Python 动态语言里的安全带:Pydantic 用法与最佳实践
Posted on 五 05 6月 2026 in Tech
| Abstract | Python 动态语言里的安全带:Pydantic 用法与最佳实践 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v1.0 |
| Updated | 2026-06-05 |
| License | CC-BY-NC-ND 4.0 |
Python 的错误,很多不是写出来的,是“放进来”的
写 Python 后端,最舒服的地方是快。一个接口、一个脚本、一个小工具,半天就能跑起来。最不舒服的地方也是快:数据从 HTTP、MQ、配置文件、数据库、LLM 输出里进来,类型不对、字段缺失、枚举写错、时间格式混乱,代码照样一路往下跑。
等它炸的时候,往往已经离入口很远了。NoneType has no attribute ...,KeyError,TypeError,日志里像案发现场,调试的人像刑侦队员。
我的观点很简单:Python 不是不能写可靠系统,但动态语言必须把“边界验证”当成一等公民。Pydantic 就是这条安全带。
不过安全带也有系法。Pydantic 用得好,是契约;用得差,是另一层幻觉。本文不准备把官方文档压缩一遍,而是从工程实践角度聊:哪些地方该用、怎么用、怎么少踩坑。
本文默认讨论 Pydantic v2。如果你还在 v1 项目里维护老代码,要特别注意 API 名称和行为差异,后面会单独说。
一、Pydantic 到底解决什么问题
一句话:把不可信输入,变成经过类型约束和业务约束检查的 Python 对象。
Pydantic 的核心对象是 BaseModel:
from pydantic import BaseModel, Field
class CreateUserRequest(BaseModel):
email: str
display_name: str = Field(min_length=1, max_length=64)
age: int | None = Field(default=None, ge=0, le=150)
它看起来像 dataclass,但目标不一样。
dataclass 更像“给内部对象省点样板代码”;Pydantic 更像“在系统边界立一块牌子:进门先验票”。
典型使用场景:
| 场景 | 不用 Pydantic 的风险 | 用 Pydantic 的价值 |
|---|---|---|
| HTTP request body | 字段缺失、类型漂移、错误散落在业务代码里 | 入口统一失败,错误结构清楚 |
| MQ message | 老版本消息和新版本消息混在一起 | 明确 schema,便于兼容演进 |
| 配置和环境变量 | 字符串被误当数字、布尔值解析混乱 | 启动时失败,比运行中失败便宜 |
| LLM structured output | JSON 看起来像 JSON,字段却不可信 | 输出先验收,再进入业务流程 |
| 数据库/外部 API 返回 | 上游改字段,下游静默出错 | 及时发现契约破坏 |
不要误会:Pydantic 不能替你设计业务模型,也不能证明业务逻辑正确。它解决的是“输入能不能被安全理解”。
二、Pydantic 与静态代码检查:一个查代码,一个验数据
很多人第一次接触 Pydantic,会把它和 mypy、pyright、ruff、pylint 混在一起。都是“让 Python 少犯错”的工具,名字又都长得像开源项目,确实容易串台。
但它们看的东西完全不同。
| 工具类型 | 代表工具 | 主要看什么 | 能发现什么 | 看不到什么 |
|---|---|---|---|---|
| Linter | ruff, pylint |
源代码文本和语法结构 | 未使用变量、危险写法、风格问题、部分简单 bug | 真实运行时输入 |
| Static type checker | mypy, pyright |
类型标注和类型推导 | 函数参数类型不匹配、返回值类型不对、Optional 没处理 |
HTTP body、MQ message、环境变量到底传了什么 |
| Runtime validation | Pydantic | 程序运行时收到的数据 | 字段缺失、类型转换失败、范围越界、跨字段约束失败 | 还没执行到的代码路径、整体业务逻辑正确性 |
举个很常见的例子:
import json
def charge(amount: int) -> None:
...
payload = json.loads('{"amount": "100"}')
charge(payload["amount"])
这段代码里,charge() 明明要的是 int,但 JSON 里来的 "100" 是字符串。静态检查工具未必能拦住,因为 json.loads() 出来的东西常常是 Any 或很宽的类型。它不知道生产环境某个客户会不会传 "100"、100、"one hundred",甚至传个空对象。
Pydantic 管的就是这道门:
from pydantic import BaseModel, Field
class ChargeRequest(BaseModel):
amount: int = Field(strict=True, gt=0)
req = ChargeRequest.model_validate(payload)
charge(req.amount)
从 model_validate() 之后,req.amount 才是你愿意相信的 int。这时静态检查也有价值:它能继续检查你后面的业务代码有没有把 req.amount 当成字符串用。
反过来,静态检查也能发现 Pydantic 管不到的问题:
def charge(amount: int) -> None:
...
