Harness Pipeline:给 AI 编程套一条带护栏的跑道
Posted on 四 21 5月 2026 in Tech
| Abstract | Harness Pipeline:给 AI 编程套一条带护栏的跑道 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v1.0 |
| Updated | 2026-05-21 |
| License | CC-BY-NC-ND 4.0 |
周五下午四点,AI 半小时帮我写完一个 feature,单元测试一片绿。
我盯着 diff 看了五分钟,没看出什么毛病。点了合并按钮的那一刻,心里却没底——不是怕它写错了,是怕它"对得太工整",工整到我没办法判断它有没有偷偷绕过某个边界条件。
这种心虚,过去十几年写代码很少有。以前 Code Review 看一段陌生代码,至少知道"作者大概是怎么想的",看几眼就能判断要不要追问。AI 写的代码不一样:它没有"想法",只有"模式"。模式对了,逻辑可能错;模式眼熟,安全可能塌。
所以我越来越确信一件事:AI 让"写代码"变快了,却让"交付代码"变难了。难的不是技术,是责任——谁为这段代码上线后的行为负责?
这篇文章想聊的,就是怎么用一条更严的流水线把这份责任接住。我把它叫做 Harness Pipeline——给 AI 编程套一条带护栏的跑道,骨架是 SDD → TDD → BDD → MDD,闸门是静态分析、AI Review、规则检查。
一、Build Pipeline 不够用了
传统 Build Pipeline 解决的是一个很朴素的问题:这段代码能不能跑、跑起来对不对。它的假设是:
- 代码由人写,每一行都有人能讲清楚为什么这么写
- 测试由人维护,覆盖的是人能想到的场景
- 出了问题,能追溯到具体的人和具体的提交
AI 编程把这三条假设全打乱了:
- 代码是 AI 生成的,"为什么这么写"的答案是"训练数据里这么写的"
- 测试也可能是 AI 顺手写的,覆盖的是"AI 觉得该测的"
- 出了问题,提交人是你,但你只 review 了一部分
Build Pipeline 还在管"构建是否成功",但现在的风险点早就变了。变成了:
- 意图是否对齐:AI 理解的需求和你理解的是不是同一件事?
- 行为是否对路:测试全绿,但用户走进来真的舒服吗?
- 上线后是否真有用:这个 feature 到底带来了什么?还是只是给监控大盘多加了一条曲线?
这三件事,Build Pipeline 一件都管不了。
二、Harness Pipeline 是什么
一句话:Harness Pipeline 是 AI 代码生成的约束跑道,前面用四层骨架定方向,中间用三道闸门挡 bug,后面用一个反馈环验假设。
骨架是 SDD → TDD → BDD → MDD,闸门穿插在中间,最后人来 sign-off。完整流程长这样:

这条跑道的核心思想只有一句:让 AI 在每一关被卡住,而不是事后让人兜底。
为什么?因为 AI 修代码比人快,但 AI 决定"这段代码值不值得上线"比人差远了。把判断留给人,把修复交给 AI,分工才对。
三、四层骨架:SDD → TDD → BDD → MDD
四层骨架解决的是四个不同时间点的问题。
| 层 | 在 AI 之前/之后 | 防什么 | 谁说了算 |
|---|---|---|---|
| SDD(Spec-Driven) | 之前 | 防意图跑偏 | 人写规格 |
| TDD(Test-Driven) | 之前 | 防契约被绕过 | 人/AI 共写用例 |
| BDD(Behavior-Driven) | 之中 | 防用户体验跑偏 | 人定场景 |
| MDD(Metrics-Driven) | 之后 | 防假设落空 | 数据说话 |
SDD:规格即合同(用 OpenSpec 装、用 DDD 写)
最早我也只是在项目里塞一个 spec.md。能用,但很快就出问题——规格散在各处,没人 review,改了也没人知道,更别说追溯"上一版我们承诺了什么"。
规格要变成 Harness Pipeline 的第一道闸门,至少要满足三件事:可工件化、可 diff、可归档。这正是 OpenSpec 这一类工具在做的事。Anthropic 的 SuperPower 系列工具走的是类似的路:把规格变成一等公民的工件,而不是 README 里的散文。
以 OpenSpec 为例,一个完整的 change 长这样:
openspec/
changes/
add-rate-limit/
proposal.md # 这次改什么、为什么
design.md # 关键设计决策
tasks.md # 拆解到可执行任务
specs/
api-gateway/
spec.md # 这个能力的最终规格
api-gateway-delta/
