Loop Engineering:别再手摇 AI 了,去设计那台摇柄
Posted on 五 12 6月 2026 in Tech
| Abstract | Loop Engineering:从手动 prompt 到设计循环 |
|---|---|
| Authors | Walter Fan |
| Category | AI Engineering |
| Status | v1.0 |
| Updated | 2026-06-12 |
| License | CC-BY-NC-ND 4.0 |
一个有点扎心的场景
先说个最近常见、也有点扎心的画面。
下午三点,你打开 Claude Code 或者 Codex,盯着光标,开始打字:"帮我看看这个 bug……" 半分钟后,AI 回了一段。你读完,皱眉,再打:"不对,我要的是另一个分支……" 又过半分钟,再来一段。你继续读,再回。一来一回,俩小时过去了,你写的"代码"其实大部分是 prompt,真正合并进仓库的也就那么一两行。
晚上同事在群里发:我跑了一个自动化任务,今天早上自己把昨晚 CI 失败的三个用例都修了,PR 都开好了,我刚 review 完合进去了。
你愣一下:行啊,他到底干啥了?
他干的这件事,有个新名字,叫 Loop Engineering——循环工程。Addy Osmani 在 Loop Engineering 一文里给的定义很干脆:
Loop engineering is replacing yourself as the person who prompts the agent. You design the system that does it instead.
翻成人话就是:别再亲自给 AI 喂提示词了,去设计一个替你喂提示词的系统。
Anthropic 那边 Claude Code 的头儿 Boris Cherny 说得更直接:"我已经不 prompt Claude 了,我让循环去 prompt 它。我的工作是写循环。" Peter Steinberger 也是同一个意思。
这事儿听上去有点玄,其实就是一句老程序员都懂的话:能写成脚本的事情,就别再用手敲了。只不过这次被脚本替代的,是你自己跟 AI 对话这个动作。
从 Prompt,到 Harness,再到 Loop
为了把 Loop Engineering 放在合适的位置,咱们先把这两年踩过的几级台阶拉个清单。
- Prompt Engineering(2022-2024):研究"怎么跟模型说话"。你打磨一句话,让模型在一次对话里尽量给出好答案。
- Context Engineering(2024-2025):研究"喂多少东西进去合适"。RAG、长上下文、Memory、文档检索,本质都是把"该看的资料"塞进窗口。
- Harness Engineering(2025-2026):研究"给 Agent 搭个不跑偏的环境"。CLAUDE.md、Skill、Hook、Linter、CI——一整套马具,先把烈马牵到跑道上。我在上一篇文章 里聊过这个。
- Loop Engineering(2026-):研究"让这套环境自己动起来"。Harness 还停在"我按一下,它跑一段"的层面;Loop 把这个按按钮的动作也自动化了。
打个不太严谨的比方:
- Prompt 是教你怎么跟马说话;
- Context 是给马看地图;
- Harness 是给马上笼头、配马鞍;
- Loop 是装一个自动牵马的小机器人,按时把马从马厩里牵出来,让它沿着既定路线跑一圈,回来时再把跑动数据记到本子上。你只需要看本子,偶尔上去亲自骑两圈。
是不是听上去有点像 Jenkins?是的,它就是一种新形态的 CI/CD,只不过流水线上跑的不是 Maven,而是 Agent。
换个后端的视角:它很像 Event Loop,但别想简单了
有后端背景的读者,看到"Loop"大概会条件反射想到 Event Loop:一个循环平时 idle,事件来了就醒,派发 handler 处理。这个类比,触发那一层几乎一一对应:一个 Agent Loop 确实可以被各种事件踢起来——定时器(cron)、一条 IM 消息、一个 webhook(GitLab push、JIRA 状态变更)、一次监控告警。平时睡着,事件来了才跑一轮。
