产线故障应对:Runbook、时间线、决策树、检查表怎么用才不慌
Posted on 四 07 5月 2026 in Method
| Abstract | 产线故障应对:Runbook、时间线、决策树、检查表怎么用才不慌 |
|---|---|
| Authors | Walter Fan |
| Category | Method |
| Status | v1.0 |
| Updated | 2026-05-07 |
| License | CC-BY-NC-ND 4.0 |
短大纲
展开看看
- **核心观点**:产线故障时,人的脑子会降级,所以要靠结构补位。 - **四件武器**:Runbook 管行动,时间线管事实,决策树管判断,检查表管遗漏。 - **使用顺序**:先止血,再记录,再分叉判断,最后用检查表关门。 - **常见误区**:Runbook 写成百科,时间线写成文学,决策树过度精密,检查表长成祖传经书。 - **落地模板**:一张故障响应卡、一份时间线模板、一棵决策树样例、一张收尾检查表。 - **明天行动**:选一个高频告警,把这四件工具先做成最小版本。正文
你有没有经历过这样的场景: 凌晨两点,电话响了。
你迷迷糊糊接起来,对面第一句话就很提神:
“线上服务好像挂了。”
这句话的杀伤力,约等于冬天洗澡时热水器突然罢工。你打开监控,错误率在爬,延迟在飙,告警像年会抽奖一样一条接一条。群里很快热闹起来:
“谁最近发版了?”
“数据库是不是慢了?”
“要不要回滚?”
“客户已经在问了,有 ETA 吗?”
这时候最怕的不是没有聪明人。恰恰相反,群里可能全是聪明人。每个人都在找线索,每个人都想帮忙,每个人都在自己的终端上“只是看看”。十分钟后,你会发现大家不是在协作,而是在进行一场多人在线密室逃脱。
产线故障的残酷之处在于:它会把人的认知能力打回出厂设置。
平时能写架构图的人,故障时可能只会问“怎么回事”;平时能讲分布式一致性的人,故障时可能忘了看用户影响;平时很冷静的人,看到老板在群里问 ETA,也会突然想给系统做法事。
所以,事故响应不能只靠“高手镇场”。高手当然重要,但真正让团队稳下来的,是提前准备好的结构。
我把它叫作四件武器:
| 武器 | 它解决什么问题 | 一句话解释 |
|---|---|---|
| Runbook | 不知道下一步做什么 | 把常见故障的处理步骤提前写好 |
| 时间线 | 不知道发生过什么 | 把现象、动作、判断、结果按时间记录下来 |
| 决策树 | 不知道该选哪条路 | 用分支问题把排查路径收敛 |
| 检查表 | 怕漏关键动作 | 用短清单防止忙中出错 |
这四件东西不高级,也不神秘。它们像厨房里的刀、锅、砧板和抹布。单看都普通,组合起来能开饭。没有它们,厨师再厉害,也容易在高峰期把盐当糖。
先说目标:故障响应不是破案,是止血
很多技术人处理故障时,第一反应是找 root cause。这个习惯不能说错,但顺序经常错。
故障发生的前 30 分钟,最重要的事通常不是证明“谁写的代码有问题”,而是回答三个问题:
- 用户是否还在受影响?
- 影响范围有没有扩大?
- 有没有低风险的止血动作?
这和医生急救一样。病人正在流血,医生不会先开三小时研讨会分析生活习惯,而是先止血、输液、稳定生命体征。根因当然要查,但不是拿用户体验当实验材料。
Google SRE 在 incident management 里反复强调角色、沟通和 live incident document。核心不是把流程搞复杂,而是承认一个事实:事故现场的脑力很贵,不能浪费在重复问问题和临时想流程上。
所以四件武器的第一原则是:
先恢复服务,再追求解释;先降低影响,再寻找优雅。
当然,这不等于乱回滚、乱重启、乱改配置。止血也要有证据、有记录、有回滚路径。否则你以为自己在救火,实际上可能是在往机房里泼汽油。
武器一:Runbook,给凌晨两点的自己留一张纸条
Runbook 的人话版是:当某类问题发生时,照着这张纸做。
它不是长篇文档,不是系统设计说明书,也不是“某位老同事脑子里的经验集合”。一个好 Runbook,要能让一个刚被电话吵醒、咖啡还没入口的人,也能按步骤把局面稳住。
Runbook 该写什么
一个故障 Runbook 不需要一上来就写成百科。最小可用版本有七块:
Runbook: <告警或故障名称>
1. 适用场景
- 哪个告警触发时使用?
