ChaosBlade:把混沌工程从口号变成可回滚的实验
Posted on 一 27 4月 2026 in Tech
| Abstract | ChaosBlade:把混沌工程从口号变成可回滚的实验 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v1.0 |
| Updated | 2026-04-27 |
| License | CC-BY-NC-ND 4.0 |
ChaosBlade:把混沌工程从口号变成可回滚的实验
短大纲
- 混沌工程不是“上线前搞点破坏”,而是用实验验证系统的可靠性假设。
- ChaosBlade 把故障注入抽象成
target + action + flags,用 CLI、HTTP、Kubernetes CRD 等方式执行实验。 - 它覆盖主机、网络、磁盘、进程、容器、Kubernetes、JVM、C++ 等场景,适合从小半径的 Game Day 开始。
- 对服务可靠性的提升,最终体现在:告警更准、降级更真、恢复更快、团队更不慌。
正文
半夜两点,电话响了。
服务没全挂,只是“有点慢”。监控面板上 P99 像被人拿竹竿挑起来,缓存命中率往下掉,数据库连接池开始排队。值班同学一边查日志,一边在群里问:“这个依赖超时时会降级吧?”
最怕的不是系统出故障。最怕的是大家忽然发现,很多“应该可以”的东西从来没验证过。
- 超时真的生效吗?
- 重试会不会变成雪崩发动机?
- 限流是不是只写在设计文档里?
- Pod 被杀掉以后,流量会不会绕开?
- 磁盘满了,日志库会优雅失败,还是带着主业务一起跳楼?
混沌工程要解决的就是这些“我以为”。它不是拿锤子砸生产,也不是周五下午给团队加戏。它更像一次可控的体检:在医生、仪器、急救方案都在场的时候,让系统跑一小段坡,看看心肺到底行不行。
ChaosBlade 就是这类体检工具里很实用的一把刀。
混沌工程的核心:先有假设,再做破坏
Principles of Chaos Engineering 里有一句定义很经典:
Chaos Engineering is the discipline of experimenting on a system in order to build confidence in the system's capability to withstand turbulent conditions in production.
人话版:混沌工程是通过实验来建立信心,证明系统在真实风浪里还能扛住。
注意两个词:experiment 和 confidence。
混沌工程不是随机搞事,而是实验。实验就要有假设、有变量、有观测、有结论。否则就不是工程,是“祈雨舞”。跳得再投入,云也未必给面子。
一个像样的混沌实验,至少要走这几步:
- 定义稳态。比如 QPS、成功率、P95/P99 延迟、错误率、队列堆积、业务转化率。
- 写出假设。比如“当推荐服务延迟 2 秒时,下单链路成功率不下降超过 1%”。
- 缩小爆炸半径。先从测试环境、单实例、单租户、低峰期、小流量开始。
- 注入真实世界会发生的故障。比如网络延迟、CPU 打满、磁盘 IO 抖动、Pod 被删、依赖超时。
- 观察稳态是否被破坏。监控、日志、Trace、告警、用户体验都要看。
- 回滚并复盘。实验能销毁,影响能收敛,发现的问题要进入 backlog。
它和普通压测、故障演练最大的差别在于:混沌工程关心的是系统的行为,而不是工具的动作。工具能把 CPU 打满,只说明工具会打 CPU;系统在 CPU 打满时还能保护核心链路,才说明系统有韧性。
ChaosBlade 是什么
ChaosBlade 是阿里巴巴开源的混沌工程实验注入工具,官方介绍它源自阿里多年故障测试和演练实践,目标是帮助企业提升分布式系统容错能力和业务连续性。
