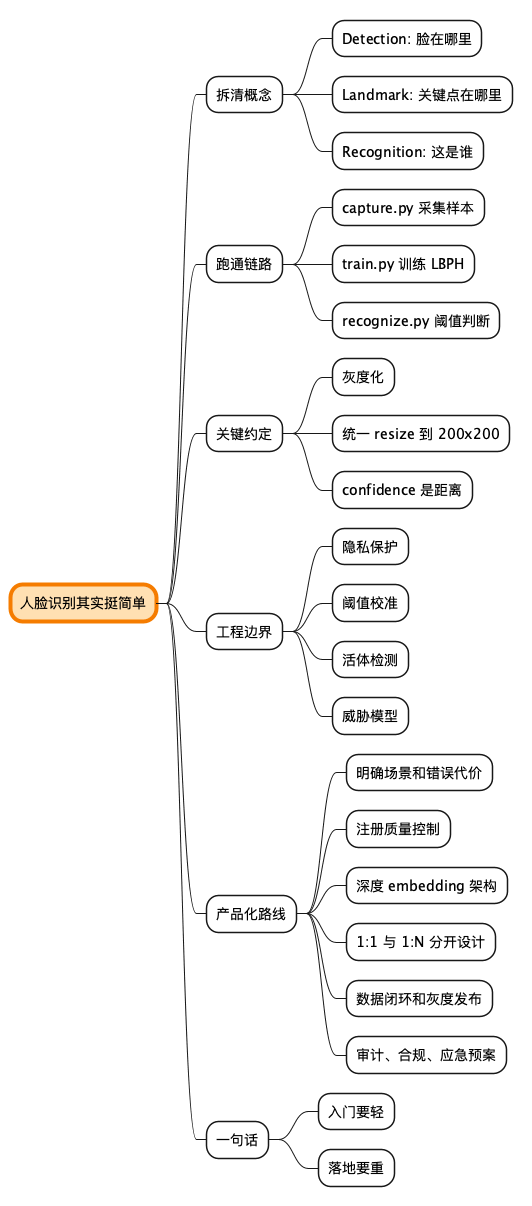
人脸识别其实挺简单:从一张脸到一个名字
Posted on 六 27 6月 2026 in Tech
| Abstract | 人脸识别其实挺简单:从一张脸到一个名字 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v1.0 |
| Updated | 2026-06-28 |
| Source | github.com/walterfan/face-detection-demo |
| License | CC-BY-NC-ND 4.0 |
别被“人脸识别”四个字吓住
一说起人脸识别,很多人脑子里先跳出来的画面,不是机场安检,就是刷脸支付,再不然就是电影里黑客敲几下键盘,全城摄像头一起点亮。听起来很高级,像是得先念三年博士,再买一张显卡祭天。
可我最近写了一个小 demo,跑下来之后的感觉是:人脸识别入门并不神秘,真正难的是把它做可靠、做安全、做可控。 这话有点像说“写个 HTTP server 很简单,做一个高可用网关很难”。两句话都对,只是层次不同。
这个 demo 的源码已经放在 GitHub:walterfan/face-detection-demo。它用的是几件朴素工具:OpenCV 做人脸检测和 LBPH 识别,MediaPipe 做面部关键点,Poetry 管依赖。没有深度模型训练,没有云服务,也没有几十页论文。目的无他,先把链路跑通。
咱们先把大词拆开。检测回答“脸在哪里”,关键点回答“眼睛、鼻子、嘴大概在哪些位置”,识别才回答“这是谁”。很多文章把这三个词揉成一团,越讲越玄。其实工程里最怕的就是词没分清,词一混,设计就像一锅没撇沫的汤。
1. 整条链路只有四步
这个 demo 的主流程可以写成一行:
输入图片/摄像头 -> 检测人脸框 -> 裁剪灰度人脸 -> LBPH 比对 -> 输出名字和距离
换成脚本,就是这几个文件各司其职:
| 脚本 | 作用 | 你可以把它理解成 |
|---|---|---|
detect.py |
Haar 级联检测人脸框 | 先在人群里圈出“疑似人脸” |
landmarks.py |
MediaPipe Face Mesh 画 468 个关键点 | 给脸贴一张网格地图 |
capture.py |
采集灰度人脸样本 | 给每个人建一个小相册 |
train.py |
训练 LBPH 模型 | 把相册整理成可查询索引 |
recognize.py |
加载模型并识别 | 拿新脸去相册里找最像的 |
verify_olivetti.py |
用公开数据集做 sanity check | 不开摄像头也能验链路 |
这里有个小设计我很喜欢:common.py 把输入源统一了。图片、视频、摄像头,在上层脚本看来都是一帧一帧的 frame。这就是典型的工程小技巧,谈不上惊天动地,但能让代码少很多分叉。
def iter_frames(source: str):
if is_image_path(source):
frame = cv2.imread(source)
yield frame
return
cap = cv2.VideoCapture(_resolve_source(source))
try:
while True:
ok, frame = cap.read()
if not ok:
break
yield frame
finally:
cap.release()
从这个角度看,人脸识别的第一个“简单”,不是算法简单,而是流程可以被拆得很清楚。先把输入统一,再把检测、采样、训练、识别分开。代码不装深沉,读的人也少掉几根白头发。咱年纪大了,白头发已经够多,不必让 demo 再雪上加霜。
2. Haar:先把脸框出来
detect.py 用的是 OpenCV 自带的 Haar cascade,也就是经典的 Viola-Jones 思路。它的任务很单纯:在一张图里滑动窗口,看看哪个区域像人脸,然后返回 (x, y, w, h)。
在代码里,它大概长这样:
gray = cv2.cvtColor(frame, cv2.COLOR_BGR2GRAY)
