给 secrets 表加 history 表:这是不是一个靠谱的审计方案?
Posted on 一 27 4月 2026 in Tech
| Abstract | 给 secrets 表加 history 表:这是不是一个靠谱的审计方案? |
|---|---|
| Authors | Walter Fan |
| Category | Database |
| Status | v1.0 |
| Updated | 2026-04-27 |
| License | CC-BY-NC-ND 4.0 |
给 secrets 表加 history 表:这是不是一个靠谱的审计方案?
短大纲
- 先纠正几个前提:MySQL 有 trigger,也有分区;但你的环境可能不允许用
secrets_action_history能解决什么,不能解决什么- 如何把 history 表当作时间窗口变更索引,而不是只当审计流水
- 一张 history 表应该怎么设计,才不至于三个月后变成事故现场
- MySQL 分区能不能像 Oracle 一样用?能,但有自己的脾气
- 如何定时清理、分区归档、降级和验证这个方案
一、先说结论:可以做,但别把 history 表当时光机
这个需求乍一看很朴素:
secrets表发生新增、修改、删除时,写一条记录到secrets_action_history。以后我按created_at查 history 表,就知道某个时间段里 secrets 表发生了什么变化。
听起来像给数据库装了一个行车记录仪。车开到哪、谁踩了刹车、谁打了方向盘,都能回放。
我认为这个方案可以做,而且在很多系统里是必要的。但它不能只靠“建一张 history 表”这几个字糊过去。尤其当表名叫 secrets 时,事情会立刻从“记录变更”升级成“审计、合规、性能、数据保留、敏感信息保护”的组合拳。
一句话结论:
secrets_action_history 不只是审计流水,更应该是一张“按时间窗口查变更”的索引表。它适合帮我们找出某段时间内哪些 secret 变过,再驱动备份、review 或 revise;但不要把它当成完整的数据恢复方案,更不要把 secret 明文塞进去。
这就像公司门口的监控加访客登记。它能告诉你谁进了门、几点进的、带走了哪个箱子的编号。你可以据此去复核、备份、回滚流程,但不能指望它替你保管保险柜钥匙。
二、先把两个误区掰正:MySQL 不是没有 trigger,也不是没有分区
用户常说“mysql 没有 trigger,没有分区”,这句话大概率不是指 MySQL 产品本身,而是指当前系统有这些约束:
- 线上规范不允许建 trigger;
- DBA 不建议在核心表上使用 trigger;
- 当前
secrets表没有做分区; - 当前 MySQL 版本、托管平台或权限模型限制了某些 DDL;
- 团队不希望把业务逻辑藏进数据库对象里。
MySQL 本身是支持 trigger 的。官方 CREATE TRIGGER 文档明确支持 BEFORE / AFTER 的 INSERT、UPDATE、DELETE 事件。
MySQL 也支持分区。MySQL 8.4 文档里说明,InnoDB 和 NDB 支持用户自定义分区。常见的审计表、日志表,通常会考虑按时间做 RANGE 分区。
所以真正的问题不是“有没有”,而是:
在我们的工程约束下,哪一种记录方式最稳、最可控、最不容易在半夜把自己叫醒?
三、这个方案到底想解决什么?
先别急着建表。我们要先问清楚:你想通过 history 表回答哪类问题?
常见答案有五种:
- 追责:谁在什么时候改了哪个 secret?
- 排障:某段时间服务异常,是不是某个 secret 被轮换、禁用或删除了?
- 审计:安全团队要看敏感配置的操作记录。
- 增量处理:找出某个时间段内变更过的 secret,做备份、review 或 revise。
- 恢复:误删了 secret,能不能找回?