官方文档里说,ChaosBlade 包含实验工具 chaosblade 和平台 chaosblade-box,支持 Linux、Docker、Kubernetes 等环境,也覆盖基础资源、容器、Pod、Node、Java、C++、NodeJS、Golang 等多类实验场景。这个覆盖面很关键:真实故障从来不按团队边界排队,它可能从网络开始,拐到 JVM,再把 Kubernetes 调度和数据库连接池一起拖下水。
ChaosBlade 的好处不在于命令多,而在于它把混沌实验抽象得比较规整:
blade create <target> <action> [flags]
也就是:
target:你要动谁,例如cpu、network、disk、jvm、docker、k8s。action:你要制造什么现象,例如load、delay、loss、fill、kill。flags:限定范围和强度,例如网卡、端口、延迟时间、命名空间、Pod 名、CPU 百分比。
这套模型的价值是:实验不是一句“把服务弄慢点”,而是一条可审查、可记录、可回滚的命令。
ChaosBlade 是如何工作的
从使用者视角看,ChaosBlade 有几个常用动作:
prepare:为某些实验做准备,比如给 Java 进程 attach agent。create:创建并执行实验。status:查看实验状态。destroy:销毁实验,恢复注入动作。revoke:撤销准备阶段,例如卸载 agent。server:启动 HTTP 服务,用 HTTP 方式触发实验。
README 里给过一个典型例子:对名为 business 的 Java 应用做 JVM 实验前,可以先执行准备动作:
blade p jvm --process business
创建实验时,ChaosBlade 会返回一个实验 uid。这个 uid 很重要,它相当于“你刚才捅的那一刀”的编号。后续查询和销毁都靠它:
blade status <uid>
blade destroy <uid>
如果你在主机上做 CPU 实验,可以从很小的半径开始:
blade create cpu load --cpu-percent 60
如果要模拟网络延迟,可以先查网卡,再对指定网卡注入延迟:
blade query network interface
blade create network delay --interface eth0 --time 3000
如果在 Kubernetes 场景下,ChaosBlade 也可以通过 chaosblade-operator 把实验映射成 Kubernetes 资源。这样做的好处是运维同学更容易用熟悉的 kubectl、CRD、RBAC、审计日志和 GitOps 流程来管理实验,而不是靠某个人手里的一堆临时命令。
它的整体工作方式可以粗略理解成这张图:
flowchart LR
H[可靠性假设] --> S[定义稳态指标]
S --> B[限制爆炸半径]
B --> C[ChaosBlade 创建实验]
C --> E[执行器注入故障]
E --> O[监控/日志/Trace 观察]
O --> R{稳态是否被破坏}
R -->|否| K[记录信心与边界]
R -->|是| F[修复系统弱点]
K --> D[destroy/revoke 回滚]
F --> D
D --> N[进入下一轮实验]

这里的“执行器”才是真正动手的人。不同场景会落到不同实现上:
- 基础资源实验由 OS 执行器处理,比如 CPU、内存、网络、磁盘、进程。
- Docker/CRI 实验通过容器运行时接口影响容器。
- JVM 实验通过 Java Agent 动态挂载,对方法调用、数据库、缓存、消息、微服务框架等场景注入延迟或异常。
