gstack 拆机报告:AI 编程脚手架做对了什么,又栽在哪里
Posted on 六 23 5月 2026 in Tech
| Abstract | gstack 拆机报告 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v1.0 |
| Updated | 2026-05-23 |
| License | CC-BY-NC-ND 4.0 |
周六上午我把 gstack clone 下来看,本来想十分钟扫一眼就关。结果一个上午没出书房——这玩意值得拆。
gstack 是 Y Combinator 的 Garry Tan 开源的 Claude Code 脚手架。一句话讲:它把一个工程团队的每个角色——CEO、Eng Manager、Designer、Reviewer、QA、Release Engineer——都做成了 slash command,AI 写代码时按 sprint 一关关跑过去。
跑了一两次之后,我有几个矛盾的感受:方法论很硬,工程基本功扎实,但工具栏拥堵到让我这种老程序员也会犯怵。这篇拆给你看哪些值得偷师,哪些是 AI 时代项目的通病,以及自己做类似项目时怎么避坑。
立场先放在前面:我不是粉、也不是黑。Garry 是真正在大量产出的人,方法论有现场感。但工程归工程,方法论归方法论,拆的时候按工程标准看。
一、做对的事
1. Sprint as Skills:把流程角色化
这是 gstack 最锋利的一刀。
传统 AI 编程是一个对话框:你说"帮我加个限流",AI 一口气写代码、写测试、写文档,全在一个 context 里。问题是 AI 的角色被你压扁了——它既当架构师又当码农,既负责出主意又负责挑毛病,最后哪个角色都不到位。
gstack 的做法是把 sprint 解耦:
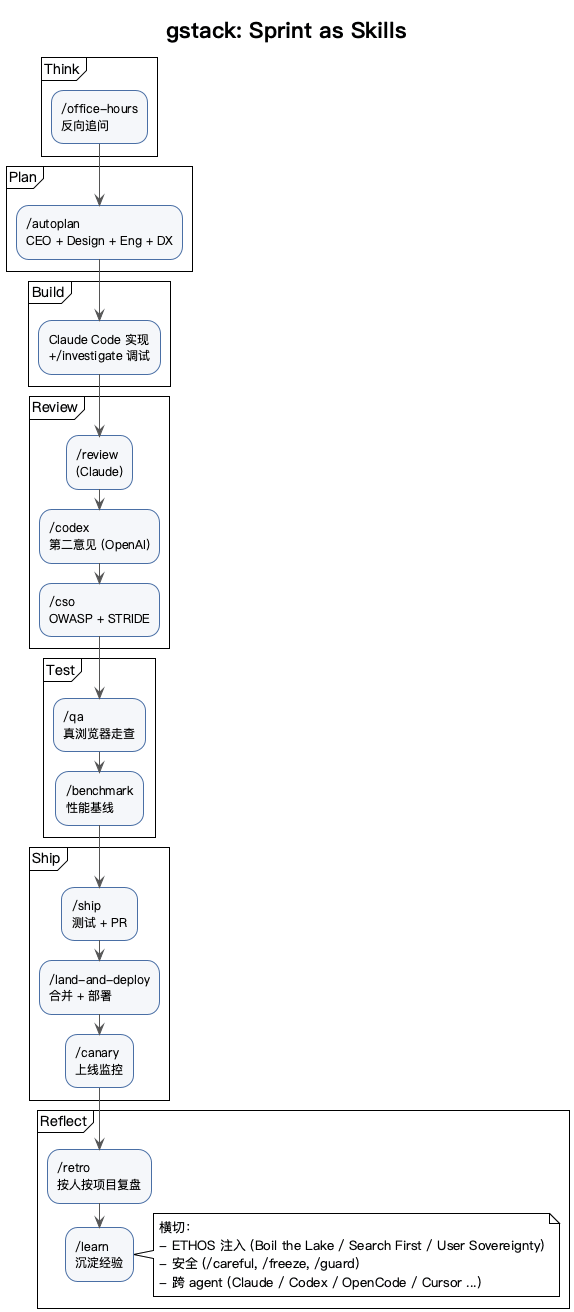
每个阶段是一个 slash command,每个 command 对应一个明确的"虚拟角色"和一份 SKILL.md。/office-hours 是 YC 风格的产品反向追问,/plan-ceo-review 是 CEO 视角挑大方向,/plan-eng-review 落架构和测试,/review 是 Staff Engineer 找代码气味,/cso 跑 OWASP + STRIDE。
好处是显而易见的:
- AI 的注意力被框住。一次只扮一个角色,不会自己跟自己绕
- 流程可暂停、可重入。每一关有产出物(design doc / plan / review report),下一关读它
- 责任清晰。
/review没挑出的 bug,是 review 这一关的事,不是 QA 的事
这件事的本质,是把"AI 写代码"从对话题升级成了有工序的流水线。这条思路本身比 gstack 这个具体实现重要。
2. ETHOS 注入:给 AI 写一份"为什么"
gstack 仓库里有一份 ETHOS.md——160 多行的"建造者信条",会被自动注入到每个 workflow skill 的 preamble 里。
里面真正有营养的有三条:
- Boil the Lake:AI 时代"完整实现"的边际成本几乎为零,要做就做完整的,别再为了省时间留 90% 的方案
- Search Before Building:把知识分成三层(Tried-and-true / New-and-popular / First principles),动手前先搜,搜完再判断
- User Sovereignty:两个 AI 模型意见一致也不是真理,用户永远拥有最终决定权,AI 只能 recommend
这三条不是装饰。它们决定了 AI 在每个 skill 里怎么思考。
我最欣赏的是 User Sovereignty:明确写了"当 Claude 和 Codex 都说应该合并这两个东西,而用户说不要——用户永远是对的"。Karpathy 那句"Iron Man suit" 的隐喻很贴切:AI 是钢铁侠的盔甲,不是钢铁侠本人。
这条原则对每个想做 AI 工具的人都是必修课:别让 AI 越权。
3. 工程基本功:daemon、双端口、版本自动重启
掀开引擎盖,gstack 的工程不是花架子。
- Bun + 编译型二进制:避免
node_modules在用户机器上闹脾气,启动也比 Node 快一个量级 - 浏览器守护进程:第一次启动 3 秒,后续每个
$B <command>只要 100-200ms。AI 跟浏览器交互这种高频场景,没有 daemon 就是灾难 - 双 HTTP 监听端口:本地端口暴露完整能力,ngrok 隧道端口只暴露白名单(
/connect、/command、/sidebar-chat),靠物理端口隔离做安全,而不是靠 header 推断 - 版本号自动重启:编译时写入
git rev-parse HEAD,CLI 发现 binary 跟 server 版本不一致就自动 kill 再起。"陈旧二进制"这类坑直接断根
这些细节单拎出来都不新鲜,但凑在一起说明一件事:作者真的在用这个工具,并且踩过坑。AI 编程时代很多项目"看起来都对",跑起来全是漏,gstack 不是。
4. 跨 agent 适配:方法论高于宿主
gstack 不绑死 Claude Code,一份 ./setup --host <name> 能把 skill 安到 Codex、Cursor、OpenCode、Factory、Kiro 等十个 AI agent 的对应目录下。
~/.claude/skills/gstack-*/ # Claude Code
~/.codex/skills/gstack-*/ # OpenAI Codex CLI
~/.cursor/skills/gstack-*/ # Cursor
~/.config/opencode/skills/gstack-*/ # OpenCode
这件事看着是个安装脚本的小事,本质却是一个抽象层选择:作者把 sprint 方法论当成一等公民,把 AI agent 当成可替换的宿主。这跟当年 LSP(Language Server Protocol)把语言能力从编辑器里抽出来是一个套路。
赌的是什么?赌方法论比工具活得久。我赞同这个赌局。
5. 安全意识在线
AI agent + 浏览器是个高危组合,gstack 在这件事上没偷懒:
- CDP allowlist:原始 Chrome DevTools Protocol 调用走 deny-default 白名单,每个 method 加进白名单要附一句 justification
- Prompt injection 防御:22MB 本地 ML 分类器 + Haiku 全文检查 + system prompt 里的随机 canary token,两个分类器同意才阻断(防止单模型误杀)
- Scoped token:
/pair-agent给远端 agent 的 token 只能调白名单 command,不能访问/health这种敏感端点
这些设计在 ARCHITECTURE.md 里说得很清楚。普通 AI 工具项目能做到一半就不错了。
二、待提高的地方
1. 工具栏拥堵
AGENTS.md 里列了 50+ 个 slash command,README 里又列了一遍。光是 /plan- 开头的就有 plan-ceo-review、plan-eng-review、plan-design-review、plan-devex-review、plan-tune、autoplan六个。
对老用户是富矿,对新用户是迷宫。我装上跑第一次的时候,光是判断"我现在该用哪个 command" 就花了十几分钟。
更深层的问题是:当工具栏比业务还复杂时,开发者的认知负载是反向被推高的。AI 本应替你管这些选择,结果你先得替 AI 把选择题做完。
/autoplan(自动跑一组 review)是个聪明的折衷,但它的存在本身就承认了"散装命令太多"。
2. 文档膨胀
仓库里几个核心文档的体量:
| 文件 | 行数 |
|---|---|
CHANGELOG.md |
732 KB |
BROWSER.md |
60 KB |
CLAUDE.md |
49 KB |
ARCHITECTURE.md |
32 KB |
单个 office-hours/SKILL.md |
2092 行 |
文档很全,每一份单看都有理由。但一个 SKILL.md 写到 2000 行,已经超过了人能"读一遍记住"的体量。
这是 AI 项目的通病:因为生成成本低,文档容易膨胀。膨胀之后没人通读,新功能往里堆,旧功能没人删——慢慢就变成了考古现场。
我自己的经验:超过 500 行的 prompt 文件,AI 自己也会注意力涣散。
3. 默认开关偏激进
跑 setup 的时候,gstack 会问要不要给当前项目也装一份、要不要给 CLAUDE.md 加一段"必须用 gstack 的指引"。这些选择本身没错,但默认走向是"全部开启"。
对于已经"all-in" 的人很爽,对于"先试试"的人就是入侵感。第一次跑完,CLAUDE.md 多了一大段我并不完全理解的指令,CI 里多了一些我没确认的钩子。
我的偏好是"默认保守,进阶才打开"。让用户能小步试,再决定要不要 all in。
4. CHANGELOG 即历史诗
732KB 的 CHANGELOG 本身是个信号。版本号已经走到 1.43.3.0(四段式版本号也是一个观察点),说明迭代密度极高、破坏性变更不少。
迭代快是好事。但作为"想长期依赖它"的工程师,我会顾虑:今天跑通的 workflow,下周 upgrade 之后还在不在?