前四个,history 表很适合。尤其是第四个,才是这张表的工程价值:我们不想扫 secrets 全表,只想拿到一个时间窗口里的变更集合。
第五个,要小心。恢复不是简单地把旧值写回去。secrets 这种表通常牵涉加密、版本、权限、租户、引用关系、轮换状态、缓存失效、下游服务重载。你只记录一行 old_value,看起来很贴心,实际可能是在 history 表里埋了一枚“泄密盲盒”。
更稳妥的定位是:
- history 表记录操作事实;
- history 表充当变更索引,用时间窗口快速定位受影响的
secret_id; - secret 内容只记录脱敏摘要、版本号、哈希、引用 ID;
- 真正的恢复走正式的 secret version / backup / approval 流程;
- history 表负责告诉你“该查哪个版本、找谁审批、为什么发生”。
四、推荐的数据模型:记录动作,不复制保险柜
一个比较克制的表可以这样设计:
CREATE TABLE secrets_action_history (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
secret_id BIGINT UNSIGNED NOT NULL,
action_type ENUM('INSERT', 'UPDATE', 'DELETE', 'ROTATE', 'DISABLE', 'ENABLE') NOT NULL,
actor_id BIGINT UNSIGNED NULL,
actor_name VARCHAR(128) NULL,
request_id VARCHAR(128) NULL,
source_ip VARBINARY(16) NULL,
user_agent_hash CHAR(64) NULL,
old_version BIGINT UNSIGNED NULL,
new_version BIGINT UNSIGNED NULL,
old_fingerprint CHAR(64) NULL,
new_fingerprint CHAR(64) NULL,
changed_fields JSON NULL,
reason VARCHAR(512) NULL,
created_at DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
PRIMARY KEY (id, created_at),
KEY idx_secret_created (secret_id, created_at),
KEY idx_created_at (created_at),
KEY idx_window_changes (created_at, id, secret_id, action_type, new_version),
KEY idx_actor_created (actor_id, created_at)
)
PARTITION BY RANGE COLUMNS(created_at) (
PARTITION p202604 VALUES LESS THAN ('2026-05-01'),
PARTITION p202605 VALUES LESS THAN ('2026-06-01'),
PARTITION pmax VALUES LESS THAN (MAXVALUE)
);
这里有几个细节,不是装饰,是保命:
action_type记录动作类型,不要靠 diff 去猜。request_id用来串起 API 日志、应用日志、审计日志。old_fingerprint/new_fingerprint是摘要,不是 secret 明文。changed_fields只放字段名和必要的非敏感元数据。created_at必须有索引,因为你的主要查询方式就是按时间扫。idx_window_changes是给“按时间窗口拉取变更”的流程用的,尽量让查询先走索引拿到secret_id和版本信息。PRIMARY KEY (id, created_at)是为了适配 MySQL 分区限制,后面会展开。
如果 secrets 表真的保存了敏感值,千万别把 old_secret_value、new_secret_value 这种字段随手塞进 history 表。很多泄密事故不是黑客多厉害,而是我们自己把敏感信息复制了三份:主表一份,日志一份,history 一份。黑客看了都想说一句:谢谢招待。
五、把 history 表当“变更索引”来用
如果目标是“知道某个时间段内 secrets 表变了什么,并对这些记录做备份、review 或 revise”,那 history 表的角色就不只是审计,而是 change index。
这时关键查询不是:
SELECT *
FROM secrets;
而是:
SELECT id, secret_id, action_type, old_version, new_version, created_at
FROM secrets_action_history FORCE INDEX (idx_window_changes)
WHERE created_at >= '2026-04-27 10:00:00'
AND created_at < '2026-04-27 11:00:00'
ORDER BY created_at, id
LIMIT 1000;
这条 SQL 的意义很朴素:先从很小的时间窗口里拿到变更事件,再根据 secret_id 去处理目标记录。它不碰 secrets 全表,也不指望 updated_at 在主表上救命。
如果窗口很大,要用 keyset pagination,不要用很深的 OFFSET:
SELECT id, secret_id, action_type, old_version, new_version, created_at
FROM secrets_action_history FORCE INDEX (idx_window_changes)
WHERE created_at >= '2026-04-27 10:00:00'
AND created_at < '2026-04-27 11:00:00'
AND (created_at, id) > ('2026-04-27 10:20:00.123456', 987654321)
ORDER BY created_at, id
LIMIT 1000;
拿到变更事件后,通常有两种处理方式。
第一种,逐条处理事件,适合做审计回放、备份每一次变更、生成 review 记录:
SELECT h.id, h.secret_id, h.action_type, h.old_version, h.new_version, h.created_at
FROM secrets_action_history h FORCE INDEX (idx_window_changes)
WHERE h.created_at >= ?
AND h.created_at < ?