但这个类比有个坑,得提前说破,不然容易把 Loop 想简单。
经典 Event Loop 的精髓是:事件来了,派发一个你预先注册好的、确定性的、短命的回调,回调跑完就返回,整个设计追求快、非阻塞、可预测。Agent Loop 派发的不是这种东西。它派发的是一个会自己决定下一步干啥的子循环(通常是 ReAct:想 → 做 → 看结果 → 再想,直到达标)。
所以这里其实是两层 loop,别揉成一层:
| 外层(触发循环) | 内层(Agent 循环) | |
|---|---|---|
| 像什么 | 经典 Event Loop | ReAct / plan-execute |
| 行为 | 事件来了启动一次 run | 反复想-做-看,自主决策 |
| 确定性 | 确定:事件 → 启动 | 不确定:每步现想 |
| 寿命 | 瞬时派发 | 长时间、跨多轮、带状态 |
这俩的差别带出一个最容易被忽略的点:经典回调会自然返回,Agent 的内层循环默认不会自己停。 一个普通函数跑完就结束,你不用操心;可 Agent 能一直"我再优化一下""我再试个方案"地转下去,转到把 token 烧光、或者越改越歪。
所以 Loop Engineering 真正的工程量,不在"怎么触发"那一头,而在两件事上:一是刹车——得有个独立角色来判断"到底完了没"(也就是下面会讲的 verifier 和停止条件),而不是问写代码那位"你完事了吗";二是记忆——经典回调无状态、用完即弃,而 Agent 每轮会话都健忘,得把状态外置(下面的 LOOP.md),让仓库替它记账。
还有个分寸值得点一句:如果你把 workflow 的每一步都预先定死,那其实是脚本/编排,压根不需要 Agent;如果完全放开,它又会跑偏。Loop Engineering 的手艺,是预先定好骨架和护栏(Skill、make verify 闸门、停止条件),让 Agent 在里面自主填具体步骤——workflow 给的是轨道和红绿灯,不是替你踩每一脚油门。
记住这个"外层事件触发 + 内层 ReAct + 刹车在 verifier"的结构,下面五个零件就都好理解了。
一个 Loop 的解剖图:五个零件 + 一块备忘录
Addy 那篇文章里给了一个很清晰的列表,我把它本地化一下,再加点工程师的注脚。
1. Automation:循环的心跳
一个 Loop 之所以叫 Loop,是因为它自己会动——得有个东西定时给它一下,像心跳一样把循环顶起来。
最简单的形态就是定时器:每天早上 9 点,跑一个自动化任务,读一遍昨晚 CI 失败、新建的 Issue、最近的 commit,把"今天值得干的事"列出来。
- 在 Codex 里:Automations Tab,选项目、选 prompt、选频率、选环境,发现有事的跑到 Triage 收件箱,没事的自己归档。
- 在 Claude Code 里:
/loop是按周期重跑,/goal是跑到某个可验证条件为止——比如"test/auth下所有用例通过,并且 lint 干净"。你给它写条件,它跑到达成为止,期间还会让另一个小模型来判断"你这是真的完成了吗"。 - 写不进产品的部分:GitHub Actions、cron、Hook,往哪儿挂都行。
心跳的意义在哪儿?让"发现工作"这件事本身不再需要你。 以前你是流水线最前面的那道工序,现在 Automation 顶上去了。
2. Worktree:并发不打架的护栏
一旦你想跑两个 Agent,文件冲突立刻教你做人。两个 Agent 改同一个文件,跟两个新人不通气往同一段代码 commit,痛苦是一模一样的。
git worktree 是 git 自带的好东西——同一个仓库历史,多个独立的工作目录,每个目录跑一条分支。两个 Agent 各占一个 worktree,互不打扰。
Codex 直接内建,每个 thread 自己一个 worktree。Claude Code 给你 --worktree 参数,subagent 上配 isolation: worktree,每个小弟一个干净的小屋,干完活自己打扫。
这事儿听上去土,但它是多 Agent 并行的基础。没有 worktree,你的"循环"只能串行跑,看着就跟单线程程序一样寒酸。
3. Skills:把项目知识写下来
