AI 时代的信息资源管理:让八面来风变成知识流水线
Posted on 日 07 6月 2026 in Tech
| Abstract | AI 时代的信息资源管理:让八面来风变成知识流水线 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v0.1 |
| Updated | 2026-06-07 |
| License | CC-BY-NC-ND 4.0 |
AI 时代的信息资源管理:让八面来风变成知识流水线
大学时我学过一门课,叫"信息资源管理"。当年听起来有点像图书馆学、数据库和管理学的混合体:信息怎么采集,怎么分类,怎么检索,怎么利用。说实话,那时我更多关心的是考试怎么过,没想到几十年后,这门课突然返场了。
现在想想,它简直像是给 AI 时代埋的一条伏线。
今天的信息不是四面八方来,而是八面来风:Zoom Chat、Zoom Doc、Email、Confluence wiki、Jira Issues、GitLab/GitHub Issue、代码仓库、个人 note、blog、kanban,再加上新闻、技术文章、书籍、播客、会议纪要、公众号、YouTube、arXiv。过去靠人一封封读、一篇篇摘、一点点归档,就像用脸盆接暴雨,姿势很努力,效果很狼狈。
AI 出现以后,事情确实变了。但我不太相信"以后不用读了,让 AI 全读"这种话。听着轻松,实际很危险。我的看法很简单:
AI 可以帮我们做信息管理里的苦活,但不能替我们决定什么值得相信、什么值得留下、什么值得行动。
换句话说,AI 时代的信息资源管理,不是把人从信息世界里撤出去,而是把人从重复劳动里解放出来,让人回到判断、取舍和负责的位置。
一、问题不是信息太少,而是入口太多
以前做知识管理,常见痛点是"找不到资料"。现在更常见的痛点是:资料太多,找到了也不敢信,信了也不知道怎么用。
一个普通工作日,信息流大概长这样:
| 来源 | 典型内容 | 最大问题 |
|---|---|---|
| 邮件 | 决策、通知、正式沟通 | 冗长,夹杂抄送噪音 |
| IM | 快速讨论、上下文碎片 | 易丢,难追溯,情绪多于结构 |
| 会议纪要 | 决议、行动项、争议点 | 容易写成流水账,重点常被埋掉 |
| 技术文章 | 方法、案例、经验 | 质量参差,真假难分 |
| 书籍 | 系统性知识 | 阅读周期长,回收慢 |
| 播客/视频 | 观点、趋势、访谈 | 信息密度不稳定,难检索 |
| 代码/Issue/Wiki | 工程事实 | 分散在不同系统里,需要上下文拼接 |
如果只靠人脑处理,结果往往是三种:
- 收藏夹变坟场。 存的时候觉得"以后一定有用",以后就再也没见过。
- 笔记变仓库。 每条笔记都在,可要用时还是靠搜索和运气。
- 大脑变路由器。 什么信息都先过自己一遍,最后人累得像线上故障时的单点服务。
信息管理的第一步,不是找一个更漂亮的笔记软件,而是承认一个事实:入口太多,人脑不该继续当所有信息的第一处理器。 咱们是人,不是 Kafka。
二、AI 能接手的,是"信息流水线"里的苦活
如果借用数据工程的说法,个人信息管理也可以看成一条小型 ETL 流水线:
Collect -> Clean -> Transform -> Load -> Mine -> Act
采集 -> 清洗 -> 转换 -> 入库 -> 挖掘 -> 行动
过去这条线大部分靠人手完成。看到一篇文章,自己判断要不要读;读完自己摘重点;摘完自己分类;过几周再自己想办法找回来。每一步都不难,可每一步都要吃掉注意力。
AI 在这里最有价值的地方,不是"替你变聪明",而是替你做几类特别磨人的工作。
1. 采集:先把八面来风接住
采集不是"什么都存"。那叫囤积。
好的采集应该有入口规则:哪些邮件需要进入知识库,哪些聊天记录只保留行动项,哪些文章只存摘要,哪些书摘需要标来源和页码。
AI 可以帮你做第一层分拣:
- 从邮件里提取决策、截止时间、责任人。
- 从会议纪要里提取行动项、风险、未决问题。
- 从技术文章里提取主张、证据、适用场景。
- 从播客转录里提取观点和可引用片段。
注意,这一步只是"接住",不是"盖章认证"。AI 把鱼捞上来,鱼新不新鲜还得人看。
2. 清洗:把噪音先滤掉
信息世界里最贵的不是存储空间,是注意力。
一封邮件三千字,真正有用的可能只有三句话。一个会议一小时,真正要追踪的可能只有两个决议和一个风险。一个技术帖子写得热热闹闹,剥到最后可能只有一个小技巧。