- Kubernetes 实验由 operator 和 CRD 把实验纳入集群资源模型。
- C++ 场景则可借助 GDB 等机制做更底层的注入。
这也是 ChaosBlade 比“写几个 shell 脚本”更值得看一眼的地方。shell 脚本当然能杀进程、改 tc、填磁盘,但它很容易变成野路子:缺少统一模型、缺少状态、缺少销毁动作、缺少团队协作接口。混沌工程最怕“只会制造事故,不会管理实验”。
对服务可靠性有什么帮助
先泼一小盆冷水:ChaosBlade 不会自动让系统变可靠。
就像买了跑鞋不会自动减肥,顶多说明你离运动近了一步。真正改变系统可靠性的,是你用它反复验证假设、发现弱点、修掉缺口,然后再验证。
我认为它对服务可靠性的帮助主要体现在五个方面。
1. 把“降级可用”从口号变成证据
很多系统设计文档里都有降级、熔断、限流、隔离。写的时候都很漂亮,像样板间;真住进去才知道下水道会不会反味。
用 ChaosBlade 给某个依赖注入延迟或错误,你很快能看到:
- 调用方有没有设置合理超时;
- 重试次数是不是把下游打得更惨;
- fallback 是否真的返回了业务可接受的结果;
- 熔断器打开后有没有自动恢复;
- 降级告警是不是能被值班人员看见。
如果这些都通过,团队的信心不是“我觉得可以”,而是“我们在某年某月某日演练过,指标在阈值内”。
2. 提前发现级联故障
分布式系统最擅长表演连锁反应。
一个依赖慢了,调用方线程池被占满;线程池满了,接口超时;接口超时,客户端重试;重试增多,下游更慢;最后大家围着监控看烟花,唯一稳定的是群消息数量。
混沌实验能把这种链条提前暴露出来。比如:
- 给下游接口增加 3 秒延迟;
- 观察上游连接池、线程池、队列长度、错误率;
- 看网关、客户端 SDK、异步任务是否发生重试风暴;
- 验证限流和熔断是否把故障挡在局部。
很多时候,系统不是被第一个故障打倒的,而是被自己的补救措施打倒的。混沌工程最有价值的地方,就是帮我们发现这些“好心办坏事”的设计。
3. 让监控和告警接受现实教育
没被演练过的告警,经常有两种命运:
- 该响的时候不响;
- 不该响的时候吵得像装修队。
ChaosBlade 可以制造相对可控的故障,让监控系统接受一次现实教育。CPU 上升、网络延迟、磁盘满、Pod 删除、JVM 方法延迟,这些都可以对应到明确的观测项:
- SLI/SLO 是否能反映用户体验;
- 告警阈值是否太迟或太敏感;
- Trace 能不能定位到变慢的依赖;
- 日志有没有足够上下文;
- Dashboard 是否能让值班同学 3 分钟内找到方向。
可靠性不是“没有告警”,而是“告警能推动正确行动”。这句话听起来像废话,但很多团队真的会把告警数量下降当成可靠性提升。那是把体温计扔了,不是退烧。
4. 把 Runbook 练成肌肉记忆
Runbook 最大的问题,不是没人写,是没人练。
文档里写着“必要时切流”,可谁有权限?切哪里?切完怎么验证?如果切流失败,回滚命令是什么?这些问题平时不问,事故现场就会排队来问候你。
用 ChaosBlade 做 Game Day,可以把流程串起来:
- 实验负责人创建故障。
- 值班同学按真实流程接警。
- 服务 owner 判断影响和定级。
- 平台同学配合扩容、切流或隔离。
- 实验结束后销毁故障。
- 所有人复盘:工具问题、系统问题、流程问题、权限问题。
这件事的收益很朴素:下次真出事,大家不会第一次见面。
5. 帮团队建立可靠性语言
可靠性讨论最怕抽象。
“这个服务要高可用。”
听上去很正确,等于没说。高到什么程度?允许慢多少?哪些链路必须保,哪些可以降级?依赖不可用时是返回缓存、默认值,还是明确失败?
混沌实验逼着团队把这些话说清楚:
- 稳态指标是什么?
- 实验半径多大?
- 终止条件是什么?
- 失败算谁的问题?
- 修复以后怎么证明真的好了?