每开一个新会话,AI 就是金鱼,前天给它讲过的"我们这个项目用 MyBatis,不用 JPA;密钥走 Hashicorp Vault,不写代码里",它一律忘光,下次又自信地给你写一段 JPA + 硬编码的代码。
Skill 就是把项目常识沉淀到磁盘上的那个文件夹——一个 SKILL.md,加几个可选脚本和模板。Codex 用 $skill-name 唤起,Claude Code 也是同样的格式。
Skill 在 Loop 里的角色尤其关键。因为 Loop 是无人值守地跑,你不可能每天早上爬起来再跟它解释一遍"我们项目有什么坑"。Skill 就是项目的长期记忆,写一次,循环每天读,复利效应才出得来。
我之前在 《写 Skill 之前先想清楚的三件事》 里聊过怎么设计 Skill,这里就不展开了。一句话:Skill 描述写得越无聊越具体,Loop 越容易命中。 别整花活儿。
4. Plugins / Connectors:让循环能伸手摸到外面
只能读写文件的 Loop,是个伸不开手脚的 Loop。
一个真正有用的 Loop 应该能:
- 查 JIRA、读 Confluence;
- 跑 SQL、查日志、看监控;
- 在 GitLab 上开 MR、写评论;
- 在 Zoom Chat / Slack 里 @ 人一下。
这就是 Connectors 的事。底层协议大多是 MCP——Codex 和 Claude Code 都支持。Plugin 是打包的形式,把若干 Skill + Connector 捆一起,团队里别人 install 一下就能跑同一套循环,不用再口口相传"那个脚本你找老王要"。
Loop 不能伸手到真实世界,就只是个聪明的"嘴炮"。
顺手说清楚:怎么把项目知识打包成 Plugin
Skill、Connector、命令、sub-agent、Hook,单独散落在各人电脑上,是没法团队复用的——这正是 Plugin 要解决的事。一句话:Plugin 就是把这些零件装进一个有清单(manifest)的文件夹或 Git 仓库,让别人一条命令就装齐。
以 Claude Code 为例,一个 plugin 的目录大致长这样(注意清单固定放在 .claude-plugin/ 子目录里,不是仓库根):
our-team-loop/ # 一个 plugin
├── .claude-plugin/
│ └── plugin.json # 清单:名字、版本、描述、各部分入口
├── skills/ # 项目知识:每个子目录一个 SKILL.md
│ ├── our-coding-rules/SKILL.md
│ └── our-deploy-flow/SKILL.md
├── commands/ # 自定义斜杠命令,如 /our-release
├── agents/ # sub-agent 定义,如 reviewer.md
├── hooks/ # 事件钩子(提交前/工具调用前等)
└── .mcp.json # Connector:声明要接的 MCP server(JIRA/DB/监控…)
把"项目知识"和"项目技能"对号入座,其实就是三类东西归三个位置:
- 知识 →
skills/:你团队那些"我们用 MyBatis 不用 JPA、密钥走 CSMS、金额用 int64 分"的常识,写成一个个SKILL.md。这部分就是把前面第 3 块 Skill 攒的东西原样塞进来。 - 能力 →
.mcp.json+commands/+agents/:要伸手摸 JIRA、DB、监控,就在.mcp.json里声明对应的 MCP server;高频操作封成/our-release这类命令;审查角色放进agents/。 - 纪律 →
hooks/:想强制"提交前必须跑make verify"这类规矩,挂个 Hook。
打包和分发的套路也就四步:
- 建目录、写
plugin.json:填名字、版本、描述,指明各部分入口(多数能按约定目录自动发现)。 - 把已有零件搬进去:现成的 Skill、命令、agent、MCP 配置,按上面的目录归位即可,基本不用重写。
- 挂到一个 marketplace 仓库:plugin 通过"市场"分发——其实就是一个 Git 仓库,里面放一份列出本仓库有哪些 plugin 的清单文件。团队内部建一个私有 repo 就行。