- 哪些症状符合?
- 哪些情况不适用?
2. 影响判断
- 看哪些业务指标?
- 如何判断用户是否受影响?
- 如何判断严重等级?
3. 第一批检查
- 监控看哪几个面板?
- 日志查哪些关键词?
- Trace 或错误码从哪里看?
4. 常见原因
- 最近发版
- 依赖超时
- 数据库慢查询
- 缓存击穿
- 配置变更
5. 止血动作
- 回滚
- 降级
- 限流
- 扩容
- 切流量
6. 风险和回滚
- 每个动作的副作用是什么?
- 做错了怎么撤?
7. 升级路径
- 什么时候拉 SRE?
- 什么时候拉 DB?
- 什么时候通知业务和客服?
注意,这里最重要的不是“写得全”,而是“真能用”。很多 Runbook 死在第一天:写得像博士论文,打开三屏还没看到第一步。凌晨两点没人有耐心读论文,大家只想知道:现在先看哪里,做什么,谁来拍板。
一个可复制的 Runbook 片段
比如“API 错误率突增”的 Runbook,可以这样写:
Runbook: API 5xx 错误率突增
适用场景:
- 入口 API 5xx 在 5 分钟内超过 2%
- 或核心接口成功率低于 99%
第一步:确认影响
- 看业务成功率 dashboard
- 对比入口层、服务层、依赖层错误率
- 确认是否集中在某个 region / tenant / version
第二步:检查最近变更
- 最近 60 分钟是否有发版?
- 是否有配置、灰度、流量、证书、网络策略变更?
- 如果错误集中在新版本,优先准备回滚
第三步:止血选择
- 新版本导致:回滚或关闭灰度
- 单依赖超时:启用降级或延长熔断窗口
- 流量突增:限流或扩容
- 单 region 异常:切流量,保留证据
升级条件:
- 10 分钟内影响未收敛,拉 incident commander
- 影响核心客户或付费链路,通知业务 owner
- 涉及数据一致性,拉 DB 和数据平台 owner
这个片段不完美,但它有用。它让值班同学不用从零开始想:“我现在应该干什么?”
Runbook 的价值就在这里:把平时的清醒,借给故障时的自己。
武器二:时间线,让事实别被情绪淹没
故障群里最常见的灾难,不是没人干活,而是没人记账。
有人回滚了,没人知道回滚的是哪个版本;有人改了配置,没人知道改了什么;有人说“错误率下来了”,没人记录是几点开始下来的。两个小时后开复盘会,大家开始凭记忆考古。那场面很像在没有监控录像的路口判断谁闯红灯。
时间线的作用,是把事故现场从“群聊文学”变成“事实记录”。
时间线记录什么
一条合格的故障时间线,至少包含五类信息:
| 类型 | 示例 | 为什么重要 |
|---|---|---|
| 现象 | 17:03 API 5xx 从 0.2% 升到 4.8% | 确认故障开始和影响变化 |
| 判断 | 17:08 初步怀疑新版本导致 | 记录当时为什么这么想 |
| 动作 | 17:12 回滚 version 2026.05.07.3 | 便于追踪动作和副作用 |
| 结果 | 17:18 5xx 降到 0.9%,P99 仍高 | 验证动作是否有效 |
| 决策 | 17:20 暂停全量,保留 5% 灰度 | 复盘时知道谁基于什么拍板 |
时间线不要写成小说。它不需要修辞,不需要铺垫,不需要“我们怀着沉重的心情”。它只需要像账本一样冷静。
一个时间线模板
Incident Timeline
事件名称:
严重等级:
Incident Commander:
记录人:
沟通频道:
时间 | 类型 | 内容 | 负责人 | 证据链接
---- | ---- | ---- | ------ | --------
17:03 | 现象 | API 5xx 超过 4%,核心接口成功率下降 | oncall | dashboard-link
17:06 | 判断 | 错误集中在 v2026.05.07.3,怀疑新版本 | backend | log-link
17:12 | 动作 | 回滚 v2026.05.07.3 到 v2026.05.07.2 | release | deploy-link
17:18 | 结果 | 5xx 降到 0.9%,但 P99 仍高 | oncall | dashboard-link
17:22 | 决策 | 保持回滚状态,继续查数据库慢查询 | IC | chat-link
这里有个小技巧:时间线最好由一个不直接排查的人来维护。
正在查问题的人,脑子里已经塞满了日志、指标和各种猜测。让他同时记录,等于让外科医生边做手术边写病历,还要求字迹工整。可以记,但不现实。
如果团队规模允许,拉一个“记录员”或 communication owner。这个人不一定最懂技术,但要负责把关键动作写清楚,并定期在群里同步:
当前状态:
- 影响:核心 API 5xx 约 0.9%,已从峰值 4.8% 下降
- 已执行:回滚 v2026.05.07.3,无新增发版
- 正在查:数据库慢查询和依赖超时
- 下一次更新:17:35
这段话的价值很大。它能让管理者少问三次“现在怎么样”,让排查者少被打断三次,让客户沟通少猜三次。
武器三:决策树,把“我感觉”变成“我判断”
故障排查最怕的是“跳跃式推理”。
看到错误率升高,有人说“肯定是数据库”;看到数据库慢,有人说“肯定是索引”;看到索引没问题,又说“那可能是网络”。每一步都像有道理,但路径完全不受控。
决策树的作用,是把排查问题变成一组分支问题:
如果 A 成立,看 B;如果 A 不成立,看 C。
它不保证你一次命中根因,但能避免大家在一片迷雾里各走各的。
故障决策树的基本骨架
我通常会从四个问题开始:
1. 是真实用户影响,还是监控误报?