gray = cv2.equalizeHist(gray)
faces = cascade.detectMultiScale(
gray,
scaleFactor=1.1,
minNeighbors=5,
minSize=(60, 60),
)
这里有三个关键词。
灰度化。检测人脸不一定需要颜色,灰度图计算更快,也更稳定。很多时候,算法并不需要知道你今天穿了红衣服还是蓝衣服,它只想看明暗结构。
直方图均衡。equalizeHist 用来改善对比度,弱光、背光时能帮一点忙。别指望它救回所有烂光线,它不是魔法,只是给图像擦擦眼镜。
多尺度检测。人离摄像头有远有近,脸有大有小,所以检测窗口要按比例缩放。scaleFactor=1.1 的意思就是每次缩放一点点,慢一些,但细一点。
Haar 的好处是轻、快、离线,教学演示很合适。它的问题也明显:侧脸、大角度、遮挡、光线差,它就容易犯迷糊。就像老保安认人,正脸来了基本没问题,帽子口罩墨镜一戴,就开始“你是哪位”。
3. MediaPipe:给脸画一张网
landmarks.py 不参与训练和识别主链路,它更像一个可视化工具。它用 MediaPipe Face Mesh 在脸上画 468 个 3D 关键点,再用 FACEMESH_TESSELATION 和 FACEMESH_CONTOURS 连成网。
运行一下:
poetry run python landmarks.py --source 0
poetry run python landmarks.py --source face.jpg --save mesh.jpg
你会看到脸上像戴了一张细密的“面具”。这东西很适合给初学者建立直觉:计算机看到的人脸,不是“这个人很亲切”这种抽象评价,而是一堆点、一堆边、一堆坐标。
传统 dlib 常讲 68 个关键点,MediaPipe Face Mesh 则是 468 个点,还带一点深度信息。点更多,能表达的局部结构也更细。比如眼睛轮廓、嘴唇边界、脸颊曲线,都能画得更像样。
不过在这个 demo 里,关键点不是识别身份的核心。真正负责“这是谁”的,是后面的 LBPH。Face Mesh 在这里更多是帮你看明白:所谓人脸特征,可以被拆成可计算的几何结构。听起来玄,画出来就朴素了。
4. LBPH:小样本识别的老手艺
train.py 和 recognize.py 用的是 OpenCV 的 cv2.face.LBPHFaceRecognizer_create()。这玩意儿藏在 opencv-contrib-python 里,不在普通的 opencv-python 里。安装时如果两个包混装,cv2.face 可能直接消失,排查起来像找袜子,明明昨晚还在,早上就没了。
LBPH 全名是 Local Binary Patterns Histograms。名字有点长,其实思路不复杂:
- 对每个像素,看它周围 8 个邻居比它亮还是暗;
- 亮记 1,暗记 0,拼成一个 8 位二进制数;
- 把整张脸分成很多小格子,每个格子统计这些数的直方图;
- 识别时,把新脸的直方图和训练样本做距离比较。
所以 LBPH 看的不是“这人长得像谁”,而是“这张灰度脸的局部纹理分布,和训练库里哪一类更接近”。它是老手艺,不炫,但对小样本、本地 demo、教学场景很友好。
采样时,capture.py 会做三件要紧的事:
x, y, w, h = max(faces, key=lambda b: b[2] * b[3])
face = cv2.resize(gray[y:y + h, x:x + w], (200, 200))
cv2.imwrite(path, face)
只取最大的脸,是为了避免把旁边路过的人也收进你的样本。裁剪成灰度,是为了和 LBPH 的输入习惯一致。统一缩放到 200x200,是为了保证训练和识别时特征维度一致。
这就是第二个“简单”:同一种预处理,贯穿采集、训练、识别。 很多机器学习问题不是输给模型,而是输给前处理不一致。训练时一套尺寸,预测时另一套尺寸;训练时做了灰度化,预测时忘了做。结果模型背锅,代码偷笑。
5. 跑起来其实就几条命令
