Ask LLM by program
What's RAG
RAG is a technique for augmenting LLM knowledge with additional data.
RAG 是一种以额外数据来增强 LLM 知识的技术
以私有或者较新的知识插入到给模型的提示的过程就叫检索增强生成
Concepts
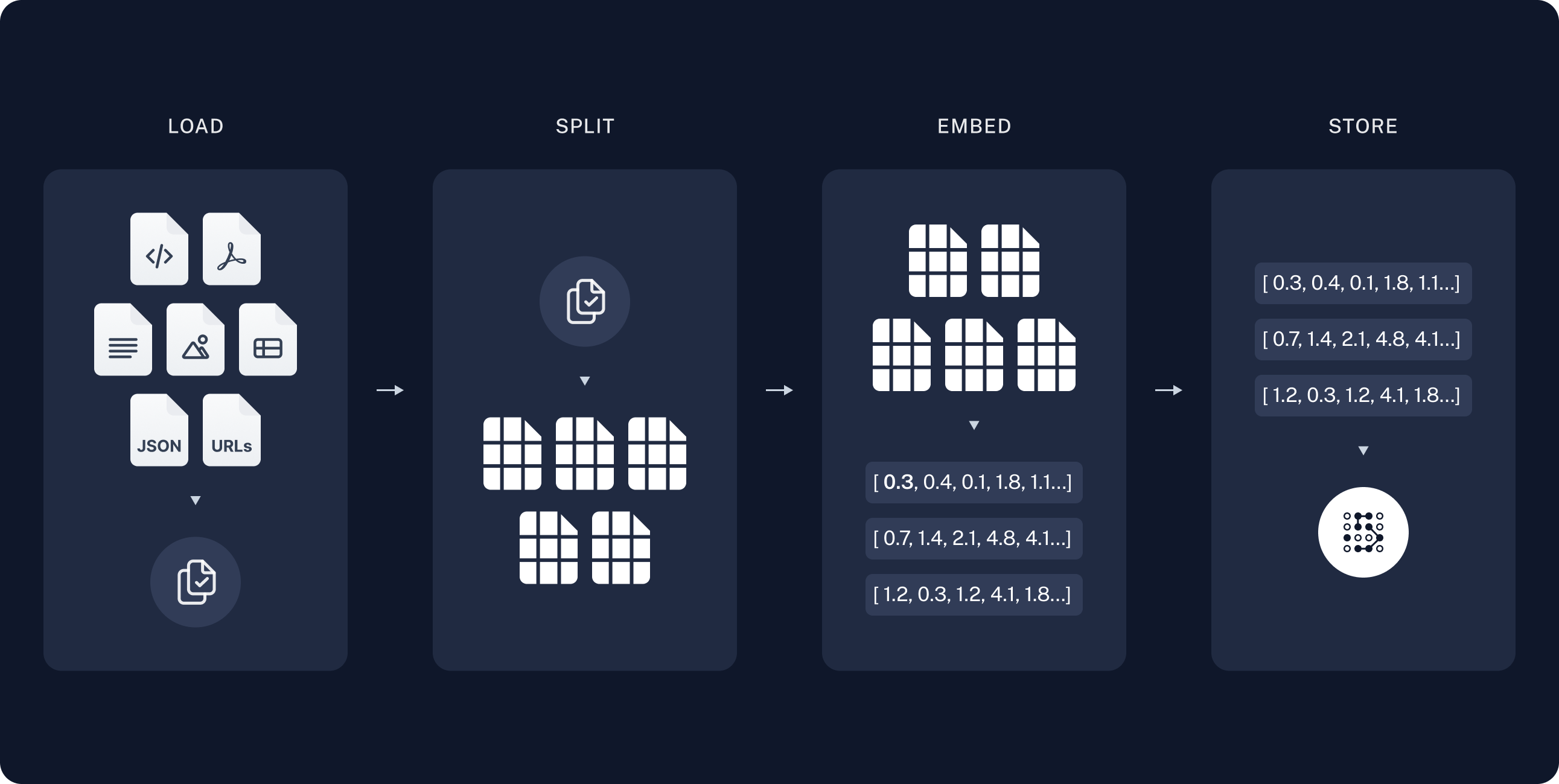
Indexing
-
Load: First we need to load our data. This is done with Document Loaders.