ORDER BY h.created_at, h.id;
第二种,按 secret_id 去重,适合“只关心这段时间内哪些 secret 需要被复核或修正”:
SELECT h.secret_id,
MIN(h.created_at) AS first_changed_at,
MAX(h.created_at) AS last_changed_at,
COUNT(*) AS change_count
FROM secrets_action_history h FORCE INDEX (idx_window_changes)
WHERE h.created_at >= ?
AND h.created_at < ?
GROUP BY h.secret_id;
如果要对这些变更做人工 review / revise,我建议不要把处理状态塞回 secrets_action_history。history 表最好保持不可变。可以单独建一张任务表:
CREATE TABLE secrets_change_review_task (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY,
window_start DATETIME(6) NOT NULL,
window_end DATETIME(6) NOT NULL,
secret_id BIGINT UNSIGNED NOT NULL,
first_history_id BIGINT UNSIGNED NOT NULL,
last_history_id BIGINT UNSIGNED NOT NULL,
change_count INT UNSIGNED NOT NULL,
status ENUM('PENDING', 'BACKED_UP', 'REVIEWED', 'REVISED', 'SKIPPED') NOT NULL DEFAULT 'PENDING',
reviewer_id BIGINT UNSIGNED NULL,
reviewed_at DATETIME(6) NULL,
note VARCHAR(512) NULL,
created_at DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
UNIQUE KEY uk_window_secret (window_start, window_end, secret_id),
KEY idx_status_created (status, created_at),
KEY idx_secret_created (secret_id, created_at)
);
这样分工更清楚:
secrets_action_history负责记录“发生过什么”,保持不可变;secrets_change_review_task负责记录“我们打算怎么处理、处理到哪一步”;- 备份系统根据
secret_id + version去拿该拿的版本,不从 history 表里抠 secret 内容。
这也是避免全表扫描的核心套路:先用 history 表缩小候选集,再对候选 secret 做精确处理。
六、记录方式怎么选:trigger、应用层、CDC,各有账单
有三种常见做法。
1. Trigger:覆盖面好,但容易变成隐藏逻辑
如果允许使用 trigger,可以在 secrets 表上建 AFTER INSERT、AFTER UPDATE、AFTER DELETE,由数据库自动写 history。
优点是覆盖面强。只要有人改表,哪怕绕过应用,也能记录。
缺点也很明显:
- 业务逻辑藏在数据库里,新人排障容易漏看;
- trigger 失败会影响原事务;
- 高写入场景下会放大写入成本;
- 复杂逻辑不好测试、灰度和回滚;
- 有些 DDL、
TRUNCATE、级联外键动作,并不会按你想象的方式触发 trigger。
适合的场景:变更低频、审计要求强、DBA 能接受、逻辑非常简单。
2. 应用层写 history:最透明,但怕漏网之鱼
在服务代码里,当 secrets 发生变更时,同一个事务内写入 secrets_action_history。
伪代码大概是:
START TRANSACTION;
UPDATE secrets
SET status = 'DISABLED',
updated_at = NOW(6)
WHERE id = ?;
INSERT INTO secrets_action_history (
secret_id, action_type, actor_id, request_id,
old_version, new_version, changed_fields, reason, created_at
) VALUES (
?, 'DISABLE', ?, ?,
?, ?, JSON_OBJECT('status', JSON_ARRAY('ACTIVE', 'DISABLED')), ?, NOW(6)
);
COMMIT;
优点是清楚、可测试、可 code review,也方便补充上下文,比如工单号、审批理由、调用链 ID。
缺点是必须管住所有写入口。如果有人直接连库改数据,history 表就会少一段。于是你需要配套:
- 禁止业务账号直接写库;
- 所有写操作走统一 service;
- 定期对比
secrets.updated_at与 history 最新记录; - 对高危 DDL 和直连 SQL 做单独审计。
适合的场景:微服务写入口可控,团队更重视可维护性和测试。
3. CDC / binlog:旁路审计强,但链路更长
还有一种做法是从 binlog 订阅变更,再写入审计系统或 history 表。比如用 Debezium、Canal 或自研 CDC pipeline。
优点是对业务侵入小,也能捕获数据库层面的变更。
缺点是链路长,延迟、重放、幂等、schema 演进都要处理。你本来只想记个小账,结果搭了个小型物流系统:仓库、快递、签收、丢件赔付,一个都不能少。
适合的场景:多个系统都要统一审计,或者已经有成熟 CDC 基础设施。
我的保守建议是:
如果
secrets变更低频、写入口可控,优先应用层同事务写 history;如果绕库修改不可避免,再考虑 trigger 或 CDC 补位。
七、history 表会越来越大,怎么维护?