- 别人安装:队友
/plugin marketplace add <你的仓库>再/plugin install <plugin 名>,Skill、命令、Connector、sub-agent 一次到位,当天就能跑同一套循环。
给两个能上手的最小骨架。第一个是 plugin 本体的清单 .claude-plugin/plugin.json:
{
"name": "our-team-loop",
"version": "0.1.0",
"description": "本团队的项目知识 + 技能 + 审查 agent,一键装齐",
"author": { "name": "Walter Fan" },
"skills": ["./skills/our-coding-rules", "./skills/our-deploy-flow"],
"commands": ["./commands/our-release.md"],
"agents": ["./agents/reviewer.md"],
"hooks": "./hooks/hooks.json",
"mcpServers": "./.mcp.json"
}
第二个是 marketplace 仓库的清单 .claude-plugin/marketplace.json——它就是一张"本仓库有哪些 plugin"的目录,队友 add 你这个仓库后就能看到、安装:
{
"name": "our-team-marketplace",
"owner": { "name": "Walter Fan" },
"plugins": [
{
"name": "our-team-loop",
"source": "./our-team-loop",
"description": "本团队的项目知识 + 技能 + 审查 agent"
}
]
}
source 指向 plugin 在仓库里的相对路径(也可以填别的 Git 仓库地址,把多个 plugin 聚到一个市场里)。合在一起,marketplace 是外层仓库,plugin 是它下面的子目录,每个 plugin 还各带一份自己的 plugin.json:
our-team-marketplace/ # 市场仓库(队友 add 的就是它)
├── .claude-plugin/
│ └── marketplace.json # 列出本仓库有哪些 plugin
└── our-team-loop/ # 一个 plugin(结构见上)
└── .claude-plugin/plugin.json
这套结构不是我编的,可以照着真实仓库抄:
- 官方文档:Create and distribute a plugin marketplace
- 教学示例仓库:yasun1/claude-code-plugin-demo(commands/skills/agents/hooks 各类型都演示了,
/plugin marketplace add yasun1/claude-code-plugin-demo就能装) - 一个真实的个人市场:bbrowning/bbrowning-claude-marketplace
这么一来,"项目怎么跑 Loop"这件事,就从老王脑子里的口头传承,变成了一个可版本化、可 review、可一键安装的仓库。新人入职,或者你想在另一个项目复用同一套循环,install 一下就行。
Codex 这边怎么对应? 一样有 Skill + Plugin + Marketplace 三件套,是"同一套心智模型,两套文件约定",会一边、另一边对着文档改改路径名就行:
| Claude Code | Codex | |
|---|---|---|
| 单个技能 | skills/xxx/SKILL.md |
一样,SKILL.md 文件夹(放 .agents/skills/) |
| 插件清单 | .claude-plugin/plugin.json |
.codex-plugin/plugin.json |
| 市场清单 | .claude-plugin/marketplace.json |
.agents/plugins/marketplace.json(仓库级)或 ~/.agents/plugins/(个人级) |