这个项目用 Poetry 管依赖,Python 版本限定在 3.11 到 3.12。原因很现实:MediaPipe wheel 对 Python 版本有约束,verify 额外依赖的 scikit-learn 也有自己的下限。
先把源码拉下来:
git clone https://github.com/walterfan/face-detection-demo.git
cd face-detection-demo
安装依赖:
poetry install
如果要跑公开数据集验证,再装 extra:
poetry install --extras verify
看人脸检测:
poetry run python detect.py --source 0
poetry run python detect.py --source face.jpg --save out.jpg
采集两个人的数据:
poetry run python capture.py --username walter --label 1 --count 30
poetry run python capture.py --username fiona --label 2 --count 30
数据会保存成类似这样的目录:
dataset/
├── 1_walter/
│ ├── 000.png
│ ├── 001.png
│ └── ...
├── 2_fiona/
│ ├── 000.png
│ └── ...
└── labels.json
训练模型:
poetry run python train.py
训练后会生成:
model/lbph.yml
model/labels.json
识别:
poetry run python recognize.py --source 0
poetry run python recognize.py --source group.jpg --threshold 70
这里的 threshold 很关键。LBPH 返回的 confidence 不是“百分之多少可信”,而是一个距离,数值越小越像。70 不是宇宙真理,只是一个默认起点。你的摄像头、光线、样本数量、采样角度一变,这个阈值就要重新调。
如果不想拿自己的脸做实验,可以跑公开的 Olivetti/ORL 数据集:
poetry run python verify_olivetti.py --train-per-person 8
它会用 40 个人、每人 10 张的灰度人脸做训练和测试。这个脚本的价值不在于证明算法多厉害,而是证明你的 OpenCV contrib、LBPH、数据拆分、训练预测链路是通的。
6. 简单不等于可以乱用
讲到这里,可能有人会想:既然几条命令就能跑起来,那是不是可以拿它做门禁、考勤、支付验证?
先别急。能跑通 demo,和能扛真实世界,是两回事。就像你在本地起了个 Flask 服务,不代表它已经具备全球流量调度能力。做人脸识别,最容易踩的坑有五个。
坑一:检测和识别不是一回事
画面里有脸,不代表知道是谁。检测错了,后面识别也会错。检测框偏一点,裁剪出来的脸少半边,LBPH 的距离就会飘。
坑二:样本太少,模型会“认亲”
每个人只采几张正脸,光线还都一样,demo 里看着挺准。换个角度、换个灯、换个表情,结果可能马上变脸。训练样本要覆盖真实场景,否则模型只是记住了“你在书房台灯下的样子”。
坑三:confidence 不是信心,是距离
这个名字很容易误导人。很多人一看 confidence,就以为越大越好。LBPH 正好反过来,越小越像。阈值设太松,陌生人容易混进来;设太严,自己也可能被拒之门外。
坑四:人脸是隐私数据
dataset/ 里存的不是普通图片,而是生物特征样本。哪怕只是灰度小图,也不能随手丢到公开仓库里。教学 demo 可以放空目录和说明,真实采样数据要加访问控制、加密存储、明确删除策略。
坑五:活体检测和防伪不在这个 demo 里
拿一张照片、一段视频,甚至一张屏幕怼到摄像头前,教学级系统可能并不知道。这不是它“笨”,而是它本来就没做活体检测、攻击检测、风控策略。别把小刀当保险柜。
7. 如果真要做成产品,该怎么走
这个 demo 适合入门。如果要把它做成一个可实际应用的人脸识别产品,第一步不是换模型,而是先把问题问清楚:它到底在什么场景里,替谁做什么决定,错了会怎样?