会,而且一定会。
审计表有个特点:平时没人看,出事时每个人都要查。它像灭火器,挂在墙上时嫌占地方,真冒烟了谁都嫌它不够大。
维护策略要在建表第一天就写清楚。
1. 先定保留周期
不要上来就问“怎么删”。先问:
- 安全审计要求保留多久?90 天、180 天、1 年,还是 7 年?
- 热查询只需要多久?最近 30 天,还是最近 6 个月?
- 过期数据是直接删除,还是归档到对象存储 / 冷库?
- 删除动作本身要不要留下审计记录?
一个常见策略是:
- 最近 90 天留在 MySQL 热表;
- 90 天到 1 年归档到冷存储;
- 超过合规要求后按流程销毁;
- 销毁脚本记录执行批次、时间、影响行数。
2. 小表:用 MySQL Event Scheduler 分批 DELETE
如果数据量不大,最简单的做法是定时任务加小批量删除。前提是 created_at 上有索引:
CREATE INDEX idx_created_at ON secrets_action_history(created_at);
再确认 MySQL 的 Event Scheduler 是否开启:
SHOW VARIABLES LIKE 'event_scheduler';
如果没有开启,需要由有权限的账号打开:
SET GLOBAL event_scheduler = ON;
然后创建一个定时清理任务。比如保留 180 天,每 10 分钟最多删 5000 行:
CREATE EVENT IF NOT EXISTS ev_cleanup_secrets_action_history
ON SCHEDULE EVERY 10 MINUTE
DO
DELETE FROM secrets_action_history
WHERE created_at < NOW(6) - INTERVAL 180 DAY
ORDER BY created_at
LIMIT 5000;
注意,是小批量循环删,不要一把梭。
DELETE FROM secrets_action_history
WHERE created_at < NOW(6) - INTERVAL 180 DAY;
这种写法看起来清爽,实际容易制造大事务、长时间锁等待、undo 膨胀、binlog 暴涨和主从延迟。你以为自己在清理垃圾,InnoDB 以为你在办拆迁。
Event Scheduler 适合“删一点、歇一会儿、再删一点”的节奏。如果一次事件还没执行完,下一次又来了,还要考虑并发执行问题。稳妥一点,可以把清理逻辑放进存储过程,用 GET_LOCK() 做互斥;或者干脆交给外部 cron / Kubernetes CronJob / 运维调度系统来跑。
3. 大表:按时间分区,过期后 DROP PARTITION
如果 history 表每天写入很多,按时间分区会更合适。MySQL 支持按照 DATETIME / DATE 字段做 RANGE COLUMNS 分区,审计表常见做法是按月分区:
CREATE TABLE secrets_action_history (
id BIGINT UNSIGNED NOT NULL AUTO_INCREMENT,
secret_id BIGINT UNSIGNED NOT NULL,
action_type VARCHAR(32) NOT NULL,
created_at DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
PRIMARY KEY (id, created_at),
KEY idx_created_at (created_at),
KEY idx_window_changes (created_at, id, secret_id, action_type),
KEY idx_secret_created (secret_id, created_at)
)
PARTITION BY RANGE COLUMNS(created_at) (
PARTITION p202604 VALUES LESS THAN ('2026-05-01'),
PARTITION p202605 VALUES LESS THAN ('2026-06-01'),
PARTITION p202606 VALUES LESS THAN ('2026-07-01'),
PARTITION pmax VALUES LESS THAN (MAXVALUE)
);
过期时直接 DROP PARTITION,速度通常比大范围 DELETE 更可控,也更容易释放空间。
ALTER TABLE secrets_action_history DROP PARTITION p202604;