- 真实影响:进入 2
- 误报或采集异常:修监控,同时继续观察
2. 影响是全局的,还是局部的?
- 全局:看入口层、公共依赖、发布、配置
- 局部:看 region、tenant、版本、机房、AZ、节点
3. 是最近变更引起,还是容量/依赖引起?
- 最近变更:优先回滚、关闭灰度、撤配置
- 容量/依赖:优先扩容、降级、限流、切流量
4. 有低风险止血动作吗?
- 有:执行,记录,观察
- 没有:升级,扩大协作,保护现场
这棵树看起来简单,但足够把很多事故从“自由发挥”拉回“结构化排查”。
决策树不要追求完美
很多团队一写决策树,就想覆盖所有场景。结果画出来像地铁线路图,连作者自己都坐过站。
决策树的目标不是模拟宇宙,而是帮助人在压力下做相对靠谱的判断。它应该遵守三条原则:
- 从影响开始,不从技术猜测开始。 先问用户痛不痛,再问哪个模块坏。
- 从高概率、高收益分支开始。 最近发版、配置变更、依赖异常、容量突增,通常优先级更高。
- 每个叶子节点都要能行动。 如果分支最后只是“继续观察”,那就写清观察什么、多久、谁负责。
举个例子,“最近是否有变更”这个问题,不是为了甩锅,而是为了找低风险止血动作。
如果故障和新版本高度相关,回滚可能是最快的止血方式。你不需要先证明根因是某行代码。你只需要证明:回滚的风险可控,且有较大概率降低影响。
这就是事故中的工程判断:不追求当场赢得辩论,追求尽快降低损失。
武器四:检查表,专治“我以为我做了”
检查表听上去最没技术含量。
但越是高压场景,越需要它。
因为故障时我们不是不会做,而是会漏做。漏通知客户,漏关灰度,漏恢复临时配置,漏撤扩容,漏补监控,漏建复盘 action item。每个“漏”单看都不大,凑在一起就能把一次事故变成连续剧。
检查表不是给新人用的“拐杖”,而是给所有人用的“安全带”。开车二十年的老司机也要系安全带,不丢人。
故障处理中有三张检查表
第一张是启动检查表,用于刚发现故障时:
Incident Start Checklist
- [ ] 确认是否真实影响用户
- [ ] 定义严重等级
- [ ] 指定 Incident Commander
- [ ] 指定记录人和沟通负责人
- [ ] 建立单一沟通频道
- [ ] 打开时间线文档
- [ ] 暂停相关高风险发布或变更
- [ ] 确认下一次状态更新时间
第二张是止血检查表,用于执行关键动作前:
Mitigation Checklist
- [ ] 这个动作解决什么问题?
- [ ] 预期几分钟内看到什么指标变化?
- [ ] 最坏副作用是什么?
- [ ] 有没有回滚方法?
- [ ] 谁执行?
- [ ] 谁观察?
- [ ] 是否需要通知相关 owner?
- [ ] 是否记录到时间线?
第三张是收尾检查表,用于服务恢复后:
Incident Close Checklist
- [ ] 用户影响已恢复到正常水平
- [ ] 临时降级、限流、扩容、切流量已确认是否保留
- [ ] 临时权限、脚本、配置已清理或登记
- [ ] 客户和内部状态已更新
- [ ] 时间线补齐关键证据链接
- [ ] 初步 root cause 或待查方向已记录
- [ ] postmortem owner 和时间已确定
- [ ] action items 已进入 backlog,并有负责人
最后这张尤其重要。
很多事故不是死在故障当天,而是死在恢复后的松懈。服务一恢复,大家立刻鸟兽散。两周后,同类问题换个姿势再来一次,团队还很委屈:“怎么又是它?”
