用 DDD 的眼光重看 Kubernetes:一堆 YAML 背后其实是一套领域模型
Posted on 日 14 6月 2026 in Tech
| Abstract | 用 DDD 的眼光重看 Kubernetes:一堆 YAML 背后其实是一套领域模型 |
|---|---|
| Authors | Walter Fan |
| Category | Cloud / Architecture |
| Status | v1.0 |
| Updated | 2026-06-14 |
| License | CC-BY-NC-ND 4.0 |
一个被问到第三次的问题
带新人上手 Kubernetes,我几乎每次都会被问同一个问题:
"Pod、ReplicaSet、Deployment 到底啥关系?为啥一个跑容器的事,要套三层?还有 Service、Ingress、ConfigMap、Secret、PVC……这么多 kind,我是不是得全背下来?"
我早年的标准答案是:"先记住就行,用多了自然熟。" 后来发现这答案特别糟——它把 Kubernetes 讲成了一本需要死记硬背的 YAML 字典,新人学得痛苦,还学不出结构感。
直到有一次,我一边讲 kubectl get pod -o yaml,一边突然意识到一件事:Kubernetes 里几乎每个对象都长一个样子——metadata + spec + status。 这哪是什么运维工具的随意拼凑,这分明是一套被设计得相当克制的领域模型。
所以这篇我想换个讲法。我的观点是:
别把 Kubernetes 当成一堆 kind 的大杂烩去背。它是一套教科书级的 DDD(领域驱动设计)+ 声明式系统。 你把它的领域模型看懂了,那几十个对象不用背,自己就归队了。
读完你会拿到一张 DDD ↔ K8S 的对照表,理解 spec/status、reconcile、ownerReference、label selector、Namespace、CRD 这些设计背后到底在建模什么。后面你再写 Operator,会发现自己其实是在做领域建模。
注:这是一篇"换视角"的文章,不是 DDD 教程也不是 K8S 入门手册。我假设你写过几次 YAML、知道 Pod 大概是什么。DDD 的概念我会就地用大白话解释。
一、先抓住心脏:每个对象都是「期望 + 现状」
在数 kind 之前,先看一个所有人都见过、却很少有人停下来想的细节。随便 get 一个对象出来:
apiVersion: apps/v1
kind: Deployment
metadata: # 我是谁
name: web
namespace: shop
uid: 7c9e... # 全局唯一身份
labels:
app: web
spec: # 我「应该」长成什么样(期望状态)
replicas: 3
selector:
matchLabels:
app: web
status: # 我「现在」长成什么样(实际状态)
replicas: 3
availableReplicas: 2
这三段——metadata / spec / status——几乎是 Kubernetes 所有核心对象的统一骨架。用 DDD 的话翻译一下,信息量一下就出来了:
metadata是实体的标识与元信息。uid是这个实体在集群里的唯一身份;name + namespace是它在某个上下文里的可读名字;resourceVersion是乐观锁的版本号。spec是「期望状态」,本质是一条命令的意图。 你写下replicas: 3,不是在调用"创建 3 个 Pod"这个动作,而是在声明"我希望最终有 3 个"。这是声明式(declarative)和命令式(imperative)的根本区别。status是「实际状态」,由系统持续回填。 你不该去手写它,它是系统观测到的现实。
为什么说这是整个模型的心脏?因为它定义了 Kubernetes 的核心领域逻辑只有一句话:
不断地比较
spec和status,想办法让现实(status)追上期望(spec)。
这就是大名鼎鼎的 reconcile loop(调谐循环)。它不是"执行一次创建",而是"永远在收敛"。Pod 挂了,status 偏离了 spec,控制器就再拉一个起来。这套"声明期望 + 持续收敛"的思路,跟 DDD 里"用领域模型表达业务意图、把怎么实现交给领域服务"是同一种气味。
记住这个骨架,下面所有对象都挂在它上面。
小例外正好印证规律:
ConfigMap、Secret这类对象没有spec/status,只有data。因为它们根本不需要"收敛"——它们是值对象,存的就是一坨配置数据,没有"期望 vs 现实"的张力。这个反例后面还会用到。
二、用 DDD 词汇给 K8S 对象归位
抓住了骨架,接下来就是把那些让人眼花的 kind 一个个塞进 DDD 的格子里。先上总览表,再逐个掰开:
| DDD 概念 | 大白话 | 对应的 K8S 设计 |
|---|---|---|
| Entity(实体) | 有唯一标识、有生命周期 | 带 uid 的对象:Pod、Node、PVC |
| Value Object(值对象) | 无标识、不可变、按值相等 | ConfigMap/Secret 的 data、labels、资源 requests/limits |
| Aggregate(聚合) | 一组对象作为一个一致性整体 | Deployment → ReplicaSet → Pod(靠 ownerReference 串起来) |
| Aggregate Root(聚合根) | 聚合对外的唯一入口 | Pod 之于容器;Deployment 之于整条副本链 |
| Specification(规约) | 用一组条件筛选对象 | label selector(matchLabels / matchExpressions) |
| Bounded Context(限界上下文) | 模型生效的边界 | Namespace |
| Repository(仓储) | 对象的持久化与检索 | etcd + API Server |
| Domain Event(领域事件) | 模型里发生了值得关注的事 | watch / informer 的事件流 |
| Domain Service(领域服务) | 不属于单个实体的领域逻辑 | Controller 的 reconcile loop |
| Ubiquitous Language(统一语言) | 团队共享的领域词汇 | kind 名称本身;CRD 是你自定义的词汇 |
如果把这些对象画成一张类图,关系会比表格更直观——谁继承谁、谁聚合谁、谁靠规约引用谁,一眼可见:
@startuml k8s_class_diagram
skinparam linetype ortho
skinparam classAttributeIconSize 0
hide circle
abstract class KubernetesObject {
+apiVersion
+kind
+ObjectMeta metadata
}
class ObjectMeta <<ValueObject>> {
+uid : UID // 身份
+name
+namespace
+labels : Map
+ownerReferences : List
+resourceVersion // 乐观锁
}
class Namespace <<BoundedContext>> {
}
class Deployment <<AggregateRoot>> {
+spec.replicas // 期望
+spec.selector
+status // 现实
}
class ReplicaSet {
+spec.replicas
+spec.selector
+status