spec.md # 本次 change 引入的增量
specs/
api-gateway/spec.md # 当前已发布的规格基线
好处是立等可见的:
- AI 读
proposal.md知道意图,读spec.md知道边界,读tasks.md知道怎么拆步骤 - 人 review 的是 spec delta,跟看 git diff 一样直观
- change 落地后归档进
specs/基线,下一次改动有据可查
那 DDD 在哪里?DDD 不是工具,是教你"规格里到底该写什么"。
OpenSpec 给你一张表格,DDD 告诉你怎么把表格填对。具体到日常工作,DDD 至少在三个地方帮你避免"AI 把脏活揽在一起":
- 限界上下文(Bounded Context):先问"这事属于哪个上下文?API 网关?账单?身份?" 想清楚再下笔,AI 才不会把限流逻辑揉进业务 service
- 聚合(Aggregate):明确"这次改动的一致性边界在哪"。比如限流计数器是 API 网关上下文里的一个聚合,TTL 一过就重置,不需要持久化到核心业务库
- 领域事件(Domain Event):把"发生了什么"显式化。
RateLimitExceeded是个事件,不是一个 if 分支——这件事写进 spec,下游消费者(告警、计费、风控)就有了对接口子
我自己的习惯:写 OpenSpec 的 design.md 之前,先在纸上画三件事——上下文图、聚合边界、关键领域事件。画完再去填模板,AI 生成代码时也带着这份"领域感",而不是只对着 REST URL 拍脑袋。
一句话总结这一层:OpenSpec 提供流程载体,DDD 提供设计骨架,AI 在二者圈出的范围里写代码。
TDD:红 → 绿 → 重构
规格落到代码层,就是测试用例。Harness Pipeline 里 TDD 的位置很关键——它是第一道客观闸门。AI 写的代码必须先让红色变绿色,否则不允许往下走。
这里有个坑:让 AI 同时写代码和写测试,等于让它自己出卷自己批改。最好的做法是人先写出核心契约的测试(关键路径、边界、异常),AI 再去填实现;剩下的辅助测试可以交给 AI 补,但人要 review 测试是不是"真在测行为"。
BDD:用户视角的验收
单元测试全绿,不代表用户走进来不别扭。BDD 用 Given-When-Then 描述用户行为,挡的是"通过测试但不对路"的那一类问题。
举个例子:限流 feature 单测全绿,但 BDD 场景一跑——"用户在 1 分钟内请求 100 次,第 101 次应该看到友好提示而不是 500"——AI 实现里压根没考虑响应体长什么样。
MDD:上线后用指标验证假设
MDD 是这条流水线最容易被忽略的一环。
我们做一个 feature 的时候,背后都有假设:"加了限流,错误率会下降"、"换了算法,P99 延迟会从 200ms 降到 100ms"。Build Pipeline 不管这个,BDD 也不管。MDD 的任务是把假设变成指标,让上线后的数据回头验证它。
# 在关键路径埋指标,让假设可以被验证
from prometheus_client import Counter, Histogram
rate_limit_blocked = Counter(
"api_rate_limit_blocked_total",
"Requests blocked by rate limiter",
["endpoint", "client_tier"],
)
api_latency = Histogram(
"api_request_duration_seconds",
"API request latency",
["endpoint"],
)
指标不对,回灌到下一轮 SDD:要么是规格写错了,要么是实现没达到承诺。这个闭环一旦跑起来,AI 写的代码就不再是"交付即终点",而是"交付即开始"。
四、三道闸门:把 AI 挡在错误之前
骨架定方向,闸门防细节。三道闸门按成本从低到高排:
第一道:静态分析(成本最低、最确定)
Python 项目里我常用这套:
ruff管风格、imports、明显 bugmypy --strict管类型bandit管安全(hardcoded secret、不安全的 yaml.load 之类)
这些工具是确定性的,跑得快,CI 里挂一道就行。AI 写的代码连这关都过不了,根本没必要往后送。
第二道:AI Review(用 AI 防 AI)
让另一个 AI(最好是不同模型,或者至少用完全不同的 prompt)对着 diff 做 review。重点不是"挑语法错"——那是静态分析的事——而是问几个高层问题:
- 这段代码的意图和 spec 一致吗?
- 有没有看起来对、但其实绕过了某个边界的情况?
- 错误处理是不是只是"装样子"(catch 了但 swallow 了)?
- 有没有 log 泄露敏感信息?
