从传统 Wiki 到 AI 增强知识库
Posted on 五 29 5月 2026 in Tech
| Abstract | 从传统 Wiki 到 AI 增强知识库:人在回路中的知识管理 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v1.0 |
| Updated | 2026-05-31 |
| License | CC-BY-NC-ND 4.0 |
从传统 Wiki 到 AI 增强知识库:人在回路中的知识管理
现在基于 LLM API 的开源项目风起云涌,泥沙俱下。
每隔几天就有一个新的 AI 知识库项目冒出来:RAG 框架、Agent 框架、AI-native 笔记工具、自动整理的 Knowledge Base。看多了容易焦虑——好像不赶紧把整个笔记系统推倒重来,就会被时代抛弃。
我自己用的是一套传统的 Wiki 系统,用 Golang + Vue.js 写的,SQLite 存数据,Wiki 页面之间的链接靠手动维护。用了好几年,对自己深耕的领域够用,但知识量越来越大,光靠手动维护开始吃力。
读完 llm_wiki 这个项目后,我没有选择推倒重来,而是做一个更务实的决定:学它的精华,用 Python 写一个小工具,对自己现有的知识库做 AI 增强。
ROI 很重要。从头换一个系统,迁移成本、学习成本、习惯中断的成本,远高于在现有基础上加一个 AI 辅助层。
一、llm_wiki 给我的最大启发:Wiki 是编译产物,不是文档坟场
llm_wiki 的 README 里有一句核心描述:LLM 读取你的文档,构建结构化 Wiki,并持续保持更新。
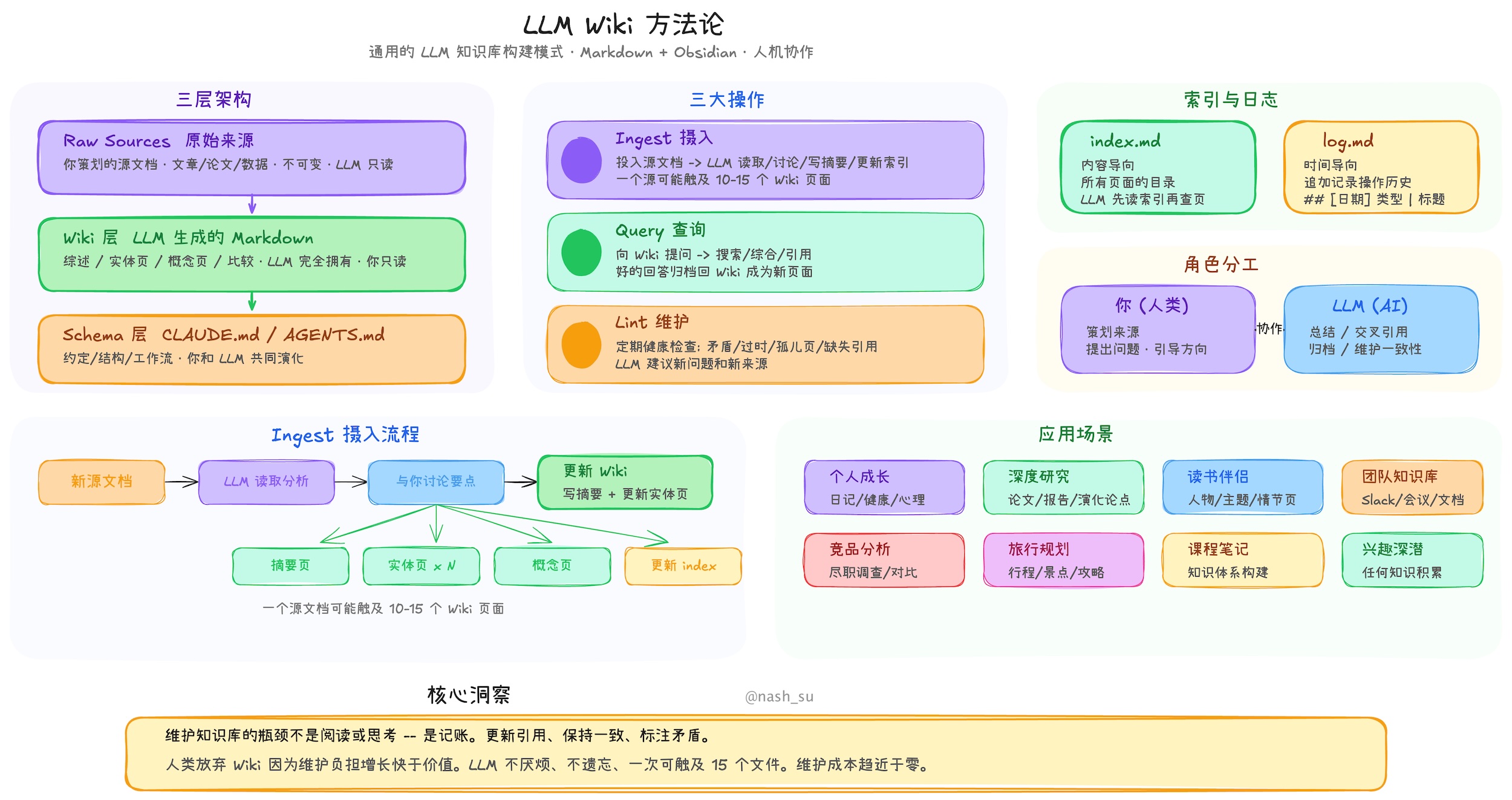
这句话把知识库的重心从"检索"挪到了"编译"。
项目保留了 Karpathy 的 LLM Wiki 模式:
Raw Sources -> Wiki -> Schema
三层各有分工:
- Raw Sources:原始资料,尽量不可变。文章、PDF、会议纪要、网页剪藏都先进入这里。