}
class Pod <<AggregateRoot/Entity>> {
+spec.containers
+spec.nodeName
+status.phase
}
class Container <<Entity>> {
+image
+ports
+resources : ResourceReqs
}
class Service {
+spec.selector // 规约
+spec.ports
}
class ConfigMap <<ValueObject>> {
+data : Map
}
class Secret <<ValueObject>> {
+data : Map
}
KubernetesObject *-- ObjectMeta
KubernetesObject <|-- Namespace
KubernetesObject <|-- Deployment
KubernetesObject <|-- ReplicaSet
KubernetesObject <|-- Pod
KubernetesObject <|-- Service
KubernetesObject <|-- ConfigMap
KubernetesObject <|-- Secret
Deployment "1" o-- "*" ReplicaSet : owns(ownerRef) >
ReplicaSet "1" o-- "*" Pod : owns(ownerRef) >
Pod "1" *-- "1..*" Container : contains
Service ..> Pod : selects by label\n(Specification)
Pod ..> ConfigMap : mounts/envFrom >
Pod ..> Secret : mounts/envFrom >
Namespace "1" o-- "*" KubernetesObject : scopes >
@enduml
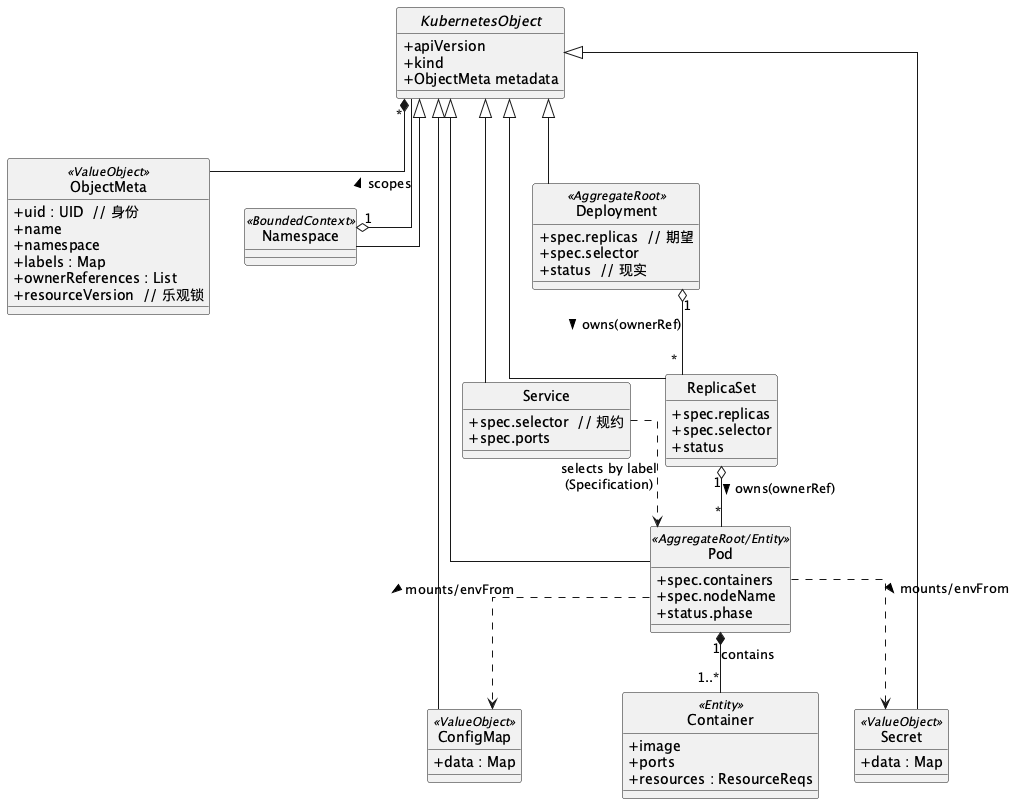
几个值得盯一眼的细节:所有对象都从 KubernetesObject 继承同一套 metadata;Deployment、ReplicaSet、Pod 之间是组合聚合(owns,靠 ownerReference 串、级联删除);Service 到 Pod 是虚线依赖(selects by label,规约而非持有);ConfigMap、Secret 是被 Pod 挂载的值对象;Namespace 则把一切圈在自己的上下文里。
下面挑几个最有"恍然大悟"价值的展开。
2.1 实体 vs 值对象:看它有没有「身份」
DDD 里区分实体和值对象,就一条:这玩意儿有没有独立身份、需不需要追踪它的一生?
- Pod 是实体。 它有
uid,有从 Pending → Running → Succeeded/Failed 的生命周期,你会一直关心"这一个 Pod"的死活。Node、PVC 同理。 - 一份资源限制
cpu: 500m, memory: 256Mi是值对象。 你不会问"这是哪一个 500m",它没有身份,只有值。两个 Pod 写一样的 limits,就是相等,没有"同一个"之说。labels 也是典型值对象——app: web这个键值对本身不需要身份。
这个区分不是咬文嚼字。它解释了一个新人常踩的坑:为什么改 Pod 名字等于换一个 Pod,而改 label 只是改它的属性? 因为名字关联身份,label 只是值。
2.2 聚合与聚合根:三层套娃终于讲通了
回到开头那个"为啥要套三层"的问题。用聚合根的视角,这事一秒钟讲明白。
DDD 里,聚合是一组必须一起保持一致的对象,聚合根是外界唯一能直接操作的入口——你不能绕过根去戳聚合内部的零件。
Kubernetes 里这套关系是用 ownerReference(属主引用) 实体化的:
Deployment(聚合根:管版本与滚动发布)
└─ ownerReference ─▶ ReplicaSet(管"某一版本"的副本数)
└─ ownerReference ─▶ Pod(真正跑容器的实体)
- 你只对 Deployment 下命令(改镜像、改副本数),这就是"只通过聚合根操作"。
- ReplicaSet 是中间那层"版本快照",让滚动升级和回滚有地方落脚——它不是冗余,是为了把"副本数"和"版本"两件事拆开。
- 删掉 Deployment,下面的 ReplicaSet 和 Pod 会级联删除。这就是 DDD 说的聚合的一致性边界:聚合根没了,整个聚合一起消失。Kubernetes 的垃圾回收(garbage collection)正是顺着
ownerReference这条链做的。
而 Pod 自己又是一个聚合根——它聚合了一个或多个容器、共享网络和存储卷。容器在 K8S 里压根不是独立的 API 对象,你 get 不到一个单独的容器,只能通过 Pod 这个根去访问。这就是"聚合内部零件不直接对外暴露"的教科书示范。
一句话记住:Deployment 管"哪个版本、几个副本",ReplicaSet 管"这一版本的副本",Pod 管"这一组容器"。 三层不是啰嗦,是三个不同的一致性边界。
2.3 规约模式:label selector 就是 Specification
这个对应关系,我第一次反应过来时是真有点惊喜。
DDD 里有个规约(Specification)模式:把"什么样的对象符合条件"封装成一个可组合的判断,而不是硬编码 ID 列表。好处是松耦合——筛选方不需要知道被筛选方是谁,只描述"长什么样的我都要"。
Kubernetes 的 label selector 就是规约模式的活体标本:
# Service 不点名要哪几个 Pod,它只描述「条件」
selector:
app: web
tier: frontend
Service 从不持有 Pod 的名字或 IP 列表,它只声明一条规约:"凡是带 app=web 且 tier=frontend 的 Pod,都算我的后端。" 新 Pod 起来、带上这俩 label,自动入列;旧 Pod 挂掉,自动出列。ReplicaSet 用 selector 认领自己该管的 Pod,NetworkPolicy 用 selector 圈定作用范围,全是同一招。
这种"按特征匹配、而非按身份点名"的设计,正是 K8S 能做到松耦合、动态伸缩的根。matchExpressions(支持 In、NotIn、Exists)则是规约的"可组合"那一面。
2.4 限界上下文:Namespace 就是那道墙
DDD 里最重要也最常被忽略的概念是限界上下文:同一个词在不同上下文里可以是不同的东西,边界之内模型自洽,边界之间靠明确的契约打交道。
Namespace 就是 Kubernetes 的限界上下文。
- 同名不冲突:
shop里的web和blog里的web是两个 Service,名字一样、互不干扰。这正是"同一个词在不同上下文里是不同实体"。 - 边界即治理单元:ResourceQuota、RBAC 的 RoleBinding、NetworkPolicy,大多以 Namespace 为单位划线。权限、配额、网络策略,都在这道墙上贴。
- 跨边界要走契约:A namespace 的服务访问 B namespace,得走
service.b-namespace.svc这种带上下文的全名,而不是直接喊名字。
所以那句运维老话"先规划好 namespace 再上业务",本质是 DDD 的"先划清限界上下文"。Namespace 划错了,后面权限和配额就全是补丁。
2.5 仓储、领域事件、领域服务:跑起来的那部分
剩下三个概念,串起来就是 Kubernetes 的运行时:
- Repository(仓储)= etcd + API Server。 所有对象的唯一事实来源(source of truth)是 etcd,但你永远不直接碰 etcd——你只跟 API Server 打交道。API Server 负责校验、鉴权、版本控制,再落库。这正是仓储模式要的:"给我一个干净的存取门面,别让领域逻辑直接趴在数据库上。"
- Domain Event(领域事件)= watch 事件流。 控制器不靠轮询,而是
watchAPI Server,对象一有增删改就推一个事件过来(informer 机制)。"Pod 被删除了""Deployment 的 spec 变了"——这些就是领域事件,驱动着整个系统响应。 - Domain Service(领域服务)= Controller 的 reconcile。 "保证副本数等于期望值"这个逻辑,不属于 Pod,也不属于 ReplicaSet 单个实体,它是跨实体的领域逻辑——于是它住在 Controller 里。每个控制器盯着一类对象,收到事件就跑一遍 reconcile,把现实往期望上拽。这就是 DDD 里"无法归属到某个实体的领域逻辑,单独抽成领域服务"。
到这儿,那张对照表的每一格都填上了。Kubernetes 不是一堆 kind,它是一个声明式领域模型 + 一组守着它的领域服务。
三、串一遍:kubectl apply 背后的一次「领域旅程」
光有静态对照还不过瘾,我们把上面的概念用一次 kubectl apply -f web-deploy.yaml 串起来,看一条命令是怎么在这套模型里流动的:
1. kubectl 把 YAML 提交给 API Server(仓储门面)
2. API Server 校验 + 鉴权 + 默认值填充,把 Deployment 对象写进 etcd
—— 一个聚合根的「期望状态(spec)」落库了
3. etcd 的变更触发 watch 事件(领域事件)
4. Deployment Controller 收到事件 → reconcile(领域服务):
发现没有对应版本的 ReplicaSet,于是创建一个 ReplicaSet,
并打上 ownerReference 指回自己(构建聚合)
5. ReplicaSet Controller 又收到事件 → reconcile:
发现 status.replicas=0 但 spec.replicas=3,于是创建 3 个 Pod
6. Scheduler 收到「未绑定 Node 的 Pod」事件 → 用一套规约
(资源、亲和性、污点容忍)挑 Node,写回 pod.spec.nodeName
7. 目标 Node 上的 kubelet 收到事件 → 真正拉起容器,
并把观测到的现实回填进 pod.status
8. 各级 status 一路向上汇聚,直到 Deployment.status 追上 spec —— 收敛完成
注意这一路上没有任何一步是"命令式地执行创建"。每个组件都只做一件事:盯着自己关心的对象,发现"期望 ≠ 现实",就往前推一步。整个系统是一群各管一摊的领域服务,围着同一个仓储,靠事件驱动,各自把现实往期望上拽。
这也解释了 Kubernetes 那个让人又爱又恨的特性:自愈。你手动 kill 一个 Pod,status 偏离 spec,事件一发,ReplicaSet Controller 立刻补一个。你不是在跟一个执行了就结束的脚本打交道,你是在跟一个永远在收敛的领域模型打交道。理解这点,你就不会再写出"为什么我删了 Pod 它又自己回来了"这种工单了。
四、这套视角真正的回报:写 CRD / Operator 时你在做领域建模
前面都是"重新理解已有的对象",听起来像是事后强行套理论。但这套视角有个非常实在的回报:当你写 CRD(自定义资源)和 Operator 时,你做的事情,本质就是 DDD 建模。