因为上次只是“结束了”,没有“关闭”。
四件武器怎么配合:一次故障的推荐打法
如果把事故响应压缩成一条主线,我会这样用:
0 到 5 分钟:启动结构
不要一上来就全民查日志。先指定角色:
- Incident Commander:负责总体判断和决策。
- Ops / 技术排查:负责执行检查和止血动作。
- Communication:负责状态同步和 stakeholder 沟通。
- Scribe:负责时间线。
小团队可以一人多角,但角色必须说清楚。否则每个人都以为自己在负责,最后就是没人负责。
然后打开启动检查表,建立单一沟通频道,开始时间线。
5 到 15 分钟:判断影响,选择 Runbook
先看业务指标,再看系统指标。
业务指标包括登录成功率、下单成功率、会议入会成功率、消息发送成功率这类用户真正关心的东西。CPU、内存、磁盘当然要看,但它们只是系统的血压心率,不等于病人的主观痛感。
确认影响后,选择对应 Runbook。没有完全匹配的 Runbook,就选最接近的,不要现场写诗。
15 到 30 分钟:沿决策树收敛,执行止血
用决策树问几个硬问题:
- 是全局还是局部?
- 是否和最近变更相关?
- 是否集中在某个依赖?
- 有没有低风险回滚或降级?
- 指标变化是否验证了判断?
执行任何止血动作前,过一遍 mitigation checklist。尤其要问:“如果这个动作错了,怎么撤?”
30 分钟以后:稳定节奏,定期同步
如果还没恢复,就要进入节奏管理:
- 每 15 或 30 分钟同步一次状态。
- 明确当前假设、已排除项、下一步动作。
- 控制现场变更,禁止“我顺手改一下”。
- 必要时升级人员和严重等级。
- 准备交接,避免人困到判断力下线。
事故响应很像打篮球。你不能五个人都持球单打,也不能每个人都站在三分线外喊“传我”。要有人控节奏,有人跑位,有人防守,有人抢篮板。流程不是为了束缚大家,是为了让大家别撞在一起。
最常见的四个坑
坑一:Runbook 写得太长
长文档适合学习,短 Runbook 适合救火。
救火版 Runbook 要能在 30 秒内找到第一步。复杂背景可以放链接,不要塞在正文里。最好把“先做什么”和“不要做什么”放在最上面。
坑二:时间线只记结论,不记证据
“怀疑数据库问题”不是时间线,“慢查询数量从 20/min 升到 900/min,链接如下”才是时间线。
记录证据不是为了写报告好看,而是为了避免复盘时变成罗生门。
坑三:决策树只画排查,不画止血
很多决策树最后指向“定位根因”。这当然重要,但事故中还要有止血分支。
比如依赖服务超时,根因可能要查很久,但你可以先降级、缓存、熔断、切备用路径。决策树里必须有“影响是否可降低”的问题。
坑四:检查表从不演练
没演练过的检查表,只能叫愿望清单。
每次 Game Day、演练、复盘,都应该顺手验证一下:
- 哪一步看不懂?
- 哪个链接失效了?
- 哪个命令权限不够?
- 哪个 owner 已经换人?
- 哪个检查项其实没人会执行?
Runbook 和检查表都不是文物。它们要经常被使用、被打脸、被修正。一个从没被故障现场骂过的 Runbook,多半还没成熟。
一张“故障响应卡”,先抄再改
下面这张卡可以直接作为团队的最小模板。别嫌朴素,能用比好看重要。
# Incident Response Card
事件名称:
严重等级:
开始时间:
当前状态:Investigating / Mitigating / Monitoring / Resolved
角色:
- IC:
- Ops:
- Communication:
- Scribe:
当前影响:
- 用户影响:
- 业务指标:
- 受影响范围:
当前假设:
1.
2.
3.