当团队开始用这些问题沟通,可靠性就从口号变成了工程语言。
一个可落地的 ChaosBlade 演练模板
如果你的团队还没做过混沌工程,不建议一上来就在生产集群里随机杀 Pod。那不是勇敢,是把消防演习办成烧烤大会。
可以从这个模板开始:
第一步:选一个小而真实的场景
别选“整个系统不可用”这种大题。先选一个具体问题:
- 推荐服务延迟 2 秒,下单是否受影响;
- 缓存不可用,核心查询是否自动降级;
- 某个非核心 Pod 被删除,流量是否自动恢复;
- 日志磁盘接近满,主业务是否受影响;
- 下游 5xx 增加,调用方是否触发熔断。
第二步:写实验卡片
每次实验前,写一张很短的卡片:
实验名称:推荐服务延迟演练
实验目标:验证下单链路在推荐服务慢响应时仍可用
稳态指标:下单成功率 >= 99%,P99 < 800ms
故障变量:推荐服务响应延迟 2000ms
实验范围:测试环境 / 单实例 / 10% 流量
终止条件:错误率 > 1% 或 P99 > 1500ms 持续 3 分钟
回滚方式:blade destroy <uid>
观察项:网关延迟、调用方线程池、推荐服务 QPS、下单错误码
负责人:实验 owner、服务 owner、值班 observer
这张卡片比长篇大论有用。因为事故现场没人有心情读文学作品,大家只想知道“现在该干嘛”。
第三步:先演练回滚
创建实验前,先确认销毁命令、权限和验证方法。
这一步听起来保守,其实很专业。混沌工程的第一能力不是注入故障,而是停止伤害。
blade status <uid>
blade destroy <uid>
如果是 JVM 预处理类实验,还要确认撤销准备动作:
blade revoke <uid>
第四步:执行实验,盯住稳态
实验过程中,不要只盯着 ChaosBlade 命令返回成功。那只能说明故障注入成功,不说明系统表现成功。
真正要看的,是稳态指标有没有偏离:
- 用户侧成功率;
- P95/P99 延迟;
- 错误码分布;
- 队列积压;
- 线程池和连接池;
- 下游流量变化;
- 告警是否按预期触发;
- Runbook 是否足够清楚。
第五步:复盘并形成修复项
复盘不要写成“本次演练圆满成功”。这句话很像年会主持词,热闹但没营养。
更好的复盘是:
- 哪个假设被证实了?
- 哪个假设被推翻了?
- 哪个指标看不见?
- 哪个告警太慢?
- 哪个恢复步骤没人有权限?
- 哪个配置需要改默认值?
- 下次实验要扩大还是缩小半径?
混沌工程的结果不应该只是一张报告,而应该是一串具体改动:代码、配置、告警、Runbook、权限、值班流程。
使用 ChaosBlade 的几个边界
工具越锋利,越要知道边界。
第一,不要把混沌实验当生产冒险。生产演练当然有价值,但必须建立在小半径、可回滚、可观测、有人值守的前提下。没有这些前提,就先在测试环境练。
第二,不要迷信“故障越大越高级”。高级的不是把系统打挂,而是用最小扰动发现最关键弱点。拳击训练也不是每天被泰森打一顿。
第三,不要只练基础设施,不练业务稳态。CPU、网络、磁盘只是手段,真正要保护的是业务结果。订单、会议、消息、支付、登录,这些才是用户感知到的系统。
第四,不要忘记权限和审计。谁能执行实验,谁能审批,谁能中止,命令是否记录,影响范围是否可追踪,这些都是混沌工程的一部分。
第五,不要把 ChaosBlade 变成“可靠性部门的玩具”。服务 owner、SRE、QA、平台、安全、值班团队都要参与。可靠性是系统属性,也是组织属性。
总结
ChaosBlade 给我们提供了一种很工程化的方式:把故障注入标准化,把实验过程可观测化,把恢复动作显式化。
但它真正的价值,不在于更会“制造故障”,而是逼团队把这些问题问清楚:
- 我们的稳态到底是什么?
- 哪个依赖失败会拖垮核心链路?
- 哪个降级策略只是写在 PPT 里?
- 哪个告警只能证明机器很忙,却不能说明用户很痛?
- 哪个 Runbook 第一次执行就会卡在权限上?