但这里有一个重要提醒:DROP PARTITION 会丢弃该分区里的数据。执行前要确认归档完成,并且最好有自动化脚本做校验。
4. 保留一个 pmax,定期拆分
可以保留一个兜底分区:
PARTITION pmax VALUES LESS THAN (MAXVALUE)
然后每个月提前创建下个月分区,避免新数据都落进 pmax。典型做法是用运维脚本、cron、Kubernetes CronJob 或数据库变更平台定期执行 REORGANIZE PARTITION。
示意:
ALTER TABLE secrets_action_history
REORGANIZE PARTITION pmax INTO (
PARTITION p202606 VALUES LESS THAN ('2026-07-01'),
PARTITION pmax VALUES LESS THAN (MAXVALUE)
);
这件事必须监控。分区维护脚本如果悄悄失败,几个月后你会发现所有新数据挤在 pmax 里,像早高峰所有车都堵在同一个收费口。
我个人更倾向于把 ADD / DROP / REORGANIZE PARTITION 放在外部调度系统里,而不是藏在 MySQL Event 里。原因很简单:分区 DDL 是运维动作,最好有发布记录、审批、日志、告警和回滚预案。数据库自己半夜默默改自己的表结构,听起来很自动化,出事时也很自动化。
一个可落地的月度任务可以长这样:
每月 1 日 03:00:
1. 检查下下个月分区是否存在,不存在就创建;
2. 检查 180 天前的分区是否已经归档;
3. 归档校验通过后 DROP 老分区;
4. 查询 INFORMATION_SCHEMA.PARTITIONS,确认 pmax 没有异常数据;
5. 记录本次任务的分区名、归档位置、删除行数估算和执行人。
这里的关键不是“自动删”,而是“可证明地删”。审计表的清理本身,也应该能被审计。
八、MySQL 分区像不像 Oracle?像,但不要照搬
MySQL 有类似 Oracle 的分区能力,比如 RANGE、LIST、HASH、KEY 分区,也支持 ADD PARTITION、DROP PARTITION、TRUNCATE PARTITION、REORGANIZE PARTITION 等操作。
但 MySQL 分区有几个容易踩的坑。
1. 唯一键必须包含分区字段
这是很多人第一次做 MySQL 分区时最容易撞墙的地方。
MySQL 要求:分区表达式里的列,必须包含在表的每一个唯一键里,包括主键。
如果你按 created_at 分区,但主键只有 id,可能会报错。所以示例里用了:
PRIMARY KEY (id, created_at)
这会影响你的索引设计和 ORM 映射。不要等 DDL 上线前一天才发现。
2. 分区不是性能魔法
按时间查最近 7 天,分区裁剪会有帮助。
但如果你经常按 secret_id 查某个 secret 的全量历史,分区不一定让查询更快,索引仍然关键:
KEY idx_secret_created (secret_id, created_at)
分区解决的是“按时间管理数据生命周期”的问题,不是替代索引,更不是给慢 SQL 撒金粉。
3. 分区会增加运维责任
你需要维护:
- 新分区提前创建;
- 老分区归档后删除;
- 分区数量不要无限增长;
- DDL 在主从、备份、恢复流程里的影响;
- ORM、迁移工具是否支持分区语法;
- 监控分区是否命中、是否落入
pmax。
这不是不能做,而是要承认它不是免费的。
九、这个方案的真正风险清单
如果让我 review 这个方案,我会重点问这些问题。
1. 你记录的是“谁改了”,还是“数据库自己说改了”?
如果 history 表只记录 secret_id、action_type、created_at,价值有限。出事时安全同事会继续追问:
- 谁改的?
- 从哪里改的?
- 通过哪个 API?
- 有没有审批单?
- 变更前后分别是什么版本?
- 这个变更影响了哪些服务?
所以 actor、request_id、reason、version 这些字段不是锦上添花,而是审计场景里的主菜。
2. 删除能不能被可靠记录?
DELETE 前要能拿到旧数据。应用层写 history 时,通常要先 SELECT ... FOR UPDATE 拿到旧版本,再删除,再写 history。否则你只知道“删了一个 id”,不知道删的是谁。
如果是软删除,事情会简单一些:
UPDATE secrets
SET deleted_at = NOW(6),
status = 'DELETED'
WHERE id = ?;
对 secret 管理系统,我通常更偏向软删除加版本化,而不是物理删除后寄希望于 history 表救命。
3. history 写失败时,主操作怎么办?