- Wiki:LLM 生成和维护的 Markdown 页面,包括实体、概念、资料摘要、查询结果等。
- Schema:告诉 LLM 这个 Wiki 的规则,比如页面类型、命名约定、交叉引用方式。
项目还加了一个很关键的文件:purpose.md。schema.md 解决"怎么写",purpose.md 解决"为什么写"。一个知识库如果没有目的,就会变成仓库。
这个分层对我启发很大。我的 SQLite Wiki 目前只有"页面"一层,没有显式的 schema 和 purpose。每当我导入一篇新资料,LLM 不知道哪些信息该突出、哪些该忽略,因为系统没告诉它"这个知识库到底用来干什么"。
二、它和普通 RAG 最大的不同:不是"现查现答",而是"持续积累"
普通 RAG 的流程大致是:
用户问题 -> 检索相关 chunk -> 拼上下文 -> LLM 回答
它的问题不在于没用,而在于每次都像临时抱佛脚。系统没有真正维护一个"已经理解过的知识结构"。
llm_wiki 的流程更像:
导入资料 -> LLM 分析 -> 生成/更新 Wiki 页面 -> 图谱与索引更新 -> 基于 Wiki 查询
知识不是每次查询时重新推导,而是在摄入时就被整理成页面、链接和索引。
这有三个好处:
1. 知识有稳定地址
每个概念、实体、资料摘要都有独立的页面。页面可以被引用、被 review、被 diff,也可以被 AI Agent 读取。聊天记录会消失,Wiki 页面会留下来。
2. 矛盾和空白可以提前暴露
摄入时 LLM 不只是总结资料,还会找关键实体、关键概念、与现有 Wiki 的联系、与旧知识的矛盾、值得后续研究的问题。这比"用户问到再说"更主动。
3. 查询可以基于结构,而不只是文本相似度
查询时叠加了 Wiki 图谱,不仅看"哪篇文字像",还看"哪些页面在知识网络里相关"。这就从文档检索往知识组织迈了一步。
三、我的选择:写一个 Python 工具,渐进增强
看完 llm_wiki,我的第一步不是部署它,而是问自己:有哪些思路可以直接迁移到我现有的 SQLite Wiki 上?