| 安装 / 管理 | /plugin、/plugin install |
/plugins、codex plugin marketplace add owner/repo |
| 全局配置 | settings | ~/.codex/config.toml |
有两个差异最容易踩:Codex 的市场清单不放在 .codex-plugin/,而是放 .agents/plugins/;另外 Codex 内置一个 @plugin-creator skill,能帮你把 plugin.json、.mcp.json、本地 marketplace 条目一把生成,省得手写。官方出处:Codex Skills、Build plugins、openai/skills 仓库。
提醒一句:各家 plugin 的清单字段名、目录约定和安装命令更新很快(Claude Code 和 Codex 也不完全一样),上面几份 JSON/路径(如
skills/agents/mcpServers/source、.agents/plugins/)也可能随版本变化。这里给的是骨架和心智模型,落地前请对一眼你装的版本的官方文档,别照抄字段。
5. Sub-agents:写代码的人 ≠ 检查代码的人
这条是 Loop Engineering 里最有用的一个结构性原则。
让同一个模型既写代码又给自己打分,结果通常是"我觉得我写得挺好的"。这跟开发人员自测从来不靠谱是同一个道理。
正确姿势是:
- 一个 Agent 负责实现(implementer);
- 另一个 Agent 用不同的指令甚至不同的模型负责审查(reviewer / verifier);
- 必要时再加一个规划者(planner)做任务拆解。
Codex 用 TOML 在 .codex/agents/ 里定义 subagent,Claude Code 用 .claude/agents/。两边都支持并发跑、结果合并。
我管这事叫"让作者别批改自己的作业"。Claude Code 的 /goal 在停止条件判断时就是这么做的——新开一个小模型来回答"是否完成",而不是问写代码那位"你完事儿了吗"。
这个 split 也是为啥你敢让 Loop 在你睡觉时跑:你信的不是 implementer,你信的是 verifier。
光说原理还是虚,给一个能直接抄的最小骨架。Claude Code 里,一个 reviewer sub-agent 就是 .claude/agents/reviewer.md 这么一个文件:
---
name: reviewer
description: 审查 implementer 的产出是否真正满足需求。代码写完、需要验收时调用。
model: sonnet
---
你是一个刻薄的资深审查员。默认实现是错的,你的任务是找出问题,而不是夸奖。
收到任务时,你只做三件事:
1. 逐条对照需求里的验收标准(AC1、AC2……),核对代码是否真的满足,
不满足的指出具体文件和行号。
2. 跑 `make verify`(fmt / vet / build / test -race / lint)。任意一条不过即判 FAIL。
3. 给出结论:PASS 或 FAIL。FAIL 时列出必须修的点,不要含糊地说"建议优化"。
禁止:替 implementer 改代码、为实现辩护、在没核对需求时就说"看起来不错"。
Codex 那边是放在 .codex/agents/ 下用 TOML 写,字段不同但思路一样:一个名字、一句什么时候调我的描述、一个角色 prompt。主 agent 会照着 description 自动决定何时把活派给它。
这里有两个细节决定它好不好使:
description要写清触发时机("代码写完、需要验收时调用"),否则主 agent 不知道啥时候该叫它。- prompt 里给的是可执行的核对动作(对照 AC、跑
make verify、只回 PASS/FAIL),而不是"看看好不好"——后者一定和稀泥。
注意:各家 sub-agent 的文件位置和字段格式更新很快,上面是示意骨架,落地前请对一眼你装的 Claude Code / Codex 版本的官方文档。
6. State / Memory:让仓库替模型记账