CRD 让你往 Kubernetes 里注册自己的 kind。比如你做一个数据库中间件,定义一个 kind: PostgresCluster。这一刻发生的事,用 DDD 来说是:
- 你在扩展统一语言(Ubiquitous Language)。
PostgresCluster成了集群里和 Pod、Service 平起平坐的一等公民,运维、开发、控制器都用这个词交流。 - 你在定义一个聚合根。 一个
PostgresCluster聚合了它的 StatefulSet、Service、Secret、PVC——用户只跟这个根打交道,不用手动拼下面那一堆。 - 你必须设计
spec和status。spec是用户能声明的期望(版本、副本数、存储大小),status是你的控制器回填的现实(当前主节点、就绪副本、同步延迟)。这一步就是领域建模里最关键的"区分意图与现实"。 - 你写的 Operator 就是领域服务。 它 watch 自己的 CRD,reconcile,把"用户想要一个三节点 Postgres 集群"翻译成一连串具体动作。
所以,设计一个好的 CRD,和设计一个好的聚合,是同一件事。我自己踩过坑后总结的几条原则,给你抄作业:
spec只放用户的意图,别放实现细节。 用户该声明"我要 3 个副本",不该被迫填"用哪个 StatefulSet 名字"。实现细节是聚合内部的事。- 绝不让用户写
status,也别把意图塞进status。status是控制器的单向输出。这条边界一旦破了,期望和现实就纠缠不清,reconcile 逻辑会变成一团乱麻。 - 一个 CRD 一个清晰的一致性边界。 别贪心把八竿子打不着的东西塞进一个聚合根。聚合太大,reconcile 就慢且脆;聚合太碎,又得自己处理跨聚合一致性。这个取舍,和 DDD 里"聚合该多大"是同一道题。
- reconcile 要写成幂等的、可重入的。 它随时可能被重复触发(这正是声明式的要求)。每次都从"当前现实"出发去逼近"期望",而不是假设"上次执行到哪了"。
一句话:Kubernetes 把 DDD 的一套词汇做成了可运行的平台。你写 Operator,就是在这个平台上建你自己的领域模型。
五、别把类比用过头:哪些是「神似」,哪些只是「形似」
我得给前面这套对应关系泼盆冷水。类比是用来"快速进入状态"的脚手架,不是用来"证明 Kubernetes 等于 DDD"的。下面几处,分清神似和形似,免得你哪天拿着锤子看什么都是钉子:
- K8S 没有 DDD 那种强事务聚合。 DDD 经典做法里,一个聚合的修改是一个事务,要么全成要么全败。但 Kubernetes 是最终一致的:你改了 Deployment 的 spec,下面的 Pod 不会原子地一起变,而是被 reconcile 逐步带过去。中间一定存在"现实还没追上期望"的窗口。这是分布式系统的现实妥协,不是 bug。
- Service 的"聚合根"成分更像工程抽象。 Service 背后其实还有 EndpointSlice、kube-proxy 维护的 iptables/IPVS 规则。说它是"按规约选 Pod 的入口"是神似;但它内部那套转发实现,是纯工程,硬套 DDD 反而别扭。
- 不是每个对象都严丝合缝地落进一个格子。 像
Event、Lease这类对象,更多是运维基础设施,你非要给它安一个"是实体还是值对象"的名分,纯属自寻烦恼。 - 声明式 ≠ DDD。 声明式 API 是 K8S 的工程选择,DDD 是一种建模方法论,两者气质相投但不是一回事。我用 DDD 讲 K8S,是因为这套词汇好用、能让对象归位,而不是说 Google 当年是照着《领域驱动设计》那本书写的 Kubernetes。
记住一句老话:所有模型都是错的,但有些是有用的。 这套 DDD 视角的价值,在于让你从"背 kind"升级到"看结构",而不是给 Kubernetes 颁一张 DDD 认证。
收束:从背名词,到看模型