charge("100") # mypy/pyright 可以在代码提交前提醒你
这行代码如果写死在源码里,没必要等运行时再炸。静态检查在提交前、CI 阶段就能拦住,成本更低。
所以不要问“我用了 Pydantic,还要不要 mypy/pyright?”这就像问“我装了安全带,还要不要刹车?”答案当然是都要,只是负责的速度区间不一样。
我的推荐分工:
| 问题 | 优先工具 |
|---|---|
代码里把 str 传给需要 int 的函数 |
mypy / pyright |
某个变量可能是 None,却直接访问属性 |
mypy / pyright |
| import 顺序、未使用变量、复杂度过高 | ruff / pylint |
| HTTP request body 字段缺失 | Pydantic |
| 环境变量字符串要转成布尔值或整数 | Pydantic Settings |
| 第三方 webhook 多传了未知字段 | Pydantic |
| 金额必须大于 0,结束时间必须晚于开始时间 | Pydantic validator |
| 这段业务流程到底对不对 | 单元测试 / 集成测试 / contract test |
一句话:静态检查负责“代码看起来是否自洽”,Pydantic 负责“世界塞进来的数据是否可信”。
这两个工具配合起来,Python 项目才比较像一辆能上高速的车:方向盘、刹车、安全带都在,不靠驾驶员临场发挥求平安。
怎么造一个“类似编译阶段”
Python 没有 Java、Go、Rust 那种天然的编译闸门,但我们可以自己造一个。思路很朴素:把静态类型检查、lint、测试放进同一个必经流程,提交前跑一遍,CI 再跑一遍,失败就不让合并。
先从类型标注开始。不要满足于 dict、list、Any 满天飞。类型越含糊,静态检查越像近视眼。
from typing import TypedDict
class ChargePayload(TypedDict):
amount: int
currency: str
def charge(payload: ChargePayload) -> None:
amount: int = payload["amount"]
如果有人这样调用:
charge({"amount": "100", "currency": "USD"})
mypy 或 pyright 就有机会在提交前指出:amount 需要 int,你传了 str。
再给项目加一个偏严格的配置。以 pyproject.toml 为例:
[tool.mypy]
python_version = "3.12"
warn_return_any = true
warn_unused_ignores = true
disallow_untyped_defs = true
no_implicit_optional = true
check_untyped_defs = true
[tool.pyright]
typeCheckingMode = "strict"
reportUnknownParameterType = true
reportUnknownVariableType = true
reportOptionalMemberAccess = true
[tool.ruff]
target-version = "py312"
line-length = 100
[tool.ruff.lint]
select = ["E", "F", "B", "I", "UP"]
日常开发时,把它们变成一个固定命令:
ruff check .
mypy .