载入我们的知识 -
Split: Text splitters break large Documents into smaller chunks. This is useful both for indexing data and for passing it in to a model, since large chunks are harder to search over and won't fit in a model's finite context window.
拆分大文档到小块段落
- Store: We need somewhere to store and index our splits, so that they can later be searched over. This is often done using a VectorStore and Embeddings model.
存储和索引以上拆分的段落
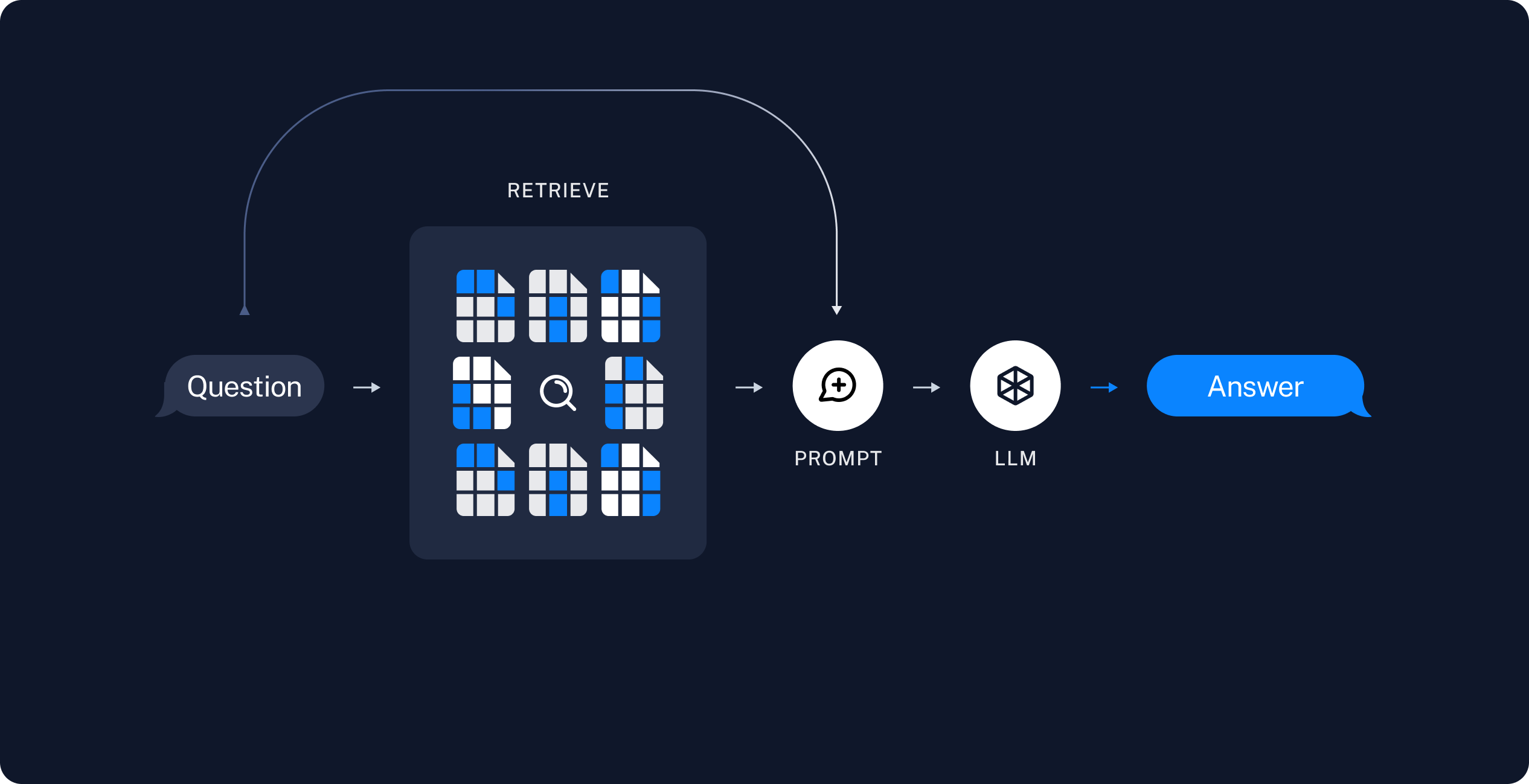
Retrieval and generation
- Retrieve: Given a user input, relevant splits are retrieved from storage using a Retriever.