我的方案是写一个 Python 小工具,做三件事:
1. 给现有 Wiki 页面加 AI 摘要和标签
我的 Wiki 页面已经有标题和正文。Python 脚本遍历所有页面,对每篇调用 LLM 生成: - 一句话摘要; - 推荐标签; - 推荐关联页面(基于语义相似度)。
结果写回 SQLite 里新增的字段,不破坏原有结构。
2. 自动发现"孤立页面"
SQLite 里手动维护的链接可能不完整。写一个 lint 脚本,找出: - 没有被任何页面引用的页面; - 没有指向任何其他页面的页面; - 标题相似但没建立链接的页面。
这些不需要 LLM,纯 SQL 查询就能做一大半。
3. AI 辅助的链接建议
对每篇页面提取关键实体,和知识库里其他页面的标题做语义匹配,生成 [[wikilink]] 建议。人确认后才写入。
这就是 llm_wiki 给我的最大价值:不是让我换系统,而是教会我哪些工程思路能补上现有系统的短板。
这个工具的大致框架如下:
wiki-ai-tool/
├── main.py # CLI 入口,调用各子命令
├── config.py # LLM 配置、SQLite 路径、分级阈值
├── wiki_db.py # 连接 Golang Wiki 的 SQLite,只读+建议写入
├── llm_client.py # LLM API 封装(OpenAI / 本地模型)
├── analyzers/
│ ├── page_analyzer.py # 单页分析:摘要、标签、实体抽取
│ └── relation_analyzer.py # 跨页分析:语义相似度、链接建议
├── linters/
│ ├── structure_lint.py # 孤立页面、无出链、断链(纯 SQL)
│ └── semantic_lint.py # 矛盾检测、过期提示(调 LLM)
├── graders/
│ └── knowledge_grader.py # 知识分级:draft / reviewed / deprecated / critical
├── reporters/
│ └── review_report.py # 生成 Review 报告,存到 ai_suggestions/
└── scripts/
└── nightly_run.sh # 每晚定时跑 lint + 分析
核心模块 page_analyzer.py 的伪代码:
def analyze_page(db, page_id):
page = db.get_page(page_id)
if not page:
return
# 1. 提取正文,去除 HTML/Vue 模板标记
content = clean_content(page.html_body)
# 2. 调 LLM 做结构化分析
analysis = llm.analyze(
system="你是知识库分析助手。请提取关键实体、概念、一句话摘要、推荐标签。",
content=content,
schema={
"summary": "string",
"tags": ["string"],
"key_entities": ["string"],
"key_concepts": ["string"],
"related_page_ids": ["int"]
}
)
# 3. 分析结果写入 ai_suggestions 表,不直接改正式数据
db.save_suggestion(page_id, analysis, status="pending")
# 4. 如果置信度高,标记为 auto-approved
if analysis.confidence > 0.9:
db.save_suggestion(page_id, analysis, status="auto_approved")
自动发现孤立页面的伪代码:
def find_orphan_pages(db):
# 纯 SQL,不需要 LLM
rows = db.query("""
SELECT p.id, p.title
FROM pages p
LEFT JOIN page_links l ON p.id = l.target_id
WHERE l.target_id IS NULL
AND p.status != 'deprecated'
""")
for row in rows:
report.add_issue(
type="orphan_page",
page_id=row.id,
title=row.title,
suggestion=f"该页面未被任何页面引用,考虑归档或添加反向链接"
)
return report
链接建议模块的伪代码:
def suggest_links(db, page_id):
page = db.get_page(page_id)
content = clean_content(page.html_body)
# 1. 从正文中提取候选实体
entities = llm.extract_entities(content)
# 2. 模糊匹配现有 Wiki 页面标题
candidates = []
for entity in entities:
matches = db.query("""
SELECT id, title FROM pages
WHERE title LIKE ?