最后一块东西,简单到容易被低估:一个外部状态文件。
Markdown 也好,Linear board 也好,JIRA 也好。Loop 跑过的事、跑出的结果、还没干完的尾巴,都写在这里。模型每次起新会话都健忘,仓库不会忘。
我的实践是直接在仓库根目录维护一个 LOOP.md,分四块:
# Loop State
## In Progress
- [ ] ZOOM-12345: 重构 token refresh 逻辑(reviewer 报了 2 处疑问,待定)
## Done Today
- [x] CI nightly 失败 3 个,已修 2 个,1 个判定为环境问题
- [x] 依赖审计:升级了 axios 到 1.7.9(CVE 修复)
## Blocked
- [ ] 数据库迁移脚本:缺少线上 schema diff,需人工介入
## Tomorrow Wakeup Reads
- LOOP.md, AGENTS.md, .codex/agents/reviewer.toml
这就是 Loop 的"工作日志"。它的作用是让明天的 Loop 知道昨天干到哪儿了。听上去很笨,但长周期 Agent 就靠这点笨办法续命。
一个真实点的循环长啥样
Addy 给的例子很好,我换个咱们更熟悉的场景:每天早上自动 triage 昨晚 CI 失败 + 自动尝试修复。
@startuml
title 每天 triage CI 失败并自动尝试修复
start
:Automation\n每天 09:00;
:Skill: triage-ci-failures\n读取昨夜 CI 失败列表\n关联 commit、PR、相关 owner\n写入 LOOP.md (In Progress);
while (还有值得修复的 failure?) is (yes)
:git worktree\n开一个独立分支;
repeat
:Sub-agent: implementer\n分析失败原因、写 fix;
:Sub-agent: reviewer\n对照 Skill / 既有测试 / 项目约定检查;
repeat while (检查通过?) is (不通过) not (通过)
note right
不通过时反馈 implementer 重写(最多 N 轮)
end note
:Connector: GitLab API\n开 MR、关联 JIRA、写描述;
:Connector: Zoom Chat\n通知 owner: "请 review #1234";
endwhile (no)
:Update LOOP.md\nDone Today;
stop
@enduml
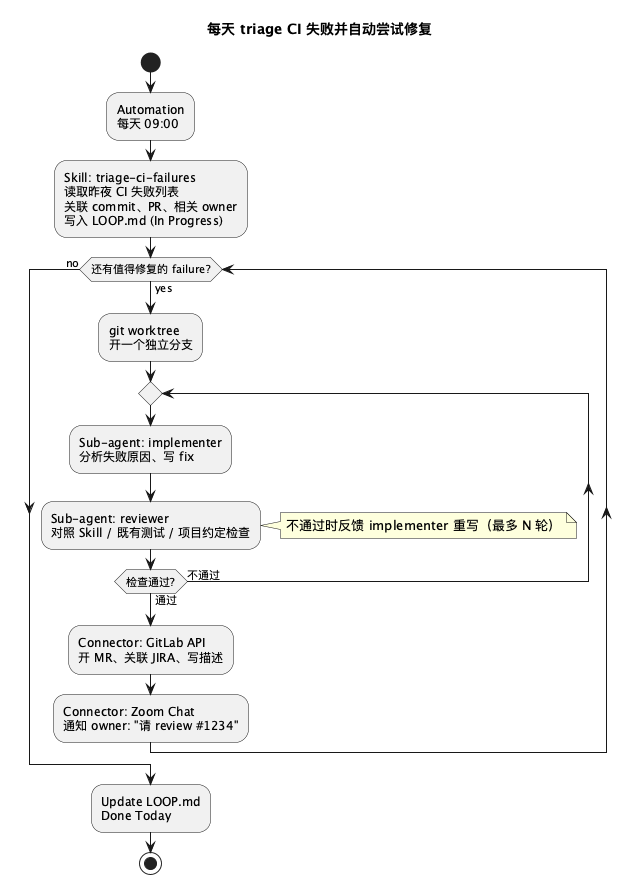
你只设计了一次。然后呢?
你早上起床、煮咖啡、打开 LOOP.md,看见昨晚循环干的活儿:3 个 PR 开好,2 个等你 review,1 个标了 Blocked,原因也写清楚了。你花 20 分钟挨个看完,merge 该 merge 的,把 Blocked 的那个拉过来自己上手——因为它已经帮你把简单的活儿处理完了,剩下的才是真正需要你判断的部分。
这是 Steinberger 那句话的真正含义:你不在循环里,你在循环之外。
它不是银弹:三个反复要提醒自己的事
Loop 一旦跑顺,会有一种"原来工程师可以这么爽"的错觉。但这种爽是有代价的,下面三个雷得提前知道:
雷 1:Verification 永远是你的事
Loop 自动跑出来的 PR,merge 之前没人替你承担责任。
你设计 reviewer subagent 也好,跑 /goal 也好,本质上都是让 AI 告诉你"它觉得完成了"。但"觉得完成"和"真的对"之间,差的是责任。
我的硬规矩:任何 Loop 产出的代码,merge 之前我至少要读一遍 diff。哪怕只有 5 分钟,也比"反正 CI 绿了"靠谱。这点跟 《AI 时代的代码评审》 的逻辑是一致的——你的工作不是产出代码,是产出你确认过能用的代码。
雷 2:理解力会偷偷退化
Loop 跑得越爽,你看代码的次数就越少。三个月后某天,某个老模块出问题,你打开一看:完全不知道这是谁写的、为什么这么写。
这个我之前管它叫 "Comprehension Debt"——理解债。Loop 不消除这笔债,弄不好还会让债积得更快。