回到开头那个被问到第三次的问题。现在我的答案不再是"先记住就行",而是会先在白板上画三样东西:
- 画那个统一骨架:
metadata(我是谁)+spec(我想成为谁)+status(我现在是谁)。 - 画那条聚合链:Deployment → ReplicaSet → Pod,标上 ownerReference 和级联删除。
- 画那个收敛循环:watch 事件 → controller reconcile → 把 status 往 spec 上拽。
画完这三张图,新人通常就不再问"要不要背了"。因为他看到了:那几十个 kind 不是平铺的字典词条,而是挂在同一套领域模型上的不同角色——有的是实体,有的是值对象,有的是聚合根,有的是守着模型的领域服务。
学 Kubernetes 的分水岭,是从"这是哪个 kind、字段怎么填",切换到"这是模型里的哪个角色、它在收敛什么"。 跨过这道坎,YAML 就不再是需要死记的咒语,而是你跟一套领域模型对话的语言。
DDD 当年想解决的问题是"让代码结构长得像业务";Kubernetes 解决的问题是"让基础设施的状态长得像你的声明"。一个在应用层,一个在平台层,但都是同一个信念:先把领域建模清楚,再谈实现。 这大概就是好系统共通的体面。
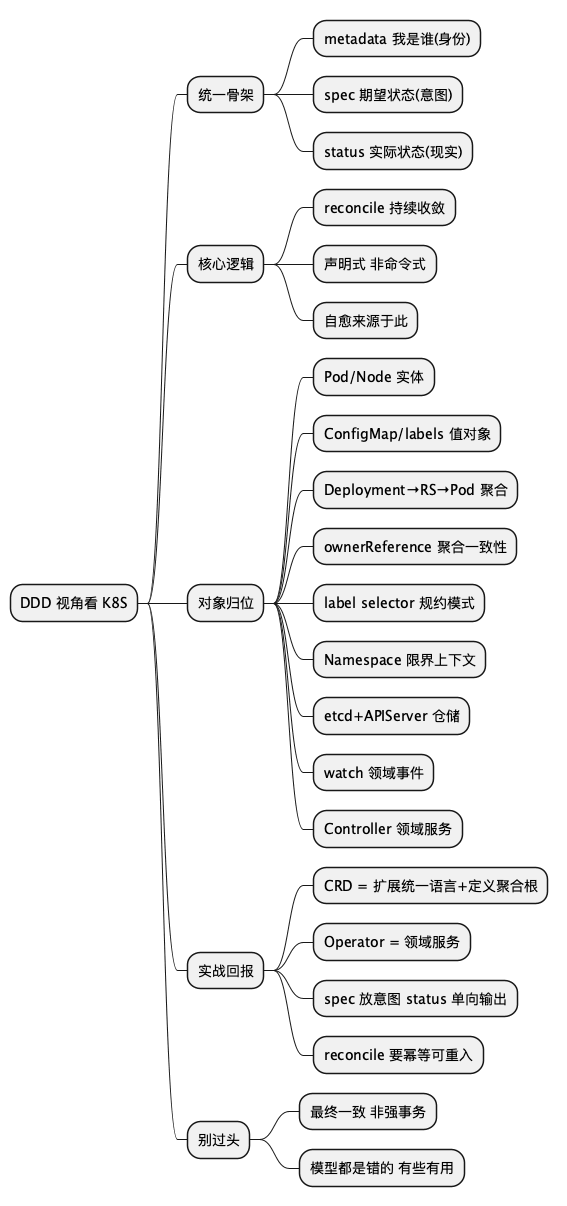
总结脑图
@startmindmap k8s_ddd_mindmap
* DDD 视角看 K8S
** 统一骨架
*** metadata 我是谁(身份)
*** spec 期望状态(意图)
*** status 实际状态(现实)
** 核心逻辑
*** reconcile 持续收敛
*** 声明式 非命令式
*** 自愈来源于此
** 对象归位
*** Pod/Node 实体
*** ConfigMap/labels 值对象
*** Deployment→RS→Pod 聚合
*** ownerReference 聚合一致性
*** label selector 规约模式
*** Namespace 限界上下文
*** etcd+APIServer 仓储
*** watch 领域事件
*** Controller 领域服务
** 实战回报
*** CRD = 扩展统一语言+定义聚合根
*** Operator = 领域服务
*** spec 放意图 status 单向输出
*** reconcile 要幂等可重入
** 别过头
*** 最终一致 非强事务
*** 模型都是错的 有些有用
@endmindmap
行动清单
- 随手
kubectl get <任意对象> -o yaml,盯着metadata/spec/status三段看,把它在心里翻译成"身份 / 意图 / 现实"。 - 给你正在维护的一个业务,画一遍它的聚合链:哪个是聚合根?删它的时候谁会被级联带走?
- 找一个 Service,确认它是靠 label selector(规约)认 Pod,而不是写死 IP——理解松耦合从哪来。
- 复盘你们的 Namespace 划分:是按"限界上下文"划的,还是随手拍的?权限和配额贴在这道墙上合理吗?
- 如果你写过或要写 CRD:检查
spec里有没有混进实现细节,status是不是被谁手写污染了,reconcile 是不是幂等的。
扩展阅读
- Kubernetes API Conventions(spec/status、ownerReference 的官方约定)
- Kubernetes 官方文档:Controllers 与控制循环
- Operator 模式(Kubernetes 官方)
- Eric Evans,《领域驱动设计》——聚合、限界上下文、统一语言的源头
- 授权的领域模型:从 RBAC、ABAC 到 Keycloak、Vault 的一张全景图
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。