换 prompt 的意义在于:第一遍 AI 容易"自卖自夸",换个视角它才会挑出毛病。
第三道:规则检查(项目级硬规则)
每个项目都有自己的硬规则——命名规范、目录约定、安全基线、日志合规。这些东西沉淀在 AGENTS.md、skill 文件、或者一个简单的 rules/ 目录里。规则检查就是把这些规则跑成自动化脚本,挡住 AI 不知道的本地知识。
比如我们项目里有一条:"任何打到 INFO 级别的 log,不允许包含用户的手机号、邮箱、token"。AI 不知道,但脚本知道。
五、Python 实战:给 API 加限流
走一遍端到端,看看 Harness Pipeline 怎么跑起来。需求很简单:给一个 FastAPI 接口加限流。
Step 1. SDD:先做 DDD 草图,再落到 OpenSpec change
动笔之前花十分钟在纸上画:
- 限界上下文:API 网关。不污染下游业务上下文。
- 聚合:
RateLimitWindow(key = client_id,TTL 60s,强一致只在单实例内)。 - 领域事件:
RateLimitExceeded(client_id, endpoint, at),将来要被告警和风控订阅。
落到 OpenSpec,新建一个 change add-rate-limit:
# openspec/changes/add-rate-limit/proposal.md
## Why
高峰期 /api/v1/search 被少量客户端打爆,影响其他用户体验。
## What Changes
- 引入 API 网关层的限流中间件(单机滑动窗口)
- 暴露 `RateLimitExceeded` 领域事件供下游订阅
- 限流被触发时不暴露算法细节
## Out of Scope
- 分布式限流(下一个 change)
- 配额管理 UI
## Impact
- Affected spec: api-gateway(新增 rate-limit 能力)
- Affected code: app/middleware/, app/events/
再写 spec delta:
# openspec/changes/add-rate-limit/specs/api-gateway-delta/spec.md
## ADDED Requirements
### Requirement: 单客户端限流
系统 SHALL 限制单个客户端在 60s 内对 /api/v1/search 的请求次数。
#### Scenario: 在限制内
- WHEN 客户端 60s 内请求 ≤ 60 次
- THEN 全部正常处理(200)
#### Scenario: 超出限制
- WHEN 客户端 60s 内请求超过 60 次
- THEN 返回 429
- AND 响应体为 {"error": "rate_limited", "retry_after": <秒>}
- AND 响应体 MUST NOT 包含算法、窗口大小等内部细节
- AND 触发 RateLimitExceeded 事件
### Requirement: 匿名客户端
未携带 X-Client-Id 的请求 SHALL 按匿名身份限流,限制为 10 req/min。
### Requirement: 健康检查豁免
/health 路径 SHALL NOT 计入任何限流计数。
这份 spec 拿给 AI,意图、边界、领域事件全在里面。AI 写出来的中间件就不再是"对 URL 加个计数器",而是"在 API 网关上下文里维护一个 RateLimitWindow 聚合,并在越界时发出领域事件"——后者才是能跟整个系统协作的代码。
Step 2. TDD:人写核心契约测试
# tests/test_rate_limit.py
import pytest
from fastapi.testclient import TestClient
from app.main import app
client = TestClient(app)
def test_within_limit_returns_200():
for _ in range(60):
r = client.get("/api/v1/search", headers={"X-Client-Id": "c1"})
assert r.status_code == 200
def test_over_limit_returns_429_with_retry_after():
headers = {"X-Client-Id": "c2"}
for _ in range(60):
client.get("/api/v1/search", headers=headers)
r = client.get("/api/v1/search", headers=headers)
assert r.status_code == 429
body = r.json()
assert body["error"] == "rate_limited"
assert body["retry_after"] > 0
# 安全:不暴露算法细节
assert "window" not in body and "algorithm" not in body
def test_health_check_not_counted():
for _ in range(100):
r = client.get("/health")
assert r.status_code == 200