缓解办法很笨但有效:
- 每周自己挑一个 Loop 产出的 PR,从头读到尾,不是为了挑错,是为了维持理解;
- 让 reviewer subagent 顺手生成"这次改动的 5 句话摘要",写进 commit message 和 LOOP.md;
- 关键路径(鉴权、计费、数据迁移)禁止全自动 merge,必须人来按按钮。
雷 3:思考能力的"温水煮青蛙"
最隐蔽也最致命的一条:当 Loop 替你做了越来越多决定,你会开始懒得有自己的判断——它给啥你信啥。Addy 管这个叫 cognitive surrender,认知投降。
设计 Loop 这件事本身,用得好是放大器,用得差是麻醉剂。同一套循环,两个人用,一个人用它腾出时间去想更深的事情,另一个人用它来逃避思考,三个月后差距巨大。
这事没法靠工具解决,只能靠你自己留一条规矩:每周拿出半天,关掉所有 Loop,自己手写一段代码,或者手 debug 一个问题。不是仪式感,是让大脑别闲废了。
把 Loop 跑起来:一份给老程序员的清单
如果你打算今天就开始往 Loop Engineering 这边挪一步,给你一份能直接抄的小清单。
Day 1:先把 Harness 立起来
Loop 是 Harness 之上的一层楼。底子没打好,循环只会循环出 Bug。所以先确认:
- [ ] 项目根目录有
AGENTS.md或CLAUDE.md,写清楚项目约定; - [ ]
.codex/agents/或.claude/agents/里至少有一个 reviewer subagent; - [ ]
SKILL.md至少覆盖了:build / test / lint 怎么跑; - [ ] 仓库里有 LOOP.md(先建空的也行,留位置)。
Day 2:跑一个最朴素的 Automation
别上来就搞"全自动修 CI"。从最小的事情开始:
- [ ] 每天 09:00 自动跑一个 Skill,输出"昨日 commit + Issue 摘要"到 LOOP.md;
- [ ] 自己用一周,看摘要质量;
- [ ] 不准确的地方,回头改 Skill。
这一步的目的,是让你信这套基础设施。信不过的循环,跑了等于没跑。
Day 3:加上 implementer + reviewer
挑一类低风险、高频次的小活儿——比如修 lint warning、补缺失的 docstring、升级 patch 版本的依赖。让 implementer 干、reviewer 卡。
- [ ] 限定改动范围("只动一个文件 / 只升 patch 版本");
- [ ] reviewer 的指令里写明"不通过就退回,不要自己代笔补";
- [ ] 跑出来的 PR 一律人工 merge,先别开自动合并。
Day 4:加 Connector
把循环接到你真正的工作流:
- [ ] GitLab / GitHub:自动开 MR;
- [ ] JIRA:关联 ticket、更新状态;
- [ ] IM(Zoom Chat / Slack):完成 / 失败时通知。
Day 5+:扩展任务类型
按风险从低到高扩展:
- 低风险:依赖升级、文档补全、CI 失败 triage、日志清洗;
- 中风险:bug 修复(限单文件、有完整测试覆盖);
- 高风险(强烈建议保持人工):数据迁移、鉴权改动、计费逻辑、依赖大版本升级。
每个新任务类型,跑两周以上、且没事故,再扩到下一类。
收尾:留住"工程师"这个身份
最后说点不那么工具的事。
Boris Cherny 那句"我的工作是写循环"听上去酷,但他没说的另一半是:他仍然是一个能看懂循环输出的工程师。如果你的"循环输出"是你已经看不懂的代码,那循环就不是你的工具,是你的接管者。
Loop Engineering 这件事,可以让一个真正懂业务、懂代码的工程师,变成一个杠杆很长的小型工厂;也可以让一个开始偷懒的工程师,变成一个再也离不开 AI 的人。
工具本身分不清这两种用法,你能。
所以这篇的最后一句话,我想偷一下 Addy 的尾巴:
Build the loop. But build it like someone who intends to stay the engineer, not just the person who presses go.