人脸识别产品大致有三类场景,难度完全不同:
| 场景 | 目标 | 错误代价 | 产品要求 |
|---|---|---|---|
| 相册归类 | 给照片自动打人名 | 标错了可以手动改 | 体验优先,安全压力小 |
| 考勤/门禁 | 判断当前人是不是本人 | 误放、误拒都会影响业务 | 稳定、可审计、可申诉 |
| 支付/政务/金融 | 用脸参与高风险身份确认 | 可能造成资金或身份损失 | 安全、合规、风控缺一不可 |
所以不要一上来就问“准确率能到多少”。更应该先问:我能接受多少误识别,能接受多少拒识别,出了错有没有补救流程? 做产品不是刷榜,刷榜只管分数,产品要管后果。
第一步:先把威胁模型写出来
Demo 只面对一种“友善用户”:摄像头前的人愿意配合你,光线也不太捣乱。产品面对的是现实世界,现实世界从来不按剧本演。
最少要回答这些问题:
| 问题 | 要想清楚的点 |
|---|---|
| 谁会攻击系统 | 普通误用者、冒名者、内部人员、专业攻击者 |
| 攻击者有什么材料 | 照片、视频、3D 面具、被盗账号、内部接口权限 |
| 系统保护什么资产 | 门禁权限、考勤记录、账号登录、支付动作、身份信息 |
| 哪些链路最脆弱 | 注册、采集、模型存储、识别接口、日志、人工审核 |
| 失败后怎么补救 | 二次验证、人工复核、冻结账号、撤销授权、告警追踪 |
没有威胁模型,产品就会变成“看起来能用”。而安全系统最怕的就是“看起来”。就像门口放了个保安,但保安只认正脸照片,别人拿手机屏幕晃一下也放行,那还不如老老实实写个“请自觉登记”。
第二步:把算法链路升级成可替换架构
Demo 里用 Haar + LBPH 没问题,它们轻、快、好理解。产品里通常要拆成几个独立模块,便于替换和评估:
图像输入
-> 质量检测
-> 人脸检测
-> 人脸对齐
-> 活体检测
-> 特征提取 embedding
-> 特征库检索或 1:1 比对
-> 阈值策略
-> 风险决策
-> 审计记录
这里有几个 demo 里没有、产品里绕不开的环节。
质量检测。图像太暗、太糊、脸太小、遮挡太多、角度太偏,都应该在前面拦掉。不要把垃圾输入硬塞给模型,再抱怨模型不准。输入质量不过关,就提示用户调整姿态和光线。
人脸对齐。检测框只是框出脸,人脸还要按眼睛、鼻子、嘴的位置做旋转和裁剪。否则同一个人,头歪一点,特征就可能变形。MediaPipe 或别的 landmark 模型,在这里就能派上用场。
特征提取。产品级识别一般不会用 LBPH 这种纹理直方图,而会用深度模型把人脸转成 embedding,比如 128 维、512 维的向量。后面做的不是“图片比图片”,而是“向量比向量”。常见路线是 FaceNet、ArcFace、MagFace 这类模型思路,具体选型要看许可证、性能、部署环境和数据表现。
阈值策略。不要全系统一个阈值走天下。不同摄像头、不同场景、不同风险级别,可以有不同阈值。比如相册归类可以松一点,门禁要严一点,支付则不能只靠脸,必须叠加其他认证因素。
第三步:把“注册”当成产品核心,而不是附属页面
很多人做人脸识别,只盯着识别接口。其实注册采集才是根。注册时样本质量差,后面模型再好也难救。
一个可用的注册流程,至少应该包含:
| 注册环节 | 产品要求 |
|---|---|
| 明确告知 | 告诉用户采集什么、用途是什么、保留多久、如何删除 |
| 用户同意 | 获取明确授权,不要用默认勾选糊弄人 |
| 多姿态采集 | 正脸、轻微左转、轻微右转、不同表情,覆盖真实使用场景 |
| 质量门槛 | 模糊、逆光、遮挡、多人入镜时拒收 |
| 活体校验 | 注册时就防照片和视频注入 |
| 重复身份检查 | 防止同一张脸注册多个身份,或多人共用一个身份 |
| 可撤销机制 | 用户能删除样本,系统能同步删除 embedding 和缓存 |