三、自己做类似项目时,能借鉴什么
这一段是这次拆机我最在意的部分。哪怕你完全不用 gstack,下面这些可以直接抄进你自己的项目。
1. 给你的 AI Agent 写一份 ETHOS
不是 prompt,是信条。三五条就够:
- 边际成本变低之后,要做完整的事
- 动手之前先搜,把知识分三层
- 用户拥有最终决定权
- ……(你团队的语境)
把它注入到每个 workflow 入口。这比你 prompt 里反复说"请仔细思考"管用得多。
2. 把方法论压成 slash command,但克制总数
把你团队最常做的 5-8 件事——比如"提一个 design proposal"、"做一次 code review"、"加一个 feature flag"——做成 skill。不要超过十个。十个以上就开始挤了。
3. 给每个流程一个明确的产出物
/office-hours 产出 design doc,/plan-eng-review 产出测试矩阵,/review 产出 review report。下一关读上一关的产出物,AI 的注意力就被串起来了。
这是把 Pipeline 思想搬到 AI 编程里的关键一步。
4. "第二意见"模式
让另一个 AI——最好是不同模型——用不同 prompt 审视同一份代码。gstack 的 /codex 是这个思路。一行 shell 脚本的事,但挡住的坑很真实。
5. 复盘自动化
/retro 自动按人、按项目、按周做复盘统计。手动写月度总结的人都知道,最难的不是写,是收集数据。把数据收集自动化,复盘的门槛就降到了"愿意花十分钟"。
6. 守护进程化高频操作
浏览器、数据库连接、LSP server——任何 AI 调用频次高于 1 次/分钟的依赖,都应该是 daemon。冷启动 3 秒 vs 热调用 100ms,对体验是数量级差异。
7. 把宿主当成可换的
哪怕你今天只用 Claude,也按"将来可能换"的姿势写 skill。这跟当年写代码不绑 DB 是一个道理。AI 模型/agent 的演化速度比数据库快得多。
四、收尾
二十多年写代码的体会是:工具不是答案,方法才是。
gstack 最大的价值不在那 30 多个 slash command,而在它把 AI 编程从对话框升级成了流水线这个思路。工具栏会拥堵,文档会膨胀,版本号会跳跃,但 sprint as skills 这个抽象会留下来。
如果你是想用好 AI 的工程师,建议你装一次跑一遍 /office-hours → /autoplan → /review → /qa → /ship,体验"流水线"的感觉,再回头按自己的项目做减法。
如果你是创业者,更值得抄的是 ETHOS:给你团队的 AI 写一份"我们是怎么思考的"——这比塞一堆 prompt 模板有用一万倍。
最后留一个问题:你团队现在用 AI 编程,是已经在跑流水线,还是还在跟对话框打字?
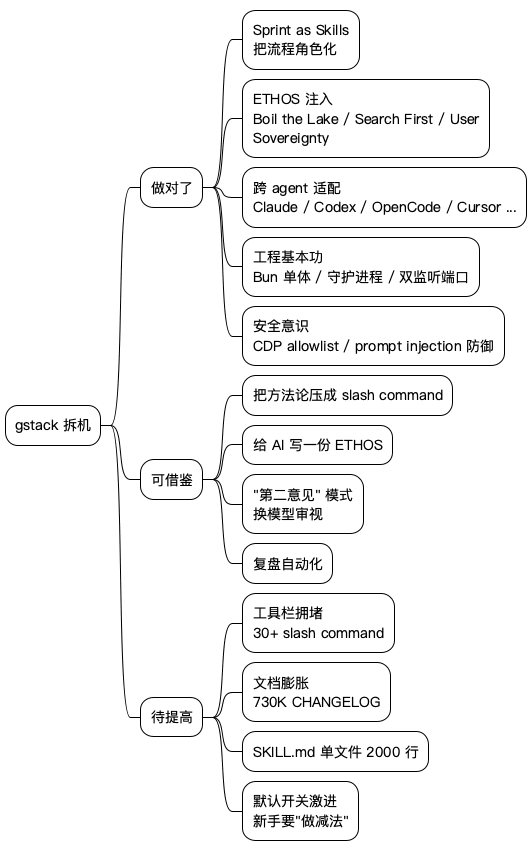
@startmindmap
* gstack 拆机
** 做对了
*** Sprint as Skills\n把流程角色化
*** ETHOS 注入\nBoil the Lake / Search First / User Sovereignty
*** 跨 agent 适配\nClaude / Codex / OpenCode / Cursor ...
*** 工程基本功\nBun 单体 / 守护进程 / 双监听端口
*** 安全意识\nCDP allowlist / prompt injection 防御
** 可借鉴
*** 把方法论压成 slash command
*** 给 AI 写一份 ETHOS
*** "第二意见" 模式\n换模型审视
*** 复盘自动化
** 待提高
*** 工具栏拥堵\n30+ slash command
*** 文档膨胀\n730K CHANGELOG
*** SKILL.md 单文件 2000 行
*** 默认开关激进\n新手要"做减法"
@endmindmap
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。