RAG Architecture
Table of Contents
A typical RAG application has two main components:
-
Indexing: a pipeline for ingesting data from a source and indexing it. This usually happens offline.
-
Retrieval and generation: the actual RAG chain, which takes the user query at run time and retrieves the relevant data from the index, then passes that to the model.
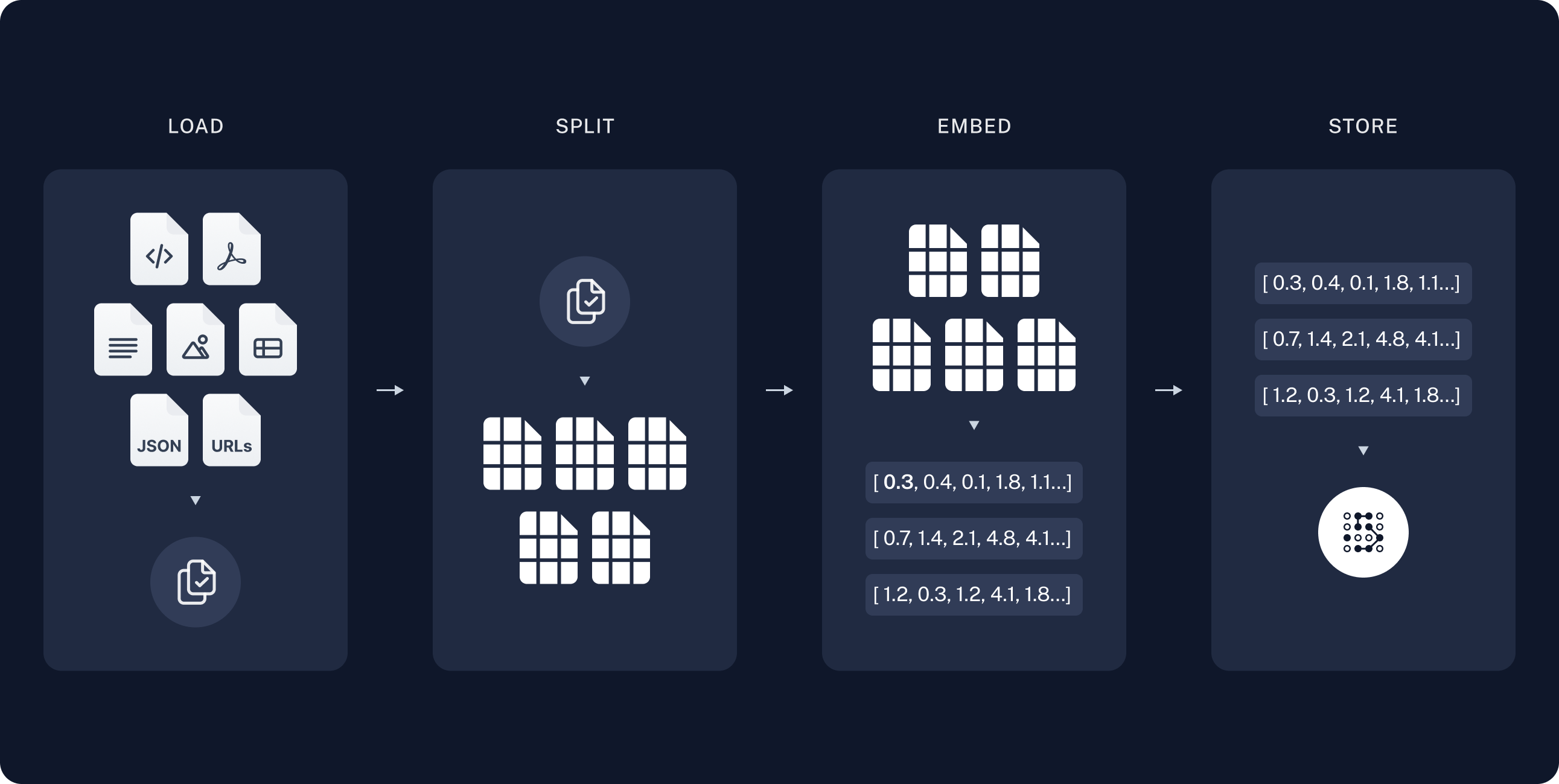
The most common full sequence from raw data to answer looks like:
Indexing
- Load: First we need to load our data. This is done with DocumentLoaders.