这里有个老手提醒:注册质量比识别算法更像地基。 地基歪了,楼上装修再漂亮也没用。很多系统上线后识别不稳,不是模型选错了,而是注册时什么照片都收,最后特征库像一间没人整理的仓库。
第四步:活体检测不能省
Demo 里摄像头看到一张脸就识别,产品里这不够。你要判断摄像头前是一个真实的人,而不是照片、视频、屏幕翻拍或面具。
活体检测大致有两类:
| 类型 | 做法 | 优缺点 |
|---|---|---|
| 配合式活体 | 眨眼、摇头、读随机数字、按提示转头 | 容易理解,但打扰用户,体验较重 |
| 静默式活体 | 通过纹理、反光、深度、红外、多帧变化判断 | 体验好,但模型和硬件要求更高 |
实际产品常常两者结合。低风险场景用静默式,风险升高时触发配合式。比如日常考勤可以轻一点,异地登录、设备异常、连续失败时再要求用户做动作。
不过别把活体检测神化。它不是护身符,只是提高攻击成本。专业攻击者总会进化,所以活体检测要和设备指纹、账号风险、地理位置、行为历史一起看。安全不是一招鲜,是多道门。
第五步:明确是 1:1 还是 1:N
这两个词看起来只差一个字母,工程复杂度差很多。
| 模式 | 问题 | 例子 | 难点 |
|---|---|---|---|
| 1:1 验证 | 你是不是你声称的那个人 | 登录、支付、员工打卡 | 阈值、活体、防冒用 |
| 1:N 识别 | 你是谁 | 相册归类、黑名单检索 | 大规模检索、误识别、性能和合规 |
Demo 里的 recognize.py 更接近小规模识别,但产品上如果做身份确认,很多时候应该走 1:1:用户先声明身份,比如账号、工号、手机号,然后系统拿当前人脸和该账号绑定的人脸特征比对。
1:N 更敏感。库越大,误命中的概率越高,性能压力也越大。你需要向量索引、分库分区、候选集召回、二次排序,还要处理“长得像的人”“双胞胎”“同一人年龄变化”这些现实问题。别轻易把 1:N 用在高风险决策里,除非你有足够的业务理由和防错流程。
第六步:用数据闭环校准阈值,而不是拍脑袋
产品级系统必须关心两类错误:
| 指标 | 含义 | 业务影响 |
|---|---|---|
| FAR / FMR | 把别人错认成本人 | 安全风险 |
| FRR / FNMR | 把本人拒绝掉 | 体验和业务中断 |
阈值越松,用户越容易通过,但冒用风险上升。阈值越严,安全性提高,但本人也可能被拒。这里没有免费午餐,只能按业务风险做取舍。
更靠谱的做法是准备独立测试集:
注册集:用于建库
验证集:用于调阈值
测试集:用于最终评估
灰度集:用于上线后观察真实表现
测试集要覆盖不同光线、不同设备、不同年龄段、戴眼镜、换发型、轻微遮挡、多人背景等场景。不要只拿办公室同事在同一盏灯下拍的照片测,那种准确率容易让人误判,就像拿自己出的题考自己,分数当然漂亮。
第七步:把人脸数据当敏感资产管
产品级应用里,人脸原图、裁剪图、embedding、标签映射、识别日志,都属于高敏数据。即使 embedding 不是原图,也不能当普通字符串随便存。它仍然能代表一个人的生物特征。
基本要求包括:
| 数据环节 | 要求 |
|---|---|
| 采集 | 明确用途,最小化采集,不要顺手多拿数据 |
| 传输 | 全链路 TLS,移动端防中间人攻击 |
| 存储 | 加密存储,密钥分离管理,按租户或业务隔离 |
| 访问 | 最小权限,管理员也不能随便看原图 |
| 日志 | 不记录原始图片,不把 embedding 打进普通日志 |
| 删除 | 用户撤销后可删除、可验证删除完成 |
| 留存 | 到期清理,不要无限期保存 |
还有一点容易被忽略:开发和测试环境不要使用生产人脸数据。真要排查问题,也应该用脱敏样本、合成样本或经过授权的测试集。否则哪天日志、备份、对象存储桶漏出去,事故报告会写得很难看。