把这三个测试丢给 AI,告诉它"让它们绿"。AI 会去写中间件、写滑动窗口。
Step 3. 三道闸门
# 静态分析
ruff check app/ tests/
mypy --strict app/
bandit -r app/
# AI Review(伪命令,实际可以是脚本调你的 AI agent)
ai-review --diff HEAD~1 --prompt review-rate-limit.md
# 规则检查
python scripts/check_log_privacy.py app/
我自己踩过一个坑:AI 第一版实现把 client_id 直接打到了 INFO 日志里。单测全过,AI Review 也没挑出来。规则检查脚本一跑,立刻报错——这就是项目级硬规则的价值。
Step 4. BDD:用户视角
# features/rate_limit.feature
Feature: API 限流给用户友好的提示
Scenario: 超过限制时返回友好响应
Given 客户端 "c3" 已经请求 60 次
When 客户端 "c3" 再次请求 "/api/v1/search"
Then 响应状态码是 429
And 响应包含 "retry_after" 字段
And 响应不包含 "algorithm" 字段
Step 5. MDD:上线后看指标
# app/middleware/rate_limit.py(节选)
from prometheus_client import Counter
blocked_total = Counter(
"api_rate_limit_blocked_total",
"Requests blocked",
["endpoint", "client_tier"],
)
async def rate_limit_middleware(request, call_next):
if is_over_limit(request):
blocked_total.labels(
endpoint=request.url.path,
client_tier=classify(request),
).inc()
return JSONResponse(
status_code=429,
content={"error": "rate_limited", "retry_after": 60},
)
return await call_next(request)
上线一周后回头看:被挡的请求集中在哪几个 client?挡得对不对?有没有误伤正常用户?这些数据回灌到下一轮 SDD——可能要给某个白名单 client 单独配额,可能要把窗口从 60s 调到 30s。
整条流水线跑下来,AI 干了 80% 的体力活,人只在四个地方做了判断:写 spec、定核心契约测试、定 BDD 场景、看指标做决策。判断密度高,但判断量不大——这才是 AI 编程时代健康的人机分工。
六、Tomorrow Action:明天就能开始的事
不必一次到位,从最低成本的一两条开始:
- 试一次 OpenSpec(或类似工具),用它管下一个 change。哪怕只走通 proposal + spec delta 两份文件,也比散落的
spec.md强一档。 - 写 spec 之前先画 DDD 三件套:限界上下文、聚合、领域事件。十分钟一张草图,AI 出来的代码层次会立刻不一样。
- 核心路径的测试自己写,别全交给 AI。一个项目挑 3-5 个最关键的契约就够。
- CI 里挂上
ruff + mypy + bandit。这是性价比最高的一道闸门。 - 写一个
check_log_privacy.py之类的项目级规则脚本。规则就一两条,挡的是 AI 永远不知道的本地知识。 - 给关键 feature 加一个 Prometheus 指标,上线后看一周。养成"feature 不是上线即结束"的习惯。
- AI Review 用不同 prompt 跑第二遍。一行 shell 脚本的事,但挡住的坑很真实。
- 保留一个"人类 sign-off"清单:涉及钱、安全、用户数据、对外承诺的地方,AI 不能拍板。
七、收尾
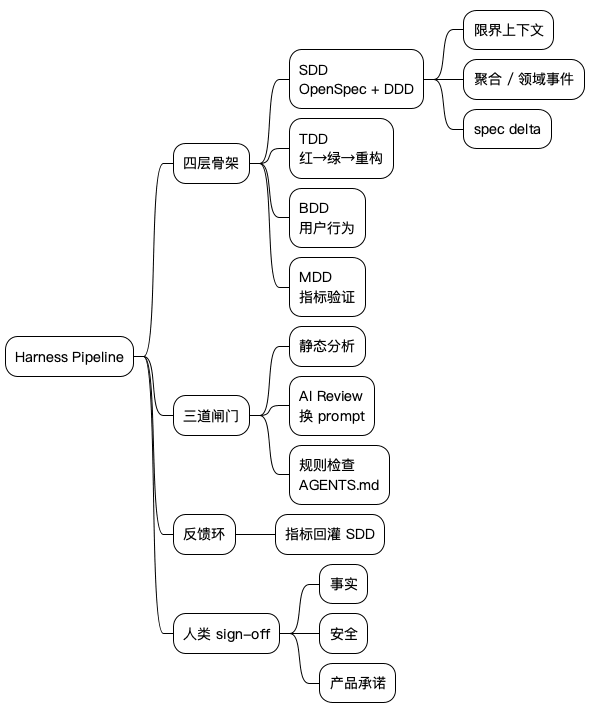
很多人讨论 AI 编程,关注点都在"AI 能写多少代码"。我觉得错了。真正决定生产力的,不是 AI 能写多少,而是你敢让 AI 写的代码占多少。
敢不敢,看的就是你的护栏够不够硬。Harness Pipeline 不是要把 AI 关起来,而是给它一条能跑快、又不会冲出赛道的跑道。
一句话收尾:AI 越能干,护栏越要严。 这不是给 AI 设限,是给"敢上线"留余地。
留一个问题给你:你团队现在 AI 写的代码,卡在哪一关?是没人写 spec,还是没人看指标?
@startmindmap
* Harness Pipeline
** 四层骨架
*** SDD\n规格即合同
*** TDD\n红→绿→重构
*** BDD\n用户行为视角
*** MDD\n指标验证假设
** 三道闸门
*** 静态分析\nruff/mypy/bandit
*** AI Review\n换个 prompt 审视
*** 规则检查\nAGENTS.md + 安全基线
** 一个反馈环
*** 指标回灌\n下一轮 SDD
** 人类 sign-off
*** 事实
*** 安全
*** 产品承诺
@endmindmap
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。