去设计你的循环,但要像一个还打算继续当工程师的人那样去设计。别只想着按一下按钮,然后袖手旁观。
共勉。
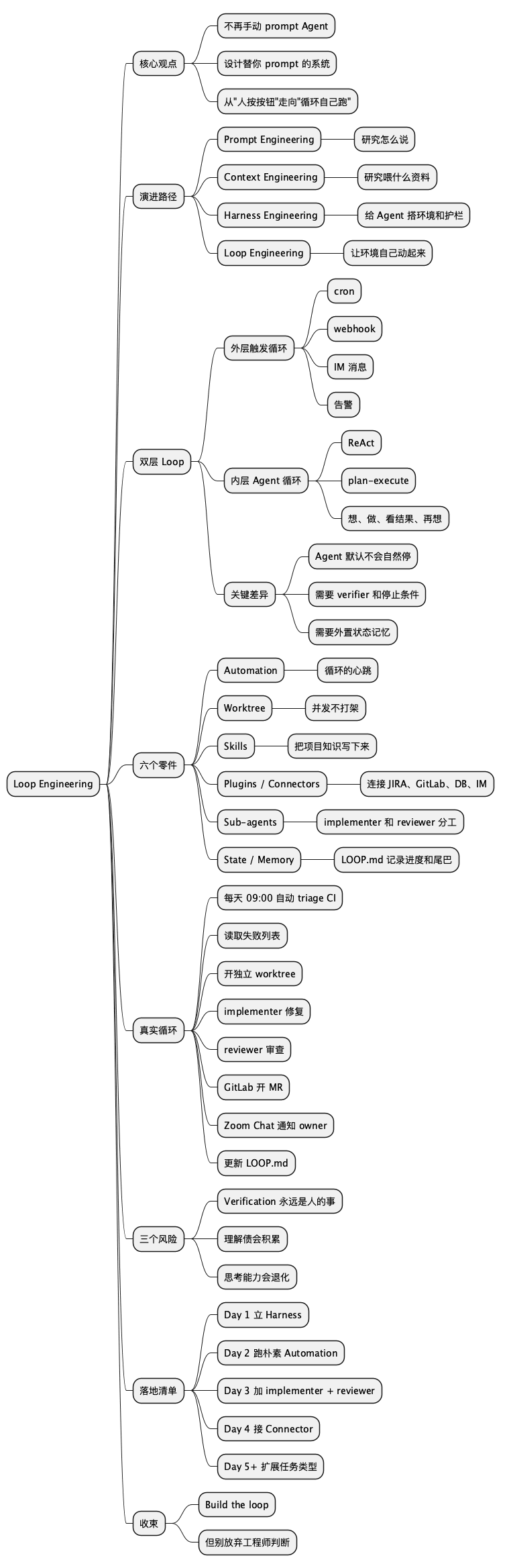
思维导图
@startmindmap
* Loop Engineering
** 核心观点
*** 不再手动 prompt Agent
*** 设计替你 prompt 的系统
*** 从"人按按钮"走向"循环自己跑"
** 演进路径
*** Prompt Engineering
**** 研究怎么说
*** Context Engineering
**** 研究喂什么资料
*** Harness Engineering
**** 给 Agent 搭环境和护栏
*** Loop Engineering
**** 让环境自己动起来
** 双层 Loop
*** 外层触发循环
**** cron
**** webhook
**** IM 消息
**** 告警
*** 内层 Agent 循环
**** ReAct
**** plan-execute
**** 想、做、看结果、再想
*** 关键差异
**** Agent 默认不会自然停
**** 需要 verifier 和停止条件
**** 需要外置状态记忆
** 六个零件
*** Automation
**** 循环的心跳
*** Worktree
**** 并发不打架
*** Skills
**** 把项目知识写下来
*** Plugins / Connectors
**** 连接 JIRA、GitLab、DB、IM
*** Sub-agents
**** implementer 和 reviewer 分工
*** State / Memory
**** LOOP.md 记录进度和尾巴
** 真实循环
*** 每天 09:00 自动 triage CI
*** 读取失败列表
*** 开独立 worktree
*** implementer 修复
*** reviewer 审查
*** GitLab 开 MR
*** Zoom Chat 通知 owner
*** 更新 LOOP.md
** 三个风险
*** Verification 永远是人的事
*** 理解债会积累
*** 思考能力会退化
** 落地清单
*** Day 1 立 Harness
*** Day 2 跑朴素 Automation
*** Day 3 加 implementer + reviewer
*** Day 4 接 Connector
*** Day 5+ 扩展任务类型
** 收束
*** Build the loop
*** 但别放弃工程师判断
@endmindmap
参考资料
- Addy Osmani, Loop Engineering
- MindStudio, What Is Loop Engineering? The New Meta for AI Coding Agents
- Addy Osmani, Agent Harness Engineering
- Addy Osmani, Long-running Agents
- Walter Fan, 从 Prompt Engineering 到 Harness Engineering:AI 编程的四次进化