第八步:产品体验要兜住失败
真实用户不会按算法工程师的理想姿势站在镜头前。他可能在地铁口,脸上有汗,背后有强光,手机摄像头还贴了膜。识别失败时,产品不能只甩一句 “failed”。
好的体验应该告诉用户怎么修正:
| 失败原因 | 用户提示 |
|---|---|
| 光线太暗 | 请移动到光线更好的地方 |
| 脸太小 | 请靠近摄像头 |
| 多人入镜 | 请确保画面中只有本人 |
| 遮挡严重 | 请摘下口罩或移开遮挡物,若业务允许 |
| 连续失败 | 切换到短信、硬件 key、人工审核等备用流程 |
产品级系统一定要有 fallback。人脸识别不该是唯一入口,更不该是唯一出口。尤其在金融、医疗、企业权限这类场景里,用户被误拒以后要有申诉和人工处理流程。技术再好,也别把人关在系统外面干着急。
第九步:后端服务要按“身份系统”设计
Demo 是本地脚本,产品通常会变成服务。服务化之后,复杂度立刻上来:认证、授权、限流、审计、模型版本、特征库、缓存、告警,一个都跑不掉。
一个相对稳妥的后端拆法是:
| 服务/模块 | 职责 |
|---|---|
| Enrollment Service | 注册、样本质量检查、用户授权记录 |
| Face Feature Service | 人脸检测、对齐、embedding 提取 |
| Matching Service | 1:1 比对或 1:N 检索 |
| Risk Engine | 阈值策略、设备风险、行为风险、二次验证决策 |
| Audit Service | 记录谁在什么时间因为什么结果通过或失败 |
| Admin Console | 特征重建、账号冻结、申诉处理、指标查看 |
接口也要小心。不要设计一个“传照片,返回用户是谁”的万能接口,然后让所有业务随便调。每个调用方都要有身份、权限、用途、速率限制和审计记录。否则人脸识别服务很容易变成内部“查人接口”,这在合规上很危险。
第十步:上线前要有验收门槛
产品不是“代码能跑”就上线。至少要过几道门:
| 验收项 | 要看什么 |
|---|---|
| 算法评估 | FAR、FRR、ROC 曲线、不同人群和设备的表现 |
| 安全测试 | 照片、视频、屏幕翻拍、接口重放、越权调用 |
| 隐私评审 | 数据用途、授权、存储、删除、跨境和第三方处理 |
| 压力测试 | 峰值 QPS、延迟、GPU/CPU 利用率、降级策略 |
| 可观测性 | 成功率、失败原因、活体失败率、异常流量告警 |
| 灰度发布 | 小范围试点、人工复核、误判回收、阈值调整 |
| 应急预案 | 模型回滚、特征库恢复、密钥轮换、数据泄漏响应 |
我会特别强调灰度发布。人脸识别这种系统,实验室里再漂亮,也要到真实场景里走一圈。不同门口的光线、不同手机的摄像头、不同用户的使用习惯,都会给你上课。上线前少听口号,多看失败样本。
一张产品化路线图
如果把上面这些压成阶段,我会这样排:
| 阶段 | 目标 | 交付物 |
|---|---|---|
| PoC | 证明链路可行 | demo、公开数据集验证、初步误差分析 |
| MVP | 面向一个低风险场景试用 | 注册流程、1:1 比对、基础活体、人工兜底 |
| Pilot | 小范围真实用户灰度 | 指标看板、告警、申诉流程、阈值校准报告 |
| Production | 正式承载业务 | 合规评审、安全测试、SLA、审计、灾备和回滚 |
| Continuous Improvement | 持续优化 | 数据闭环、模型版本管理、漂移监控、定期复评 |
这里最重要的不是换成多高级的模型,而是先问清楚:这个识别结果要拿来做什么决策? 如果只是课堂演示,LBPH 足够。如果是家庭相册自动分类,误判了也就是多点一下鼠标。如果是开门、扣钱、放行,那就进入安全系统范畴,要求完全不同。