- Split: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won't fit in a model's finite context window.
- Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
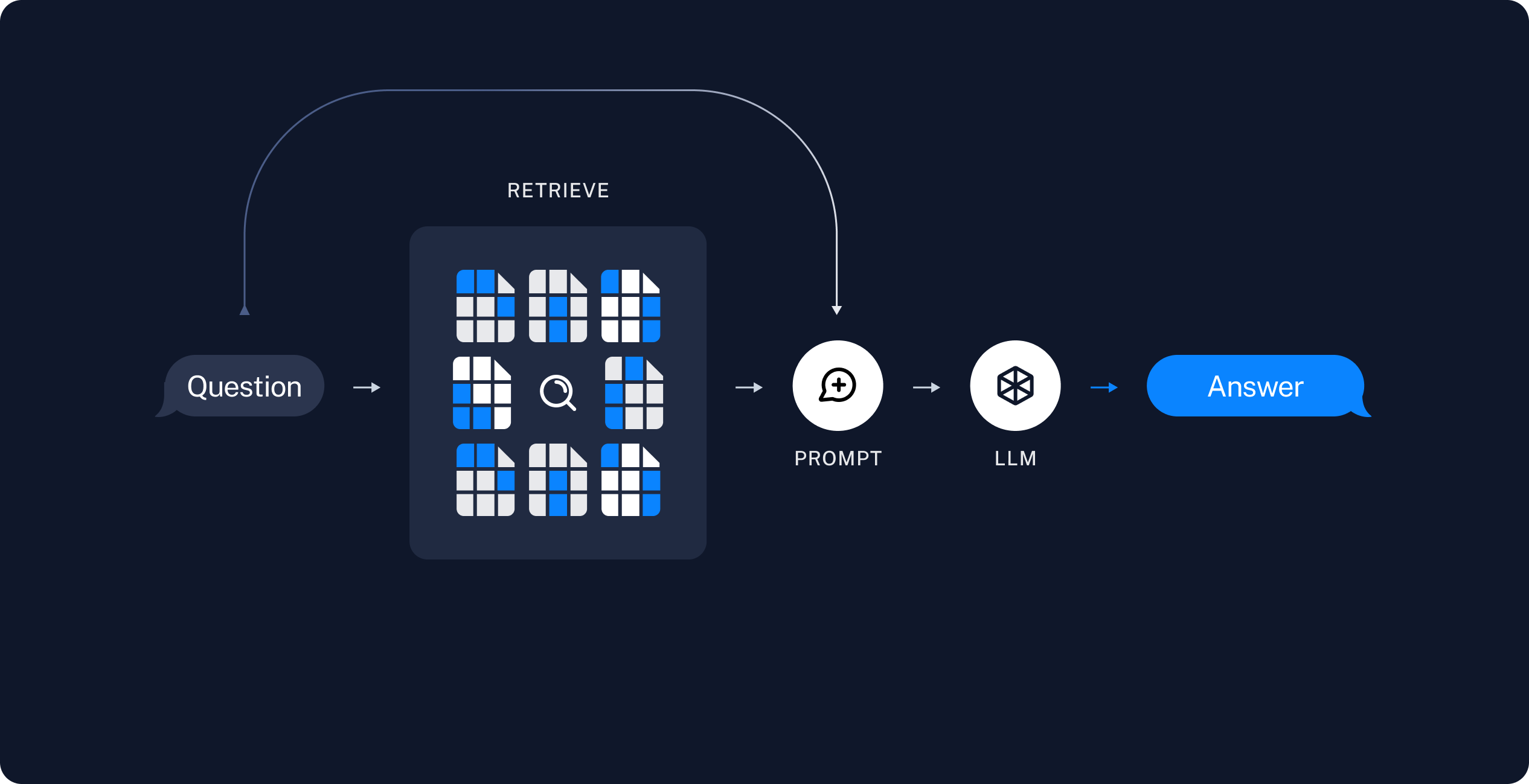
Retrieval and generation
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
- Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
Comments |0|
Category: 似水流年