pyright
pytest
团队里可以再包一层:
make check
然后让 make check 出现在三个地方:
- 本地开发:写完一段代码先跑;
- pre-commit:提交前自动跑轻量检查;
- CI pipeline:合并前强制跑完整检查。
这就很接近静态语言里的“编译阶段”了:不是因为 Python 真的编译了,而是因为你人为建立了一道不可绕过的质量门。
不过还有一个细节:不要让 Any 到处漏。
Any 是静态检查里的“通行证”。一旦某个变量是 Any,类型检查器通常会对它很客气,客气到出事。
import json
from typing import Any
payload: Any = json.loads(raw_body)
charge(payload["amount"]) # 静态检查很可能沉默
更好的做法是:外部输入先用 Pydantic 验收,验收之后再把强类型对象交给业务代码:
payload = json.loads(raw_body)
req = ChargeRequest.model_validate(payload)
charge(req.amount)
这就是 Pydantic 和静态检查配合的关键:静态检查负责源码里的类型关系,Pydantic 负责把运行时输入转换成静态检查能理解的对象。
三、第一条最佳实践:所有外部输入都要过模型
动态语言最大的坑,不是没有类型提示,而是类型提示经常只给人看,运行时没人管。
比如:
def create_invoice(payload: dict) -> None:
amount = payload["amount"]
currency = payload["currency"]
# 继续往下调用支付系统
这段代码的问题不是短,而是太相信世界和平。
更稳妥的写法:
from decimal import Decimal
from typing import Literal
from pydantic import BaseModel, ConfigDict, Field
class CreateInvoiceRequest(BaseModel):
model_config = ConfigDict(extra="forbid")
amount: Decimal = Field(gt=0, max_digits=12, decimal_places=2)
currency: Literal["USD", "CNY", "EUR"]
customer_id: str = Field(min_length=1, max_length=64)
def create_invoice(payload: dict) -> None:
req = CreateInvoiceRequest.model_validate(payload)
# 从这里开始,业务代码面对的是 req,而不是裸 dict
这里有几个细节值得注意:
model_validate()是 Pydantic v2 推荐的显式验证入口。Field()不只是写默认值,也可以写长度、范围、精度等约束。extra="forbid"会拒绝多余字段,避免调用方悄悄塞进来一堆系统没理解的数据。
为什么我很喜欢 extra="forbid"?因为接口契约最怕“宽进宽出”。今天多传一个字段没人管,明天调用方就以为这个字段被支持了,后天你删日志字段都有人喊兼容性事故。
当然,不是所有场景都要 forbid。如果你在做埋点、透传、灰度兼容,extra="ignore" 或 extra="allow" 也有用。关键是:你要知道自己选择了什么,而不是吃默认值。
四、第二条最佳实践:默认宽松,关键字段严格
Pydantic 默认会做类型转换。比如字符串 "123" 可以变成整数 123。这对环境变量、HTTP query、JSON 字符串很方便。
方便有时也是坑。
from pydantic import BaseModel
class FeatureFlag(BaseModel):
enabled: bool
print(FeatureFlag.model_validate({"enabled": "false"}))
这类转换在很多场景是合理的,但在钱、权限、开关、配额这些字段上,就不能太随和。系统如果像一个老好人,迟早会被输入数据欺负。
可以按调用打开严格模式:
from pydantic import BaseModel, ValidationError
class Payment(BaseModel):
amount: int
try:
Payment.model_validate({"amount": "100"}, strict=True)
except ValidationError as exc:
print(exc.errors())
也可以按字段严格:
from pydantic import BaseModel, Field
class Payment(BaseModel):
amount: int = Field(strict=True, gt=0)
memo: str | None = None
或者整个模型严格:
from pydantic import BaseModel, ConfigDict
class InternalCommand(BaseModel):
model_config = ConfigDict(strict=True, extra="forbid")
action: str
retry_count: int
我的经验规则是:
| 字段类型 | 建议 |
|---|---|
| 金额、配额、权限等级 | 尽量严格 |
| 用户输入的搜索条件 | 可以宽松,但要限制长度 |
| 环境变量 | 可以转换,但启动时必须验证 |
| 内部系统命令 | 尽量严格,多余字段拒绝 |
| 第三方 webhook | 先宽松接住,再显式转换和兼容 |
Pydantic 官方文档也提醒:它的“validation”更偏向“把输入解析成符合目标类型的输出”。所以不要以为“验证过”就等于“输入原样正确”。这两个概念差半步,线上事故常常就藏在这半步里。
五、第三条最佳实践:用 Validator 表达业务边界
类型只能解决一部分问题。
age: int 能保证年龄是整数,但不能保证年龄合理;start_time 和 end_time 都是时间,也不能保证开始时间早于结束时间。
Pydantic v2 里常用两个装饰器:
@field_validator:验证单个字段;@model_validator:验证字段之间的关系。
看一个会议预订的例子:
from datetime import datetime
from pydantic import BaseModel, Field, field_validator, model_validator
class MeetingRequest(BaseModel):
topic: str = Field(min_length=1, max_length=128)
participants: list[str] = Field(min_length=1, max_length=100)
start_time: datetime
end_time: datetime
@field_validator("participants")