这是关键产品决策。
- 如果审计强一致:history 写失败,主操作必须回滚。
- 如果业务可用性优先:主操作成功,history 异步补偿,但要有告警和重试。
secrets 属于敏感资产,我倾向于强一致:没有审计记录的 secret 变更,不应该成功。
当然,这句话有代价。history 表不可用时,secret 变更会被阻断。所以 history 表本身也要纳入可用性设计:容量、索引、备份、慢 SQL、告警,一个都不能少。
4. history 表会不会泄密?
这是最容易被低估的问题。
不要记录 secret 明文。不要记录可逆密文。不要记录能拼回 secret 的片段。最好只记录:
- secret 的稳定 ID;
- 版本号;
- 哈希摘要或 fingerprint;
- 字段级变更摘要;
- 审批和操作上下文。
history 表的访问权限也要收紧。它不是普通日志表,而是敏感操作档案。
5. 用 created_at 看时间段是否足够?
created_at 是 history 记录的创建时间,不一定等同于业务事件发生时间。多数情况下二者很接近,但异步 CDC、重试补偿、跨时区写入都会让它们产生差异。
更严谨的设计可以拆成两个时间:
event_time:业务变更发生时间;recorded_at:history 记录落库时间。
如果是应用层同事务写,二者可以相同。如果是 CDC,最好分开。
十、一个更完整的落地实施方案
如果把这件事做成一个可以上线的方案,我会按八步走。
第一步:明确边界
先写清楚三句话:
- history 表用于审计、排障、合规和时间窗口增量处理,不直接承担 secret 恢复职责;
- history 表不保存 secret 明文、可逆密文或可拼回 secret 的字段;
- 没有 history 记录的 secret 变更,默认不允许成功,除非业务明确接受异步补偿。
第二步:让 secrets 自身版本化
secrets 表至少要有版本、更新时间和软删除字段:
ALTER TABLE secrets
ADD COLUMN version BIGINT UNSIGNED NOT NULL DEFAULT 1,
ADD COLUMN updated_at DATETIME(6) NOT NULL DEFAULT CURRENT_TIMESTAMP(6),
ADD COLUMN deleted_at DATETIME(6) NULL;
如果已经有 version 或 updated_at,不要为了文章里的字段名硬改;关键是能回答“当前 secret 是第几个版本、什么时候变的、是否还有效”。
第三步:统一写入口
所有写操作走统一 service,并在同一个事务里写 history。这个 service 要负责生成 request_id,拿到 actor_id,记录审批原因,并确保主表和 history 表一起提交或一起回滚。
如果存在绕过 service 的直连库操作,要么补 trigger / CDC,要么在权限上禁止。不要把“大家自觉”写进设计文档。数据库不认识自觉。
第四步:按时间窗口生成处理清单
对备份、review、revise 这类动作,不要直接扫 secrets。先按时间窗口从 history 表里拉变更事件,再生成任务:
INSERT INTO secrets_change_review_task (
window_start,
window_end,
secret_id,
first_history_id,
last_history_id,
change_count
)
SELECT ? AS window_start,
? AS window_end,
h.secret_id,
MIN(h.id) AS first_history_id,
MAX(h.id) AS last_history_id,
COUNT(*) AS change_count
FROM secrets_action_history h FORCE INDEX (idx_window_changes)
WHERE h.created_at >= ?
AND h.created_at < ?