AI 很适合做清洗:
- 去掉寒暄、重复、跑题内容。
- 合并同一话题的多条消息。
- 标出时间、人物、系统、项目、版本号等实体。
- 把模糊表达改成可追踪条目,比如"尽快处理"改成"需要确认负责人和截止时间"。
这一步做不好,后面全乱。脏数据进知识库,就像脏水进水箱,过滤器再高级也顶不住。
3. 转换:从"材料"变成"卡片"
信息要被复用,必须从原始材料变成结构化对象。
我比较喜欢把一条有效信息转成这样的卡片:
title: AI 时代的信息资源管理
source:
type: article
url: <原始链接>
author: <作者>
captured_at: 2026-06-07
claim: 信息管理不是收藏,而是持续加工
evidence:
- 邮件、IM、文章、播客等入口过多
- 人脑不适合做所有信息的第一处理器
usable_for:
- 写作
- 技术调研
- 团队知识库
risk:
- 需要核对原文
- 不适合直接当事实引用
next_action:
- 整理成一篇方法论文章
这张卡片不复杂,却解决了一个关键问题:让 AI 和人都知道这条信息从哪里来、说了什么、能用在哪里、还缺什么校验。
没有结构的笔记,只是一堆句子;有结构的卡片,才是可被组合、检索、审计、复用的知识零件。
4. 入库:别把所有东西倒进一个黑箱
很多 AI 知识库产品的问题,是喜欢把一切都吸进去,然后告诉你:"放心,我能问答。"
我不太放心。
个人或团队知识系统至少要分层:
raw/ 原始材料,尽量保留来源
cards/ 结构化卡片,经过初步清洗
wiki/ 可阅读、可引用的知识页面
index/ 标签、实体、主题、向量索引
review/ 待核查、待确认、待过期处理
raw 是证据,cards 是加工件,wiki 是稳定表达,index 是检索加速器,review 是质量闸门。
这几个层次最好不要混在一起。原文是原文,摘要是摘要,判断是判断。混在一起以后,半年后你自己都分不清哪句话是作者说的,哪句话是 AI 总结的,哪句话是自己当时脑子一热写的。
5. 挖掘:从"我存过"到"它提醒我"
信息管理真正有价值的地方,不是"我能搜索到",而是它能在合适的时候回到你面前。
比如:
- 你准备写一篇 WebRTC 文章,AI 自动找出过去的会议纪要、代码片段、读书笔记和老博客。
- 你要做技术选型,AI 汇总历史上踩过的坑、类似项目的决策记录和相关设计文档。
- 你准备季度复盘,AI 把过去三个月的关键输出、未闭环问题和反复出现的主题列出来。
- 你读一本新书,AI 帮你把书中概念连到已有知识库里的旧概念。
这一步不是简单问答,而是连接。好的信息系统不只是回答"在哪里",还会提示"它和什么有关"。
三、最容易踩的坑:把 AI 当成真理机
AI 处理信息很快,但快不等于可靠。
我见过一种危险用法:把一堆资料扔给 AI,让它总结,然后直接把总结当结论。看起来省了时间,实际省掉的是核查。尤其是涉及公司内部决策、技术风险、客户反馈、法律合规、隐私数据时,这种省事以后很可能要加倍还债。
至少要守住几条边界。
第一,来源必须可追溯。
任何重要结论都要能回到原始材料。没有出处的总结,只能当线索,不能当证据。
第二,敏感信息不能乱喂。
邮件、IM、会议纪要、客户信息、代码仓库里都有敏感内容。能用内部模型就不要用公开模型;能脱敏就先脱敏;没有授权的数据不要采集。AI 不是保密柜,别把它当成保密柜。
第三,判断权不能外包。
AI 可以给候选标签、候选摘要、候选关系,但"这条信息值不值得进入长期知识库"、"这个结论能不能写进设计文档"、"这个风险要不要升级",最终还是人决定。
第四,过期信息要处理。
知识库最烦人的不是空,而是旧。一个三年前的 workaround,如果没有过期标记,今天可能就是事故导火索。AI 可以帮你定期找"可能过期"的页面,但是否废弃仍要人确认。
四、一个真实样例:这么多源头怎么不被淹没
说得再漂亮,不落到日常工具上都是白搭。
假设你的信息源是这些:Zoom Chat、Zoom Doc、Email、Confluence wiki、Jira Issues、GitLab Issue、GitLab/GitHub code、personal note/blog/kanban。听起来就像开了八个水龙头,水压还都不低。
我的建议很简单:不要按"信息源"管理信息,要按"用途"管理信息。
所有信息进来后,只能进入四个出口:
| 出口 | 含义 | 例子 | 默认动作 |
|---|---|---|---|
| Action | 要我做什么 | Jira 要更新、MR 要 review、邮件要回复 | 进个人 kanban 或回写到 Jira/GitLab |
| Decision | 已经决定了什么 | 架构选 A,不选 B;上线时间改到下周 | 回写到 Zoom Doc/Confluence/Jira |
| Knowledge | 将来可复用的经验 | 某个 API 的坑、一次故障复盘、一段 prompt 模板 | 进入个人 note/blog 或团队 wiki |
| Archive | 只留痕,不处理 | 普通通知、FYI、历史聊天 | 留在原系统,不搬运 |
这四个出口很土,但救命。没有它们,你会下意识追求"全部读完"。这在今天已经不现实。真正的目标是:重要的事不漏,重要的决定有记录,重要的知识能复用,不重要的信息自动沉底。
1. 源头不要搬家,只抽取信号
很多人做知识管理,第一反应是:"我要不要把所有东西同步到一个系统里?" 我劝你冷静一点。那很容易制造第二份真相。
更好的做法是:source of truth 留在原系统,个人系统只保存索引、摘要、判断和下一步。
| 信息源 | 它最适合当什么 | 不要做什么 | AI 该抽取什么 |
|---|---|---|---|
| Zoom Chat | 快速讨论、上下文线索 | 不要把整段聊天搬进笔记 | mention、承诺、疑问、临时共识 |
| Zoom Doc | 设计、方案、正式材料 | 不要在个人笔记里复制一份全文 | 摘要、决策、待确认点、链接 |
| 正式通知、跨团队确认 | 不要把 inbox 当任务系统 | 截止时间、责任人、需要回复的点 | |
| Confluence wiki | 团队知识和流程 | 不要把旧页面当永远正确 | owner、更新时间、是否过期 |
| Jira Issues | 需求、Bug、任务状态 | 不要在个人 kanban 重写一套状态 | 阻塞、风险、下一步、我负责的动作 |
| GitLab/GitHub Issue | 代码相关问题和讨论 | 不要只看评论不看代码 | 结论、关联 MR、未解决问题 |
| GitLab/GitHub code | 工程事实 | 不要让摘要替代源码 | 变更意图、关键文件、测试影响 |
| Personal note/blog/kanban | 自己的判断和沉淀 | 不要当垃圾中转站 | 可复用模板、复盘、文章素材 |
一句话:Chat 留上下文,Doc 留方案,Jira 留任务,Git 留事实,个人笔记留判断。
2. 每天 15 分钟:只问五件事
每天不用把所有系统清零,只要让 AI 帮你做一次"信号扫描"。
可以把问题固定成这样:
请基于今天的 Zoom Chat、Email、Jira、GitLab/GitHub 更新,生成我的每日信息摘要。
只输出五类内容:
1. 今天必须处理的 Action,最多 5 条。
2. 有明确 owner 或 deadline 的承诺。
3. 新出现的风险、阻塞或争议。
4. 已经形成但还没有回写到文档/Issue 的 Decision。
5. 值得沉淀到个人 note/blog/wiki 的 Knowledge,最多 3 条。
每条都要包含:
- source_link
- owner
- deadline (没有就写 unknown)
- confidence: high / medium / low
- next_action
然后你只做一个人工动作:给每条信息打一个处置标签。
do 今天做
delegate 交给别人
wait 等外部输入
writeback 回写到 Doc/Jira/GitLab
archive 不处理
注意,不要让 AI 替你决定优先级。AI 可以把菜端上来,吃哪盘还得你自己定。它不知道你这周真正的目标,也不知道某个会议里谁脸色不对。
3. 每周 30 分钟:把信息变成资产
每天的 15 分钟解决"不被淹没"。每周的 30 分钟解决"有所沉淀"。
周五下班前,或者周一早上,跑一次 weekly review:
请基于本周 Zoom Chat、Zoom Doc、Email、Confluence、Jira、GitLab/GitHub 和我的个人 kanban,做一次信息资产复盘。
请输出:
1. 本周完成的关键 Action。
