套以后再说。
- SDD 拆活:从此大功能先写规约、拆任务,再让 AI 逐个实现。
- BDD 补关键业务:给最怕错的核心流程(如 Kafka 退款消费)写 Given/When/Then。
- MDD 上闸门:把覆盖率、架构 fitness、lint 接进 CI,变成不可绕过的红绿灯。
记住一个判断标准:每加一块拼图,都要让 AI 干活的成功率肉眼可见地往上走,而不是为了方法论而方法论。
总结
回到最初那个问题:传统 Java 项目逻辑复杂、代码繁复,AI 写小函数行、写大功能差强人意,怎么办?
一句话:别急着换模型,先修 harness。 AI 是个聪明但失忆、看不到全局、不敢负责的新外包;你要做的,是把一个连老员工都得带半年的老系统,改造成一个新人也能上手干活的环境。PKB 给它上下文,DDD 给它边界,SDD 给它任务单,TDD 给它红绿灯,BDD 给它业务契约,MDD 给它度量闸门。六块拼图拼齐,AI 才能从"小函数封神"走到"大功能也靠谱"。
这事的本质,其实不新鲜:让 AI 写好代码的功夫,和让一个团队写好代码的功夫,是同一份功夫。 你为 AI 修的 harness,最后受益的也是每一个活人。
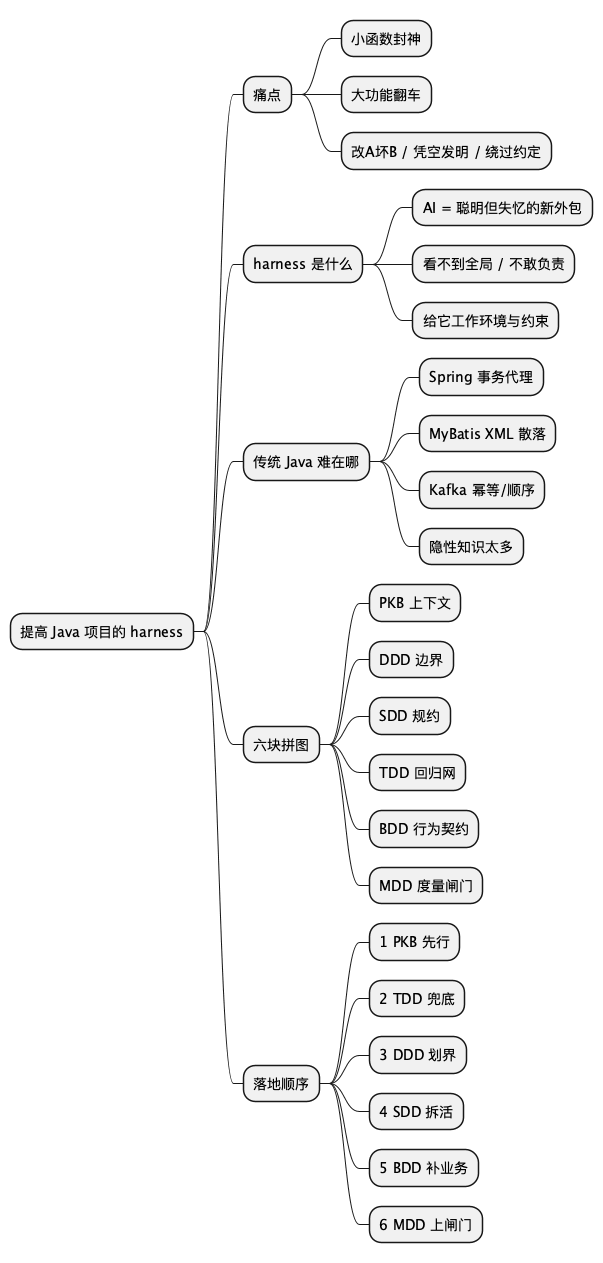
思维导图
@startmindmap
* 提高 Java 项目的 harness
** 痛点
*** 小函数封神
*** 大功能翻车
*** 改A坏B / 凭空发明 / 绕过约定
** harness 是什么
*** AI = 聪明但失忆的新外包
*** 看不到全局 / 不敢负责
*** 给它工作环境与约束
** 传统 Java 难在哪
*** Spring 事务代理
*** MyBatis XML 散落
*** Kafka 幂等/顺序
*** 隐性知识太多
** 六块拼图
*** PKB 上下文
*** DDD 边界
*** SDD 规约
*** TDD 回归网
*** BDD 行为契约
*** MDD 度量闸门
** 落地顺序
*** 1 PKB 先行
*** 2 TDD 兜底
*** 3 DDD 划界
*** 4 SDD 拆活
*** 5 BDD 补业务
*** 6 MDD 上闸门
@endmindmap
行动清单
- 今天就建一个
AGENTS.md:写下系统地图、3 条最容易被踩的约定(事务边界、Kafka 幂等键、日志脱敏)、一个全链路样板。 - 挑一个你最近要改的模块,先补 3~5 个回归测试,再让 AI 动手。
- 把下一个"大功能"先写成一页规约 + 任务清单,再分小任务交给 AI。
- 给最怕出错的那条业务流(如重复消息)写一个 Given/When/Then 场景。
- 在 CI 里加一条会失败的架构断言(如"Controller 不许直接调 Mapper"),让边界变成闸门。
扩展阅读
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。