@classmethod
def normalize_participants(cls, value: list[str]) -> list[str]:
cleaned = [item.strip().lower() for item in value if item.strip()]
if not cleaned:
raise ValueError("participants cannot be empty")
return sorted(set(cleaned))
@model_validator(mode="after")
def check_time_range(self) -> "MeetingRequest":
if self.end_time <= self.start_time:
raise ValueError("end_time must be later than start_time")
return self
这里有两个边界:
- 单字段边界:参会人不能是空列表,邮箱或用户名可以做规范化。
- 跨字段边界:结束时间必须晚于开始时间。
Validator 的使用要克制。不要把核心业务流程塞进模型里,比如“扣库存”“查数据库”“调用风控服务”。Pydantic 模型适合做纯粹、快速、可重复的验证和转换。
我的建议:
- 可以做:大小写规范化、去空格、枚举兼容、字段关系检查;
- 谨慎做:依赖数据库的唯一性检查;
- 不要做:发网络请求、写数据库、产生副作用。
模型是边界守门员,不是业务总经理。
六、第四条最佳实践:别让配置在字符串里裸奔
Python 服务里最常见的配置事故,是环境变量明明存在,但类型不对。
TIMEOUT=30 读出来是字符串;DEBUG=false 读出来也是字符串。你以为是布尔值,Python 以为它是非空字符串,结果 debug 模式在生产环境笑眯眯地打开了。
Pydantic v2 之后,配置管理拆到了独立包 pydantic-settings:
pip install pydantic-settings
一个典型配置类:
from pydantic import Field, SecretStr
from pydantic_settings import BaseSettings, SettingsConfigDict
class AppSettings(BaseSettings):
model_config = SettingsConfigDict(
env_prefix="APP_",
env_file=".env",
extra="ignore",
)
service_name: str = "billing-api"
debug: bool = False
request_timeout_seconds: int = Field(default=3, ge=1, le=60)
database_url: SecretStr
settings = AppSettings()
这样做的好处:
- 服务启动时就能发现配置缺失或类型错误;
- 配置定义集中,不用到处
os.getenv(); SecretStr在打印时会做遮蔽,降低误打日志的风险;- 测试时可以通过初始化参数覆盖配置。
注意,.env 适合本地开发,不适合当生产密钥管理方案。生产环境里的密钥应该来自专门的 secret manager、Kubernetes Secret、云厂商密钥服务或公司内部密钥系统。Pydantic 负责读取和验证,不负责替你保管密钥。
七、第五条最佳实践:用 TypeAdapter 验证“不是模型”的类型
不是每个数据结构都值得建一个 BaseModel。
比如你只想验证一批事件:
from pydantic import BaseModel, Field, TypeAdapter
class Event(BaseModel):
name: str = Field(min_length=1)
ts: int = Field(ge=0)
events_adapter = TypeAdapter(list[Event])
def handle_events(payload: object) -> list[Event]:
return events_adapter.validate_python(payload)
TypeAdapter 适合这些场景:
- 验证
list[SomeModel]; - 验证
dict[str, int]; - 给简单类型生成 JSON Schema;
- 在性能敏感路径复用 adapter,避免重复构造。
一个小习惯:如果 adapter 会被频繁调用,把它放在模块级变量里复用,不要每次请求进来都创建一次。
八、第六条最佳实践:输出也要有边界
很多人只把 Pydantic 用在输入上,输出继续手写 dict。
手写 dict 的问题是:字段名容易拼错,datetime、Decimal、Enum 等类型序列化容易前后不一致,敏感字段也容易被顺手带出去。
用 model_dump() 和 model_dump_json():
from datetime import datetime
from decimal import Decimal
from pydantic import BaseModel, Field
class InvoiceView(BaseModel):
invoice_id: str
amount: Decimal
created_at: datetime
internal_note: str | None = Field(default=None, exclude=True)
view = InvoiceView(
invoice_id="inv_001",
amount=Decimal("99.90"),
created_at=datetime.now(),
internal_note="risk score: 42",
)
payload = view.model_dump(mode="json", exclude_none=True)
这里的重点不是少写几行代码,而是把“哪些字段能出去”变成模型的一部分。
对外 API、消息发布、LLM tool response,都应该有明确的 output model。输入是契约,输出也是契约。
九、第七条最佳实践:把 Schema 当成团队协作资产
Pydantic 可以生成 JSON Schema:
schema = CreateInvoiceRequest.model_json_schema()
这件事很容易被低估。
有了 Schema,你可以做很多工程化动作:
- 给前端或调用方生成契约文档;
- 在 CI 中对 schema diff 做检查;
- 给 LLM structured output 提供约束;
- 和 OpenAPI、AsyncAPI、事件协议管理结合;
- 写 contract test,防止接口悄悄破坏兼容性。
尤其是微服务和事件驱动系统里,schema 不只是文档,它是边界语言。没有 schema 的消息就像口头协议,大家都说“我理解了”,最后每个人理解得都不一样。
十、常见陷阱
1. 以为类型提示会在运行时生效
def send_email(to: str, retry: int) -> None:
...