2. 本周形成的 Decision,以及它们是否已回写到正式位置。
3. 本周反复出现的 3 个主题。
4. 本周值得沉淀的 Knowledge,按"可复用价值"排序。
5. 仍然散落在 Chat/Email 里的重要信息。
6. 可能过期或互相矛盾的 Doc/Wiki/Jira 信息。
7. 下周建议关注的 3 个风险。
这一步不要追求全自动。AI 的输出只是候选清单,你要做三件事:
- 把 Decision 回写到该在的地方。
- 把 Knowledge 写进个人 note/blog 或团队 wiki。
- 把无价值信息丢掉,不解释。
很多人的知识系统死在"只进不出"。每周 review 本质上就是给系统排水。水能流出去,池子才不会发臭。
4. 个人 kanban 只保留六列
个人看板不要设计得像企业流程引擎。越复杂越没人用。
我建议只保留六列:
| 列 | 用途 | 规则 |
|---|---|---|
| Inbox | 临时入口 | 最多保留 7 天 |
| Action | 我需要做的事 | 必须有 next_action |
| Decision | 我需要记住的决定 | 必须有 source_link |
| Knowledge | 值得复用的知识 | 必须能解释未来怎么用 |
| Someday | 有价值但现在不处理 | 每月清一次 |
| Trash | 删除 | 不要写悼词 |
最重要的是 WIP 限制:
Action不超过 7 条。Decision每周必须回写到正式文档。Knowledge每周最多沉淀 3 条。Inbox超过 7 天自动归档或删除。
这几条看着冷酷,其实是在保护注意力。人的大脑不是消息队列,不能无限堆积。
5. 一张"防淹没"检查清单
每天结束前,用下面这张表扫一眼就够。
| 检查项 | 是/否 |
|---|---|
| 今天有没有漏掉直接 @ 我的 Zoom Chat 或 Email? | |
| 我负责的 Jira/GitLab Issue 是否都有下一步? | |
| 今天形成的 Decision 是否已经回写到 Doc/Jira/GitLab? | |
| 是否有重要信息只留在 Chat,没有正式记录? | |
| 是否有 1 条信息值得沉淀成 Knowledge? | |
| Inbox 里是否有超过 7 天还没处理的东西? | |
| 今天有没有把敏感信息喂给不该用的 AI? |
如果这张表里有三项以上是"否",说明不是你不努力,而是系统开始漏水了。别继续硬扛,先修排水系统。
6. 把输出挂回行动
信息管理的终点不是"我知道了",而是"我因此做了什么"。
每条重要信息最好能落到某种输出:
| 信息类型 | 推荐输出 |
|---|---|
| 技术文章 | 实验、代码片段、最佳实践清单 |
| 会议纪要 | 行动项、风险清单、决策记录 |
| 书籍观点 | 读书笔记、方法模板、文章选题 |
| 客户/用户反馈 | 问题假设、需求池、验证计划 |
| 项目经验 | Runbook、FAQ、复盘条目 |
| 代码讨论 | Issue 更新、MR comment、测试用例 |
如果一条信息永远不产生行动,也不改变理解,它大概率只是"收藏欲"的安慰剂。
五、团队场景:别让 AI 知识库变成另一个垃圾桶
个人信息系统可以随性一点,团队知识库不行。团队知识库有协作成本、权限边界、质量责任,还会影响新人 onboarding 和工程决策。
团队里用 AI 做信息资源管理,我会特别强调三件事。
1. 先有 purpose,再有自动化
知识库要先回答"给谁用、用来干什么"。
是给新人快速上手?给值班同学查故障?给架构评审找历史决策?给 AI agent 做上下文?这些目的不同,信息结构也不同。
没有 purpose 的自动化,最后会变成很勤奋的垃圾搬运。AI 每天帮你总结一堆文档,页面越来越多,可没人知道该看哪一页。
2. 让 AI 生成,也让人 review
AI 可以生成初稿,但团队知识必须有人负责。
一个好的页面至少要有:
- owner:谁负责这页内容。
- source:依据哪些材料生成。
- updated:什么时候更新。
- confidence:可信度或状态。
- review_due:什么时候需要复查。
这几个字段看起来土,却能避免知识库变成"无人认领的正确废话"。
3. 日志和隐私要从第一天考虑
把公司内部消息、会议纪要、代码和客户反馈接入 AI 系统时,必须先想清楚边界:
- 谁有权限读取原始材料?