LIMIT 5
""", (f"%{entity}%",))
candidates.extend(matches)
# 3. 去重 + 排除已有链接
existing_links = set(db.get_outgoing_links(page_id))
suggestions = [
c for c in candidates
if c.id not in existing_links and c.id != page_id
]
# 4. 写入建议表,人在 UI 中确认后才生效
for s in suggestions[:10]:
db.save_link_suggestion(
source_id=page_id,
target_id=s.id,
status="pending"
)
Review 报告生成:
def generate_review_report(db):
report = []
# 1. 结构化 lint 结果(纯 SQL)
report.extend(find_orphan_pages(db))
report.extend(find_no_outlinks_pages(db))
report.extend(find_broken_links(db))
# 2. 待审的 AI 建议
pending = db.query("""
SELECT * FROM ai_suggestions
WHERE status = 'pending'
AND created_at > datetime('now', '-7 days')
ORDER BY confidence ASC
""")
for p in pending:
report.append({
"type": "ai_suggestion",
"page_id": p.page_id,
"suggestion": p.content,
"confidence": p.confidence
})
# 3. 写报告
report_path = f"ai_suggestions/review_{datetime.now():%Y%m%d}.md"
write_markdown_report(report_path, report)
print(f"Review report generated: {report_path}")
return report_path
整套工具的调用链:
nightly_run.sh
└─ python main.py lint --structure # 纯 SQL 检查
└─ python main.py analyze --all # LLM 批量分析未处理页面
└─ python main.py suggest-links --all # LLM 链接建议
└─ python main.py report # 生成 review 报告
manual (按需)
└─ python main.py analyze --page 42 # 分析单页
└─ python main.py grade --page 42 # 重新分级
└─ python main.py lint --semantic # 语义 lint(较慢,按需跑)
这套框架的核心原则是:所有 AI 产出都先进入"建议区",经人确认后才能写入正式知识库。 这和 llm_wiki 的 REVIEW block 思路一脉相承,但更轻量——不需要改现有 Wiki 系统的代码,只在外部加一层 Python 辅助工具。
四、知识分级:让 AI 知道自己能做什么
AI 不是万能的。甚至可以说,AI 大部分时候是"自信地犯错"。
我把知识分成四个等级:
| 等级 | 含义 | AI 的参与程度 |
|---|---|---|
draft |
AI 生成,未经人工审阅 | AI 可以独立生成,但必须标记 |
reviewed |
人工确认过内容 | AI 可以修改,但需要人批准 |
deprecated |
已废弃的知识 | AI 可以建议归档,但人决定 |
critical |
涉及生产、安全、客户或钱 | AI 只能建议,必须双人 review |
这个分级解决了两个问题:
一是 AI 的产出有明确的"信任等级"。看一个 draft 页面,知道要警惕;看一个 critical 页面,知道它有严格的审核记录。
二是 人能合理分配精力。不是所有页面都需要深度 review。draft 和 reviewed 的页面可以在知识库里共存,阅读时自行判断。
人在其中的作用就像导师:可以指导学生写论文,也可以从学生的文献综述里学到新东西。但导师始终要对领域方向有深入的思考和引领,不会人云亦云。
五、人在回路中:导师、工人、咨询师和秘书
这是整篇文章最想说的一个观点。
很多 AI 知识库的宣传口径是"装上 AI,知识库自动管理"。这是危险的。
AI 是干活的工人,是咨询师,是秘书,而领导始终是人。
具体来说:
| 角色 | 做什么 |