GROUP BY h.secret_id
ON DUPLICATE KEY UPDATE
last_history_id = VALUES(last_history_id),
change_count = VALUES(change_count);
然后由备份程序或 review 工具消费 secrets_change_review_task。这样主表只会被精确访问,不需要全表扫描。
第五步:选择清理模型
按数据量和审计要求选择清理模型:
| 场景 | 推荐做法 | 说明 |
|---|---|---|
| 每天几千到几万条 | Event Scheduler / 外部任务分批 DELETE |
简单,保留 created_at 索引,控制每批行数 |
| 每天几十万到百万级 | 按月或按周分区 | 归档后 DROP PARTITION,更适合长期维护 |
| 强审计 / 强合规 | 先归档,再清理 | 清理动作本身也要留记录 |
如果不确定增长量,先用分批 DELETE,但表结构预留按时间分区的设计空间。等表已经大到不能轻松改 DDL 时再想分区,就像车开上高速才想装刹车片。
第六步:建立分区生命周期
按月分区时,至少要维护三个动作:
- Create ahead:提前创建未来 1-2 个月分区;
- Archive:把过期分区导出到冷存储或审计归档;
- Drop:归档校验通过后删除老分区。
一个最小巡检 SQL:
SELECT PARTITION_NAME, PARTITION_DESCRIPTION, TABLE_ROWS
FROM INFORMATION_SCHEMA.PARTITIONS
WHERE TABLE_SCHEMA = DATABASE()
AND TABLE_NAME = 'secrets_action_history'
ORDER BY PARTITION_ORDINAL_POSITION;
如果 pmax 里开始有明显数据,说明未来分区没有及时创建,要立刻处理。
第七步:加监控和一致性检查
上线后至少加三个巡检:
- 检查
pmax是否有数据; - 检查最近一天
secrets.updated_at与 history 是否能对上; - 检查 history 表增长速度、慢 SQL 和分区数量。
再加一个很实用的业务检查:抽样找出最近 24 小时变更过的 secret,确认每一次变更都有对应 history。
SELECT s.id, s.updated_at
FROM secrets s
WHERE s.updated_at >= NOW(6) - INTERVAL 1 DAY
AND NOT EXISTS (
SELECT 1
FROM secrets_action_history h
WHERE h.secret_id = s.id
AND h.created_at >= s.updated_at - INTERVAL 5 SECOND
AND h.created_at <= s.updated_at + INTERVAL 5 SECOND
);
这个 SQL 只是示意,真实系统要结合 version、request_id 和写入事务来做更准确的校验。
第八步:写清楚失败预案
最后,必须回答三个问题:
- history 表写失败时,主操作是回滚还是进入补偿队列?
- 清理任务失败时,谁收到告警,多久内处理?
- 误删分区时,从哪里恢复,恢复演练有没有做过?
这套方案不花哨,但比较像工程。工程不是把所有风险消灭,而是知道每个风险在哪里、谁负责、出事时怎么验证。
十一、明天就能做的 Checklist
如果你要推进这个方案,可以按这个清单走:
- 明确 history 表目标:审计、排障、合规,还是恢复;不要混成一句“都要”。
- 禁止记录 secret 明文,只记录版本、fingerprint、字段摘要和操作上下文。
- 选择写入方式:优先应用层同事务;有绕库风险时评估 trigger 或 CDC。
- 为
created_at、secret_id + created_at、actor_id + created_at建索引。 - 为时间窗口处理增加
idx_window_changes (created_at, id, secret_id, action_type, new_version)这类索引。 - 备份 / review / revise 先从 history 表生成候选