这只是提示,不是运行时验证。调用方传 retry="3",Python 不会自动拦住。
如果这是边界函数,可以用模型;如果只是函数参数,也可以考虑 @validate_call:
from pydantic import validate_call
@validate_call
def send_email(to: str, retry: int) -> None:
...
但别滥用。对内部高频小函数全部加运行时验证,代码会变重,性能也会受影响。边界优先,热点克制。
2. 迷信默认类型转换
Pydantic 的宽松转换很好用,但不要让它替你做产品决策。
比如 "1" 能转成 1,但 "001" 是账号、编号还是数字?"false" 能不能当布尔值?空字符串要不要等于 None?
这些都不是库能替你决定的。关键字段用 strict,模糊输入先在 validator 里显式处理。
3. 忘了处理多余字段
Pydantic 默认会忽略多余字段。这个默认值对兼容有利,但对契约治理不一定好。
我建议:
class ApiRequest(BaseModel):
model_config = ConfigDict(extra="forbid")
除非你明确需要兼容未知字段,否则对 API request、内部命令、管理操作等场景,拒绝多余字段更安全。
4. 把 ORM 对象和 API 模型混在一起
数据库模型、领域模型、API request、API response,最好不要全用一个类。
偷懒共用模型,会带来几个麻烦:
- 数据库字段暴露到 API;
- API 字段改动影响持久化;
- response 里误带内部状态;
- validator 逻辑越来越混乱。
更稳妥的分层:
API Request Model -> Domain Command -> ORM Model -> API Response Model
小项目可以简化,但边界要想清楚。不要等用户看到 internal_status 字段才想起分层。
5. 在 Validator 里做副作用
Validator 里查数据库、调 HTTP、写缓存,看起来很顺手,后面会很痛。
因为模型验证通常被认为是纯操作。它可能在测试、重试、日志采样、schema 生成相关流程里被调用。你在里面塞副作用,就等于在门铃里接了个电饭锅,按一下发生什么全看缘分。
6. 忘记 v1/v2 差异
Pydantic v2 改了不少命名和写法:
| Pydantic v1 | Pydantic v2 |
|---|---|
parse_obj() |
model_validate() |
dict() |
model_dump() |
json() |
model_dump_json() |
schema() |
model_json_schema() |
@validator |
@field_validator |
@root_validator |
@model_validator |
BaseSettings 在 pydantic 中 |
BaseSettings 在 pydantic-settings 中 |
如果项目里 v1/v2 混用,最容易出现“看起来差不多,行为不一样”的维护成本。建议新项目直接 v2;老项目迁移时先统一依赖版本,再改 API,不要边跑边猜。
7. 错把 Pydantic 当静态类型系统
Pydantic 是运行时验证,不是静态编译。
它不能在代码提交前告诉你“这个函数调用传错了类型”,也不能替你发现某个分支永远走不到。那些问题应该交给 mypy、pyright、ruff、pylint 和测试。
同样,静态检查也不能替你验收真实输入。API 调用方、环境变量、消息队列、LLM 输出都不会因为你的类型标注写得漂亮,就自动变乖。
好的 Python 项目通常是组合拳:
typing写清意图;mypy或pyright做静态检查;ruff或pylint做代码质量扫描;- Pydantic 守住运行时边界;
- 单元测试和 contract test 验证行为;
- 日志和监控发现线上异常。
只上 Pydantic,不写测试,不做静态检查,还是会摔。只上静态检查,不验证外部输入,也会摔。区别只是摔在不同路段。
十一、我的推荐模板
下面是一个我比较推荐的 API request 模型模板,可以按项目风格裁剪:
from typing import Literal
from pydantic import BaseModel, ConfigDict, Field, field_validator, model_validator
class CreateTaskRequest(BaseModel):