|---|---|
| 人(导师/领导) | 选择资料、判断真假、决定取舍、定方向、承担责任 |
| AI(工人) | 总结资料、更新索引、建立链接、生成摘要 |
| AI(咨询师) | 提出矛盾、发现知识空白、推荐研究方向 |
| AI(秘书) | 定时巡检、整理孤岛页面、生成周报 |
AI 可以提出怀疑,但人来做裁决。 这是贯穿所有知识库实践的底线。
知识库最怕两种极端:一种是完全没人维护,另一种是 AI 自动改一切。前者会腐烂,后者会失控。中间路线是:让 AI 把脏活先挑出来,人只处理高价值判断。
而且,知识不是死的。它不是一篇篇文章和一行行代码。知识是成体系的,是活的,是不断演进的。 只有人才能理解知识之间的隐性联系,才能判断哪些知识点值得深入,哪些只是噪音。AI 可以帮我们整理,但不能替我们思考。
六、摄入与合并:LLM 先分析,再写 Wiki
llm_wiki 的摄入流程拆成了两步,这个设计值得借鉴。
第一步是分析:提取 Key Entities、Key Concepts、Main Arguments、Connections to Existing Wiki、Contradictions。
第二步才是生成:把分析结果、原始资料、schema、purpose 一起喂给 LLM,输出受约束的格式。
这个"先分析再生成"的模式,我在自己的 Python 工具里也用了。先让 LLM 分析一篇资料,把分析结果存到 SQLite 的一个分析表里。我 review 之后,再让 LLM 基于分析结果生成页面更新或链接建议。
这样一来,LLM 写的不是"最终答案",而是"草稿",草稿经过人工确认才能进正式的 Wiki。
页面合并也是容易被忽略的难题。同一个概念被多份资料反复更新,如果每次都覆盖,旧内容会丢;如果每次都追加,页面会变成流水账。llm_wiki 的 page-merge.ts 做了一个务实的策略:frontmatter 数组字段确定性合并,正文不同时走 LLM 语义合并,关键字段锁住不让 LLM 乱改,合并结果太短就拒绝,失败时回退到保守合并。
这非常像代码合并。知识库一旦长期运行,一定会遇到冲突、重复、改名、过期和删除。很多 Demo 只演示"导入一篇文章然后生成几页 Wiki",真正用三个月,麻烦都在这些边角里。
七、检索:关键词、向量和图谱三条腿走路
llm_wiki 的检索流程值得借鉴,但不是因为它用了最新的 embedding 技术,而是因为它不用银弹思维。
关键词搜索对错误码、接口名、命令、文件路径更可靠。向量搜索处理语义模糊的场景。图谱搜索处理知识结构关联。
这三条腿走路,每条都有各自擅长的场景。
上下文预算也是工程亮点。context-budget.ts 里把上下文窗口按比例分配:约 5% 给 index,约 50% 给 Wiki 页面,预留约 15% 给模型回答,单页有最大长度限制。
很多 RAG 系统一开始效果不错,文档多了以后就开始乱塞上下文,最后不是超 token,就是把真正关键的页面挤出去。上下文管理是 AI 时代的新内存管理。
八、知识图谱:不是为了好看,是为了发现结构问题
llm_wiki 用 sigma.js + graphology + ForceAtlas2 做图谱可视化,用 Louvain 做社区发现。但它更有价值的是图谱洞察,检测几类结构问题:
- Surprising Connections:跨社区、跨类型的意外连接;
- Isolated Pages:几乎没有连接的页面;
- Sparse Communities:内部连接稀疏的知识群;
- Bridge Nodes:连接多个知识簇的关键节点。
一个知识库长到一定规模以后,最怕的不是没有内容,而是内容彼此不认识。孤立页面、稀疏社区、过强的单点桥接,都是知识结构里的坏味道。
在我的 SQLite Wiki 里,等价于跑 SQL:统计出度入度为零的页面、找出断层的话题分类、标记引用频次异常的节点。这些不需要图谱可视化,但洞察是一样的。
九、Lint 和 Review:AI 不只负责生成,也负责体检
llm_wiki 的 lint 有两类检查:
结构化 Lint(不用 LLM):orphan page、no outlinks、broken link。这些是确定性规则,没必要浪费 token。
语义 Lint(用 LLM):页面之间是否有矛盾、信息是否过期、重要概念是否缺页面、是否有值得继续研究的问题。
这套机制背后的原则很朴素:AI 可以提出怀疑,但人来做裁决。
我的 Python 工具也实现了类似功能:每晚定时跑 lint,生成一个 review 报告放在一个单独的目录里,第二天早上看。不强制,但提供了可见性。
十、Deep Research:从知识空白反向找资料
llm_wiki 更进一步:当图谱或审核发现知识空白,可以触发 Deep Research。
流程是:发现空白 -> 生成搜索查询 -> 收集资料 -> LLM 综合成研究页面 -> 再摄入 Wiki -> 图谱变得更完整。