- AI 输出里是否可能泄露客户、员工或业务敏感信息?
- 日志里会不会留下 prompt 和原文?
- 离职人员、跨团队成员、外包同学能看到什么?
- 删除或撤回信息后,索引和缓存是否同步清理?
这些问题不性感,但很现实。知识系统一旦变成团队基础设施,安全和隐私不是最后加的补丁,而是建房子时就要打的地基。
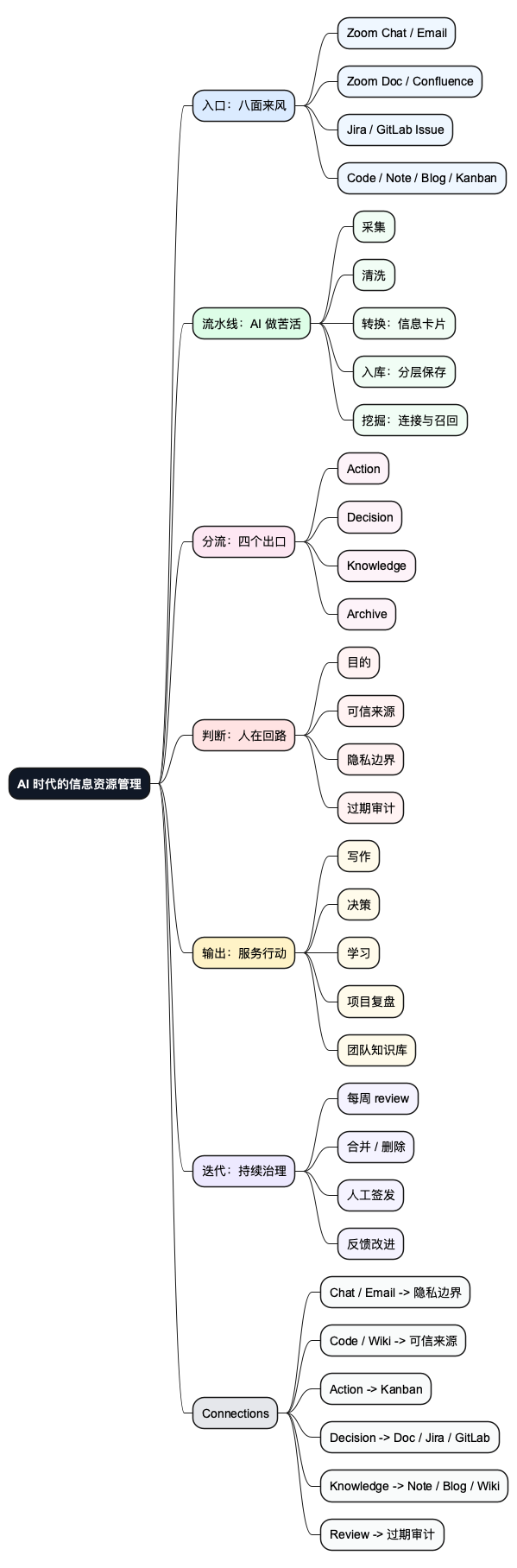
六、思维导图
下面这张图是这篇文章的骨架。PlantUML mindmap 不适合画复杂交叉线,所以我把关键关系放在 "Connections" 分支里,读起来更像一张工作台上的便签图。
@startmindmap
skinparam backgroundColor #FFFFFF
skinparam defaultFontName Arial
*[#111827] <color:white><b>AI 时代的信息资源管理</b></color>
**[#DBEAFE] 入口:八面来风
***[#EFF6FF] Zoom Chat / Email
***[#EFF6FF] Zoom Doc / Confluence
***[#EFF6FF] Jira / GitLab Issue
***[#EFF6FF] Code / Note / Blog / Kanban
**[#DCFCE7] 流水线:AI 做苦活
***[#F0FDF4] 采集
***[#F0FDF4] 清洗
***[#F0FDF4] 转换:信息卡片
***[#F0FDF4] 入库:分层保存
***[#F0FDF4] 挖掘:连接与召回
**[#FCE7F3] 分流:四个出口
***[#FDF2F8] Action
***[#FDF2F8] Decision
***[#FDF2F8] Knowledge
***[#FDF2F8] Archive
**[#FEE2E2] 判断:人在回路
***[#FEF2F2] 目的
***[#FEF2F2] 可信来源
***[#FEF2F2] 隐私边界
***[#FEF2F2] 过期审计
**[#FEF3C7] 输出:服务行动
***[#FFFBEB] 写作
***[#FFFBEB] 决策
***[#FFFBEB] 学习
***[#FFFBEB] 项目复盘
***[#FFFBEB] 团队知识库
**[#EDE9FE] 迭代:持续治理
***[#F5F3FF] 每周 review
***[#F5F3FF] 合并 / 删除
***[#F5F3FF] 人工签发
***[#F5F3FF] 反馈改进
**[#E5E7EB] Connections
***[#F9FAFB] Chat / Email -> 隐私边界
***[#F9FAFB] Code / Wiki -> 可信来源
***[#F9FAFB] Action -> Kanban
***[#F9FAFB] Decision -> Doc / Jira / GitLab
***[#F9FAFB] Knowledge -> Note / Blog / Wiki
***[#F9FAFB] Review -> 过期审计
@endmindmap
总结
信息资源管理这门老课,在 AI 时代重新变得有意思。
以前咱们靠人读、靠人摘、靠人分类、靠人回忆。现在 AI 可以帮我们采集、清洗、转换、入库和挖掘。但越是这样,越要把人的位置想清楚。
一句话:AI 可以接管信息处理的流水线,但信息价值的判断权必须留在人手里。
如果你想开始,不妨从一个很小的动作做起。
行动清单
- [ ] 给所有信息只设四个出口:Action、Decision、Knowledge、Archive。
- [ ] 每天用 15 分钟让 AI 汇总"必须处理的 5 件事",人只做取舍。
- [ ] 重要 Decision 必须回写到 Zoom Doc、Confluence、Jira 或 GitLab,不要只留在 Chat。
- [ ] 个人 kanban 只保留 Inbox、Action、Decision、Knowledge、Someday、Trash 六列。
- [ ] 每周做一次 30 分钟 review,把本周信息变成可复用资产。
- [ ] 每条重要信息至少有 source_link、owner、confidence、next_action。
- [ ] 不把敏感邮件、聊天记录、客户资料随手喂给公开 AI。
- [ ] 每个月清理一次过期信息,尤其是技术 workaround、项目状态和旧 wiki 页面。
检查清单
- [ ] Action 是否都有明确下一步,而不是一句"跟进一下"?
- [ ] Decision 是否有正式记录和来源链接?
- [ ] Knowledge 是否能在未来复用,而不是只让自己感觉"我收藏过"?
- [ ] Archive 是否真的不用处理,而不是逃避决策?
- [ ] Chat 里的临时共识是否已经转成文档、Issue 或任务?
- [ ] Jira/GitLab 状态是否比个人笔记更可信?
- [ ] 个人 note/blog 里保存的是判断和沉淀,而不是原文垃圾堆?
- [ ] AI 输出里是否区分了原文事实、模型推断和我的判断?
最后留一个问题:你现在收藏夹、笔记软件和聊天记录里,最值得被 AI "打捞"出来的那批信息,到底是为了写作、决策、学习,还是只是为了让自己感觉没有错过?
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。