工程里有句老话,叫“先定义失败”。人脸识别也一样。你得先想清楚:认错一个人,代价是什么?认不出本人,代价是什么?系统被照片骗过,代价是什么?这些问题答不清,模型准确率写到 99% 也只是好看。
8. 给初学者的一张路线图
如果你也想从零开始练,我建议不要一上来就冲 ArcFace、向量数据库、GPU 推理服务。先用这种小 demo 把概念摸一遍:
第 1 天:跑 detect.py,看懂 Haar 检测框
第 2 天:跑 landmarks.py,看懂关键点和网格
第 3 天:用 capture.py 采 2 个人,每人 30 张
第 4 天:跑 train.py,生成 lbph.yml
第 5 天:跑 recognize.py,调 threshold
第 6 天:换光线、换角度、戴眼镜,记录失败案例
第 7 天:写一页总结,列出哪些场景不能用
注意,第 6 天最值钱。成功案例让你开心,失败案例让你长本事。很多工程经验就是这么来的:不是把 demo 跑绿,而是把它故意跑坏,再看它坏在哪里。
咱们学技术,最怕两种状态。一种是被名词吓住,觉得“这个我不配碰”;另一种是跑通一次,就觉得“这个我已经会了”。前者让人不敢开始,后者让人开始乱来。比较靠谱的路,是先承认它可以入门,再尊重它的边界。
小结:入门要轻,落地要重
人脸识别其实挺简单。至少,做一个能演示“从摄像头采集样本、训练 LBPH、识别出名字”的本地 demo,并不需要多神秘的装备。
可是,把它做成可信身份系统,就不简单了。你要处理数据隐私、样本偏差、阈值校准、攻击防护、活体检测、审计追踪,还要回答“认错了谁负责”这种不那么技术、却更要命的问题。
最后留一张 CheckList,给自己也给读者:
- 我是否分清了 detection、landmark、recognition?
- 采集、训练、识别是否使用同样的灰度化和尺寸?
opencv-contrib-python是否正确安装,且没有和opencv-python打架?confidence是否按“距离越小越像”理解?- 阈值是否用自己的数据校准过,而不是照抄默认值?
- 数据集里的人脸样本是否有隐私保护?
- 是否明确说明:这是教学 demo,不是门禁、支付或风控系统?
- 如果要产品化,是否已经写清威胁模型和失败补救流程?
- 注册采集、活体检测、1:1/1:N 模式、审计日志是否都有设计?
- 是否准备了独立测试集、灰度指标、模型回滚和数据删除机制?
一句话:入门时,把它当小练习;上线前,把它当安全系统。 图难于其易,为大于其细,技术也差不多是这个理。
@startmindmap
<style>
node {
BackgroundColor White
}
rootNode {
BackgroundColor #ffe0b2
LineColor #f57c00
LineThickness 4
}
</style>
* 人脸识别其实挺简单
** 拆清概念
*** Detection: 脸在哪里
*** Landmark: 关键点在哪里
*** Recognition: 这是谁
** 跑通链路
*** capture.py 采集样本
*** train.py 训练 LBPH
*** recognize.py 阈值判断
** 关键约定
*** 灰度化
*** 统一 resize 到 200x200
*** confidence 是距离
** 工程边界
*** 隐私保护
*** 阈值校准
*** 活体检测
*** 威胁模型
** 产品化路线
*** 明确场景和错误代价
*** 注册质量控制
*** 深度 embedding 架构
*** 1:1 与 1:N 分开设计
*** 数据闭环和灰度发布
*** 审计、合规、应急预案
** 一句话
*** 入门要轻
*** 落地要重
@endmindmap