这是一个闭环。但关键细节是:研究主题和搜索查询会在可编辑确认框里展示,不能让 AI 想搜什么就搜什么。外部搜索会把不受控信息带进系统。
这个我打算放在 Python 工具的第二阶段实现。第一阶段先把已有知识整理好,第二阶段再加入主动研究能力。
十一、我会如何评价这个项目的架构
llm_wiki 的亮点不在 UI 功能多,而在它抓住了几个关键抽象。
1. 把 LLM 当 maintainer,而不是 chatbot
Chatbot 回答完就结束了。Maintainer 要维护文件、索引、日志、链接、图谱、review、缓存和删除级联。
2. 把 Markdown 文件作为核心资产
知识不被锁死在某个数据库里。哪怕应用不运行,文件仍然可读、可 diff、可备份、可迁移。知识库系统可以换,知识本身不能被绑架。
我的 SQLite Wiki 也有这个问题。我在考虑加一个"导出标准化 Markdown"的功能,让知识不止存在于 SQLite 里。
3. 把不确定性变成 Review,而不是假装确定
LLM 不确定的时候,应该进入 review 队列,而不是写进正式结论。
4. 对失败路径有防御
源码里有大量"看起来不性感"的处理:ingest cache、queue 持久化、retry、abort、page merge fallback、unsafe path rejection、language guard、embedding failure fallback。这些东西写文章时很难讲得热血沸腾,但恰恰决定一个工具能不能真用。
十二、我看到的风险和应对
1. LLM 维护 Wiki,仍然可能引入"自信的错误"
两阶段摄入、review、lint 可以降低风险,但不能消灭风险。知识分级和人工 review 是必须的防线。AI 说的不一定对,AI 给的方案大多有待提高,AI 的创新能力也远远不足——这是人在其中大有可为的地方。
2. 知识库会遇到"模型风格污染"
LLM 维护久了,页面可能越来越像模型写的:正确、流畅、平均、没有现场感。个人知识库必须保留自己的原始观察,不要都改成百科腔。
3. 图谱很有用,但要防止变成装饰
图谱洞察比单纯画图有用。图谱不是为了好看,而是为了发现维护动作。
4. API 一旦开放给 Agent,要继续收紧权限
知识库越有价值,越不能裸奔。
十三、如果要用 AI 增强自己的知识库,我会这样开始
以下是我正在做的实践步骤,也是我推荐的做法:
第一步:选一个明确主题
别一上来就导入 10GB 文档。知识库最怕"大迁移,大失败"。选一个窄主题开始,比如"WebRTC 拥塞控制"或者"某个项目的运维知识"。
第二步:写好知识库的 purpose
回答四个问题: - 这个知识库要服务谁? - 它主要回答哪些问题? - 哪些内容不在范围内? - 什么样的输出算有价值?
第三步:从 10 份高质量资料开始
先导入少量资料,观察 LLM 的分析质量。如果 10 份资料都整理不好,导入 1000 份只会更乱。
第四步:写一个 Python 工具做增量增强
不要推倒重来。在现有知识库上加一层 AI 辅助: - 一个脚本做 LLM 分析; - 一个脚本做 lint 和 review; - 一个脚本做链接建议。
每个脚本都可以独立运行,输出放到一个 ai_suggestions/ 目录,经人确认后再合并到主知识库。
第五步:把查询结果保存回知识库
重要问题不要只停留在 chat history 里,要沉淀成 Wiki 页面。知识库的复利来自这里。
第六步:定期跑 Lint 和 Review
每周做一次:broken link、orphan page、no outlinks、stale page、contradiction、missing page。不要等知识库烂了再治理。文档债和技术债一样,都是复利,只是方向相反。
总结:AI 是维护系统,人才是知识库的主人
读完 llm_wiki,我最大的收获是:AI 知识库的重点不是"让 AI 回答得更像人",而是"让知识能持续积累、持续被维护、持续被验证"。
但更重要的是,在整个过程中,人始终要掌握方向。
| 角色 | 负责什么 |
|---|---|
| Raw Sources | 保存原始证据 |
| Wiki | 承载结构化、可审计、可链接的知识 |
| Schema | 约束页面类型、格式和维护规则 |
| Purpose | 给知识库方向和边界 |
| LLM | 分析、生成、合并、检索、巡检、提出疑问 |
| Human | 选择资料、判断真假、决定取舍、定方向、承担责任 |
AI 不是知识库的大脑,而是知识库的维护系统。它的价值不是替代人思考,而是接管那些人类最容易偷懒的维护工作:总结资料、更新索引、建立链接、发现矛盾、找出孤岛页面、生成后续研究问题、把一次性回答沉淀成长期页面。
你不需要推倒重来。学 llm_wiki 的精华,写一个 Python 小工具,从今天能做的事开始。知识库是你自己的,系统可以换,但方向和判断力在你手里。