model_config = ConfigDict(
extra="forbid",
str_strip_whitespace=True,
)
title: str = Field(min_length=1, max_length=128)
priority: Literal["low", "medium", "high"] = "medium"
assignee: str | None = Field(default=None, max_length=64)
tags: list[str] = Field(default_factory=list, max_length=20)
@field_validator("tags")
@classmethod
def normalize_tags(cls, value: list[str]) -> list[str]:
normalized = [tag.strip().lower() for tag in value if tag.strip()]
return sorted(set(normalized))
@model_validator(mode="after")
def check_high_priority_owner(self) -> "CreateTaskRequest":
if self.priority == "high" and not self.assignee:
raise ValueError("high priority task must have an assignee")
return self
再配一个 response 模型:
from datetime import datetime
from pydantic import BaseModel, ConfigDict
class TaskView(BaseModel):
model_config = ConfigDict(from_attributes=True)
task_id: str
title: str
priority: str
assignee: str | None
tags: list[str]
created_at: datetime
处理函数里保持清爽:
def create_task(payload: dict) -> dict:
req = CreateTaskRequest.model_validate(payload)
task = task_service.create(
title=req.title,
priority=req.priority,
assignee=req.assignee,
tags=req.tags,
)
return TaskView.model_validate(task).model_dump(mode="json")
这就是我喜欢的结构:入口验证,业务清楚,出口收口。代码不是最短,但调试半夜线上问题时,会感谢白天那个稍微啰嗦一点的自己。
十二、Pydantic 使用清单
新写一个 Python 服务或脚本时,可以照这个清单过一遍:
- [ ] HTTP request、MQ message、外部 API 返回、LLM 输出是否都有模型?
- [ ] 项目是否启用了
mypy或pyright,让类型错误尽量在提交前暴露? - [ ] 项目是否启用了
ruff或pylint,把明显代码味道和低级问题先扫掉? - [ ] 是否有统一的
make check或等价命令,把 lint、类型检查、测试串起来? - [ ] CI 是否强制执行这道检查,失败就不能合并?
- [ ] 项目里是否尽量减少
Any、裸dict、裸list,让类型检查器看得清楚? - [ ] API request 是否设置了
extra="forbid"或明确解释为什么不设置? - [ ] 金额、权限、配额、内部命令等关键字段是否启用了 strict 或显式 validator?
- [ ] 字符串是否有长度限制,列表是否有数量限制?
- [ ] 配置是否集中到
BaseSettings,服务启动时是否会失败得足够早? - [ ] 密钥字段是否用
SecretStr或等价机制,日志里是否会被遮蔽? - [ ] Validator 是否保持纯粹,避免数据库、网络、写文件等副作用?
- [ ] 输入模型、输出模型、ORM 模型是否按边界分开?
- [ ] 是否生成或保存 JSON Schema,供文档、CI 或 contract test 使用?
- [ ] 项目是否明确使用 Pydantic v1 还是 v2,避免混写?
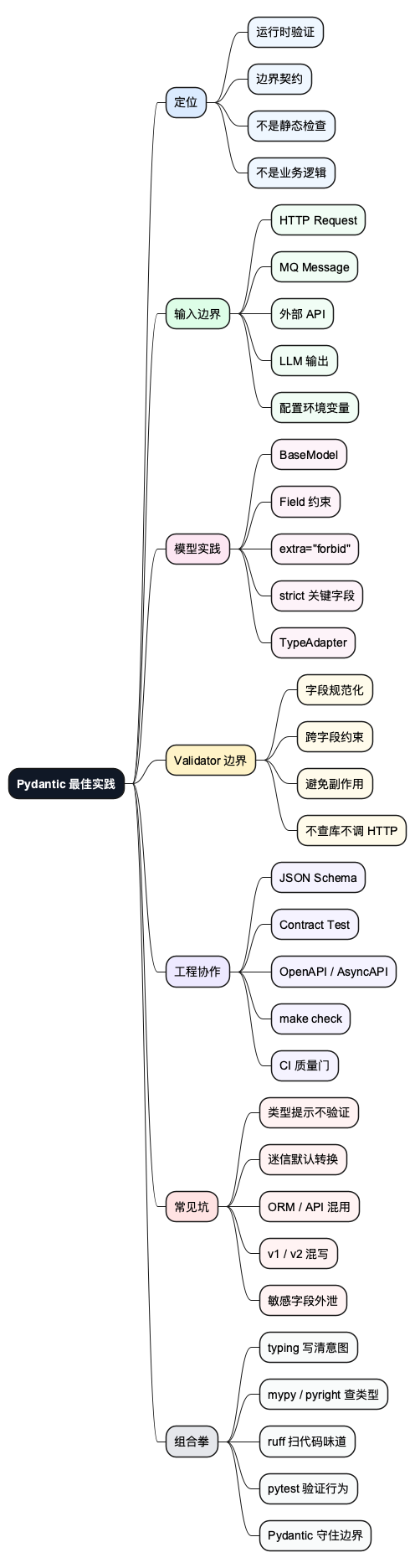