已执行动作:
- 时间 / 动作 / 负责人 / 结果
下一步:
- 动作:
- 负责人:
- 预期结果:
- 下次更新时间:
风险:
- 临时变更:
- 待回滚项:
- 待通知对象:
如果只能做一件事,就先把这张卡放到团队文档里,并在告警群置顶。
它不能替你解决所有问题,但能让团队在最混乱的前十分钟少走很多弯路。
总结:稳定来自结构,不来自鸡血
产线故障一定会发生。系统越复杂,变化越频繁,就越不可能靠“大家小心一点”解决问题。
我越来越相信一句朴素的话:
专业不是不会慌,专业是慌的时候还有结构可依。
Runbook 让你知道下一步做什么,时间线让你知道已经发生了什么,决策树让你知道该往哪边判断,检查表让你别在最后一公里摔跤。
四件武器合在一起,解决的不是某个单点技术问题,而是事故响应里的四种混乱:
- 行动混乱:用 Runbook 收住。
- 事实混乱:用时间线收住。
- 判断混乱:用决策树收住。
- 收尾混乱:用检查表收住。
别等下一次事故发生时再开始补文档。那时候你的大脑已经在冒烟了,键盘上还可能沾着半杯冷咖啡。
明天就能做的 5 件事
- 找一个最常见的告警,写一个 10 行以内的 Runbook。
- 给团队建一个 incident timeline 模板,字段越少越好。
- 为一个核心链路画一棵三层以内的决策树。
- 把启动、止血、收尾三张检查表放到值班文档首页。
- 下次演练时强制使用这四件工具,演练后只问一个问题:哪一步卡住了?
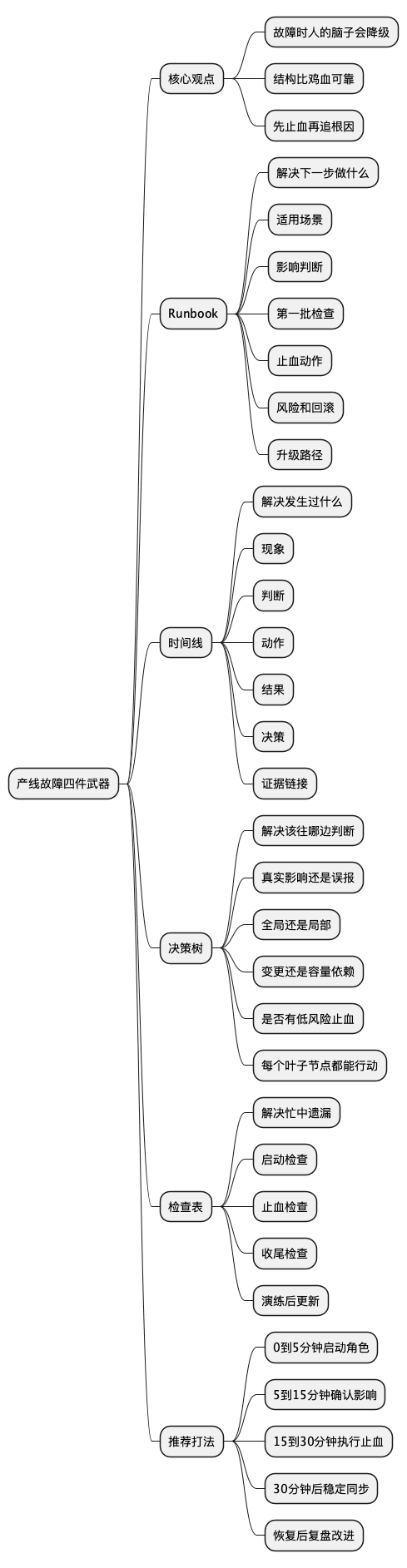
思维导图
@startmindmap
* 产线故障四件武器
** 核心观点
*** 故障时人的脑子会降级
*** 结构比鸡血可靠
*** 先止血再追根因
** Runbook
*** 解决下一步做什么
*** 适用场景
*** 影响判断
*** 第一批检查
*** 止血动作
*** 风险和回滚
*** 升级路径
** 时间线
*** 解决发生过什么
*** 现象
*** 判断
*** 动作
*** 结果
*** 决策
*** 证据链接
** 决策树
*** 解决该往哪边判断
*** 真实影响还是误报
*** 全局还是局部
*** 变更还是容量依赖
*** 是否有低风险止血
*** 每个叶子节点都能行动
** 检查表
*** 解决忙中遗漏
*** 启动检查
*** 止血检查
*** 收尾检查
*** 演练后更新
** 推荐打法
*** 0到5分钟启动角色
*** 5到15分钟确认影响
*** 15到30分钟执行止血
*** 30分钟后稳定同步
*** 恢复后复盘改进
@endmindmap
扩展阅读
- Google SRE Book: Managing Incidents
- Google SRE Workbook: Incident Response
- Atlassian Incident Management Handbook
- PagerDuty: What is a Runbook?
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。