给出一个用户输入, 通过 Retriver 取出的相关的拆分段落
- Generate: A ChatModel / LLM produces an answer using a prompt that includes the question and the retrieved data
生成: 一个对话模型/大语言模型使用包含问题和所检索出的数据所产生一个回答
program to ask LLM
#!/usr/bin/env python3
from openai import OpenAI
from dotenv import load_dotenv
import os, sys
import argparse
from loguru import logger
load_dotenv()
logger.add(sys.stdout,
format="{time} {message}",
filter="client",
level="DEBUG")
class LlmAgent:
def __init__(self, api_key, base_url, model):
self._client = OpenAI(api_key=api_key,
base_url=base_url)
self._model = model
def ask_question(self, question: str):
response = self._client.chat.completions.create(
model=self._model,
messages=[
{'role': 'user', 'content': question}
],
stream=True
)
for chunk in response:
print(chunk.choices[0].delta.content, end='')
if __name__ == "__main__":
parser = argparse.ArgumentParser()
parser.add_argument('--action','-a', action='store', dest='action', help='specify action: ask|test')
parser.add_argument('--model', '-m', dest='model', default="alibaba/Qwen1.5-110B-Chat", help='LLM model')
args = parser.parse_args()
if (args.action == "test"):
agent = LlmAgent(os.getenv("LLM_API_KEY"), os.getenv("LLM_BASE_URL"), args.model)
agent.ask_question("how to parse PDF file by python?")
else:
print("example:")
print("\t./ask_llm.py -a test")
answer from LLM
NoneTo parse a PDF file in Python, you can use several libraries, one of the most popular being PyPDF2 and PDFMiner for text extraction. Keep in mind that parsing PDFs can be tricky due to differences in how PDFs are structured, and complex formatted PDFs might not retain perfect formatting when extracted.
1. Using PyPDF2 (for basic text extraction):
PyPDF2 is great for splitting, merging, and cropping PDFs, but it might not handle complex formatting very well.
First, install PyPDF2:
pip install PyPDF2Here's a basic code snippet to extract text from a PDF:
import PyPDF2
def extract_text_from_pdf(pdf_path):
text = ''
with open(pdf_path, 'rb') as file:
pdf_reader = PyPDF2.PdfFileReader(file)
for page_num in range(pdf_reader.getNumPages()):
text += pdf_reader.getPage(page_num).extractText()
return text
pdf_path = 'your_pdf_file.pdf'
text = extract_text_from_pdf(pdf_path)
print(text)2. Using PDFMiner (recommended for accurate text extraction):
PDFMiner is better suited for extracting text accurately, including layout information.
First, install PDFMiner using pip:
pip install pdfminer.six # Use this for Python 3Here's a simple example of how to use PDFMiner to extract text:
from pdfminer.high_level import extract_text
def extract_text_pdfminer(pdf_path):
text = extract_text(pdf_path)
return text
pdf_path = 'your_pdf_file.pdf'
text = extract_text_pdfminer(pdf_path)
print(text)For more advanced usage, such as extracting specific elements, positions, or dealing with encrypted PDFs, consult the respective libraries’ documentation. PDFMiner, in particular, allows for a lot of customization through lower-level APIs, which can be helpful in handling complex PDF structures.None%