混沌工程不是为了证明系统不会坏。系统一定会坏。它是为了让系统在坏的时候,坏得可控、坏得局部、坏得可恢复。更理想一点,坏过一次以后,下一次就不再用同一种姿势摔倒。
明天就能做的 5 件事
- 选一个非核心链路,写一张 10 行以内的实验卡片。
- 用现有监控定义 2-3 个稳态指标,不要只看机器指标。
- 在测试环境跑一次最小半径实验,比如 CPU load 或网络 delay。
- 先验证
destroy/revoke,再验证故障注入。 - 把复盘结果落成具体改动,不要只留会议纪要。
思维导图
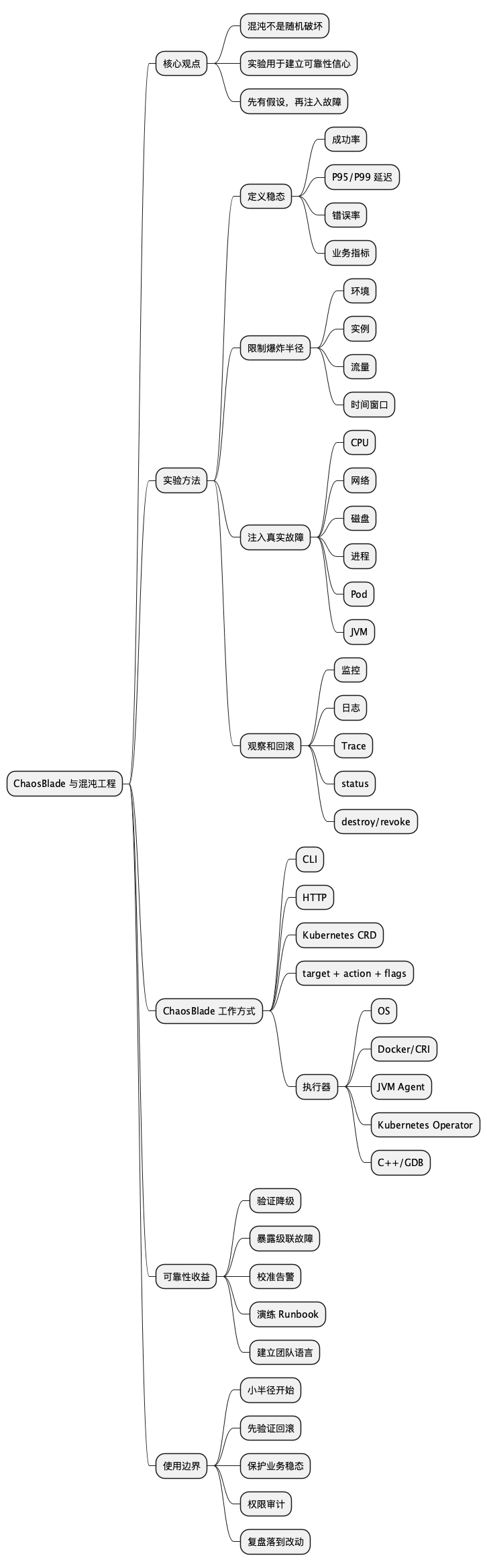
@startmindmap
* ChaosBlade 与混沌工程
** 核心观点
*** 混沌不是随机破坏
*** 实验用于建立可靠性信心
*** 先有假设,再注入故障
** 实验方法
*** 定义稳态
**** 成功率
**** P95/P99 延迟
**** 错误率
**** 业务指标
*** 限制爆炸半径
**** 环境
**** 实例
**** 流量
**** 时间窗口
*** 注入真实故障
**** CPU
**** 网络
**** 磁盘
**** 进程
**** Pod
**** JVM
*** 观察和回滚
**** 监控
**** 日志
**** Trace
**** status
**** destroy/revoke
** ChaosBlade 工作方式
*** CLI
*** HTTP
*** Kubernetes CRD
*** target + action + flags
*** 执行器
**** OS
**** Docker/CRI
**** JVM Agent
**** Kubernetes Operator
**** C++/GDB
** 可靠性收益
*** 验证降级
*** 暴露级联故障
*** 校准告警
*** 演练 Runbook
*** 建立团队语言
** 使用边界
*** 小半径开始
*** 先验证回滚
*** 保护业务稳态
*** 权限审计
*** 复盘落到改动
@endmindmap
扩展阅读
- ChaosBlade GitHub Repository
- ChaosBlade 官方文档
- Principles of Chaos Engineering
- chaosblade-operator
- chaosblade-exec-jvm
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。