十三、思维导图
下面这张图把本文的主线压成一页:Pydantic 不是静态类型系统,也不是业务逻辑替身,它最适合站在系统边界上,把不可信输入变成有约束、可测试、可协作的对象。
@startmindmap
skinparam backgroundColor #FFFFFF
skinparam defaultFontName Arial
*[#111827] <color:white><b>Pydantic 最佳实践</b></color>
**[#DBEAFE] 定位
***[#EFF6FF] 运行时验证
***[#EFF6FF] 边界契约
***[#EFF6FF] 不是静态检查
***[#EFF6FF] 不是业务逻辑
**[#DCFCE7] 输入边界
***[#F0FDF4] HTTP Request
***[#F0FDF4] MQ Message
***[#F0FDF4] 外部 API
***[#F0FDF4] LLM 输出
***[#F0FDF4] 配置环境变量
**[#FCE7F3] 模型实践
***[#FDF2F8] BaseModel
***[#FDF2F8] Field 约束
***[#FDF2F8] extra="forbid"
***[#FDF2F8] strict 关键字段
***[#FDF2F8] TypeAdapter
**[#FEF3C7] Validator 边界
***[#FFFBEB] 字段规范化
***[#FFFBEB] 跨字段约束
***[#FFFBEB] 避免副作用
***[#FFFBEB] 不查库不调 HTTP
**[#EDE9FE] 工程协作
***[#F5F3FF] JSON Schema
***[#F5F3FF] Contract Test
***[#F5F3FF] OpenAPI / AsyncAPI
***[#F5F3FF] make check
***[#F5F3FF] CI 质量门
**[#FEE2E2] 常见坑
***[#FEF2F2] 类型提示不验证
***[#FEF2F2] 迷信默认转换
***[#FEF2F2] ORM / API 混用
***[#FEF2F2] v1 / v2 混写
***[#FEF2F2] 敏感字段外泄
**[#E5E7EB] 组合拳
***[#F9FAFB] typing 写清意图
***[#F9FAFB] mypy / pyright 查类型
***[#F9FAFB] ruff 扫代码味道
***[#F9FAFB] pytest 验证行为
***[#F9FAFB] Pydantic 守住边界
@endmindmap
十四、总结
Python 的动态特性不是原罪。它让我们写得快、试得快、改得快。问题在于,系统一旦接入真实世界,真实世界从来不按你的类型提示办事。
Pydantic 的价值,不是让 Python 变成一门静态语言,也不是替代静态代码检查,而是在关键边界上补一层运行时契约:
- 静态检查先看代码是否自洽;
- 入口数据先验收;
- 配置启动时验收;
- 输出字段明确收口;
- schema 成为团队协作资产;
- 关键字段不要过度相信自动转换。
一句话:动态语言可以灵活,但边界不能含糊。
如果明天只做三件事,我建议:
- 先建一个
make check:ruff check .、mypy .或pyright、pytest,让它进 CI。 - 找一个最容易出错的 API request,把裸 dict 换成 Pydantic model。
- 给配置加
BaseSettings,让服务在启动时暴露配置错误。
这三件事做完,代码不会立刻显得高级,但会少很多“怎么会传成这样”的低级事故。老程序员都知道,少一点这种事故,头发就多一点希望。
安全 Review Card
- 不要把 Pydantic 当作授权、认证、风控系统;它只负责输入结构和局部约束。
- 不要在 validator 中记录原始敏感输入,尤其是 token、密码、连接串和用户隐私字段。
.env只适合本地开发;生产密钥应由专门的 secret manager 或平台能力托管。- 对外错误信息要克制:内部日志可以结构化,用户响应不要泄露敏感字段和内部实现。
扩展阅读
- Pydantic Models
- Pydantic Strict Mode
- Pydantic Validators
- Pydantic Type Adapter
- Pydantic Settings Management
- Pydantic Migration Guide
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。