secret_id,再精确访问主表。 - 如果数据增长快,建表时就按月
RANGE COLUMNS(created_at)分区。 - 定义保留周期:热数据多久、归档多久、销毁多久。
- 小数据量用 Event Scheduler 或外部任务分批
DELETE,不要一把梭。 - 自动化分区维护:提前建新分区,归档后 drop 老分区,监控
pmax。 - 把分区清理做成可审计任务:记录分区名、归档位置、执行结果和影响范围。
- 制定失败策略:history 写失败时,是回滚主操作,还是异步补偿。
- 每周做一次一致性巡检:主表变更与 history 记录是否对得上。
总结
secrets_action_history 不是坏方案。真正危险的是把它当成一个“顺手建表”的小需求。
对 secrets 这种敏感数据来说,history 表至少有四个身份:审计账本、排障线索、合规证据、变更索引。它应该记录操作事实和受影响的 secret_id,帮助我们按时间窗口生成备份、review、revise 的候选集,而不是复制 secret 本身;它应该服务精确处理和追责,而不是偷偷承担恢复系统的职责;它应该从第一天就设计生命周期,而不是等磁盘报警后再讨论“能不能删点”。
MySQL 有 trigger,也有分区。但工程上真正要回答的是:谁来写、写什么、怎么按时间窗口查、失败怎么办、长大以后怎么清理、出事时能不能信。
好的 history 表,不是把过去完整搬进数据库。它更像一条清楚的线索:当你需要回到案发现场时,它能告诉你从哪里开始查。
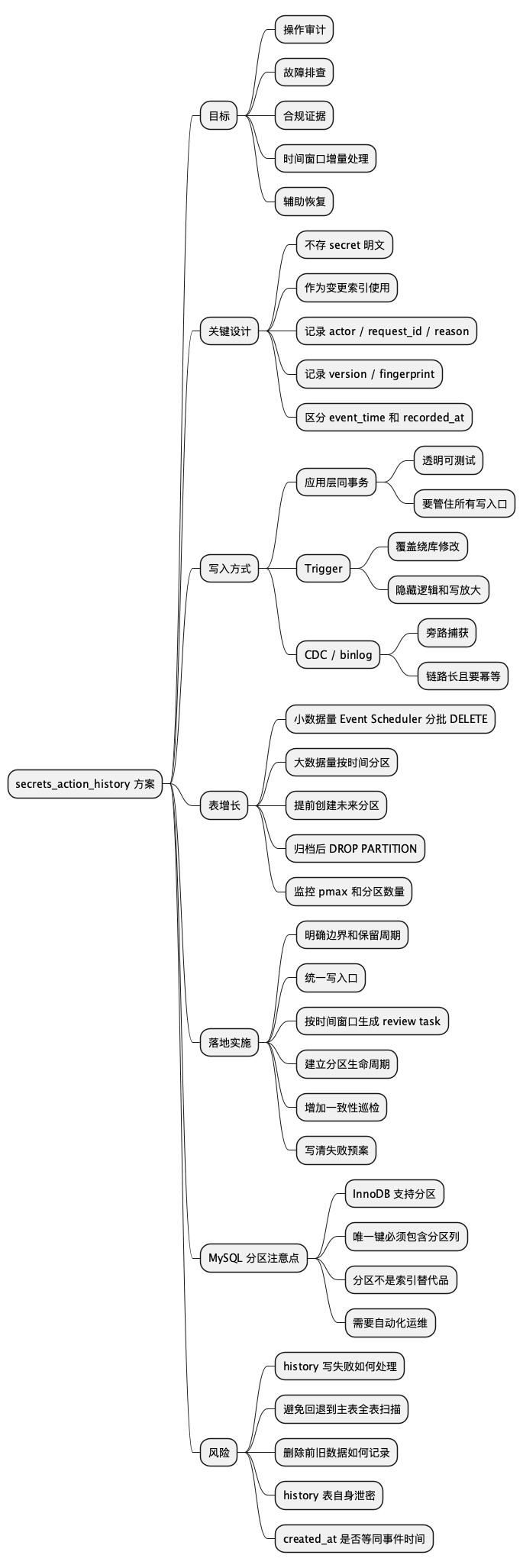
思维导图
@startmindmap
* secrets_action_history 方案
** 目标
*** 操作审计
*** 故障排查
*** 合规证据
*** 时间窗口增量处理
*** 辅助恢复
** 关键设计
*** 不存 secret 明文
*** 作为变更索引使用
*** 记录 actor / request_id / reason
*** 记录 version / fingerprint
*** 区分 event_time 和 recorded_at
** 写入方式
*** 应用层同事务
**** 透明可测试
**** 要管住所有写入口
*** Trigger
**** 覆盖绕库修改
**** 隐藏逻辑和写放大
*** CDC / binlog
**** 旁路捕获
**** 链路长且要幂等
** 表增长
*** 小数据量 Event Scheduler 分批 DELETE
*** 大数据量按时间分区
*** 提前创建未来分区
*** 归档后 DROP PARTITION
*** 监控 pmax 和分区数量
** 落地实施
*** 明确边界和保留周期
*** 统一写入口
*** 按时间窗口生成 review task
*** 建立分区生命周期
*** 增加一致性巡检
*** 写清失败预案
** MySQL 分区注意点
*** InnoDB 支持分区
*** 唯一键必须包含分区列
*** 分区不是索引替代品
*** 需要自动化运维
** 风险
*** history 写失败如何处理
*** 避免回退到主表全表扫描
*** 删除前旧数据如何记录
*** history 表自身泄密
*** created_at 是否等同事件时间
@endmindmap
扩展阅读
- MySQL 8.4 Reference Manual: CREATE TRIGGER Statement
- MySQL 8.4 Reference Manual: Partitioning
- MySQL 8.4 Reference Manual: ALTER TABLE Partition Operations
- MySQL 8.4 Reference Manual: Partitioning Keys, Primary Keys, and Unique Keys
- MySQL 8.4 Reference Manual: CREATE EVENT Statement
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。