职场工具箱之 RICE / ICE:如何把优先级从"拍脑袋"变成"可讨论"?
Posted on 一 09 3月 2026 in Journal
| Abstract | 职场工具箱之 RICE / ICE:把优先级从拍脑袋变成可讨论 |
|---|---|
| Authors | Walter Fan |
| Category | Journal |
| Version | v1.0 |
| Updated | 2026-03-06 |
| License | CC-BY-NC-ND 4.0 |
简短大纲
展开看看
- **扎心场景**:排优先级变成"谁嗓门大谁赢" - **What**:RICE 是什么(Reach × Impact × Confidence / Effort);ICE 是什么(Impact × Confidence × Ease) - **公式详解**:每个维度怎么打分,RICE vs ICE 对比表 - **Why**:为什么需要量化优先级——锚定效应、声音大≠价值大、量化不是为了精确而是为了"可讨论" - **How**:三个实战场景改写(需求排序会 / 技术债评估 / 季度规划),❌ 拍脑袋版 vs ✅ RICE/ICE 版 - **打分示例表格 + 技术人常踩的坑** - **总结 + 行动清单 + 思维导图 + 系列回顾 + 扩展阅读**1. 扎心场景:排优先级变成"谁嗓门大谁赢"
你一定经历过这种会。
产品经理拉了一个"需求排序会",白板上列了 12 条需求,每条后面标着"高""中""低"。
然后讨论开始了:
PM A:"用户反馈最多的是导出功能,必须排第一。" PM B:"老板上周说了,国际化是战略方向,这个优先级最高。" 工程师 C:"你们说的都对,但技术债再不还,下个月线上就要炸。" 老板(路过):"那个大客户的定制需求呢?合同都签了。"
四个人,四个"最高优先级"。
最后怎么收场的?通常是这样:
- 声音最大的人赢了
- 或者老板最后一句话赢了
- 或者"都很重要,都做吧"(然后谁都做不完)
你有没有发现:整场讨论里没有一个人说出过"为什么 A 比 B 重要"的具体理由。 大家都在用"我觉得""用户反馈""老板说了"这种模糊的锚点来争夺优先级。
这不是讨论,这是拔河。
我在外企这些年,参加过无数次这种会。有一段时间我甚至总结出一条规律:需求排序会的时长,跟最终结论的质量成反比。 开得越久,说明分歧越大;分歧越大,最后越容易靠"谁扛不住谁让步"来收场。
后来我学到了 RICE 和 ICE,才发现:问题不在于大家意见不同,而在于大家连"用什么标准比较"都没对齐。
你说"用户反馈多",我说"战略方向重要",他说"技术风险高"——三个人在三个维度上各说各话,当然吵不出结果。
RICE 和 ICE 干的事很简单:给你一把统一的尺子。 不是为了量出"唯一正确答案",而是让所有人先站到同一个坐标系里,再开始讨论。
2. What:RICE 和 ICE 到底是什么?
2.1 RICE:Intercom 发明的"四维打分法"
RICE 最早由 Intercom(一家做客户沟通平台的公司)提出,用来给产品需求排优先级。公式长这样:
RICE Score = (Reach × Impact × Confidence) / Effort
四个维度分别是:
| 维度 | 含义 | 怎么打分 | 举例 |
|---|---|---|---|
| R — Reach(触达) | 这个需求在一定时间内能影响多少用户/客户? | 用具体数字:人数、请求数、订单数等 | "每月 5000 个用户会用到导出功能" |
| I — Impact(影响) | 对每个被触达的用户,影响有多大? | 用等级:3=巨大 / 2=高 / 1=中 / 0.5=低 / 0.25=极低 | "导出功能能把用户留存率提升一个档次" → 2 |
| C — Confidence(信心) | 你对上面这些估算有多大把握? | 百分比:100%=有数据支撑 / 80%=有强信号 / 50%=直觉 / 20%=纯猜 | "有用户调研数据支撑" → 80% |
| E — Effort(投入) | 需要多少人月(或人周)? | 用"人月"为单位,越大越不划算 | "需要 2 个工程师做 3 周" → 1.5 人月 |
小白提示:人月(person-month) 是衡量工作量的单位。1 人月 = 1 个人全职干 1 个月。2 个人干 3 周 ≈ 1.5 人月。注意:人月不等于日历时间——3 个人干 1 个月不等于 1 个人干 3 个月,《人月神话》早就说过这事。
算一个例子:
- Reach = 5000 用户/月
- Impact = 2(高)
- Confidence = 80%
- Effort = 1.5 人月
RICE = (5000 × 2 × 0.8) / 1.5 = 5333
这个数字本身没有绝对意义——它的价值在于跟其他需求的分数放在一起比较。
2.2 ICE:更轻量的"三维快评"
ICE 是 Sean Ellis(增长黑客概念的提出者)推广的一个更简单的评分模型,常用于增长实验和快速迭代场景:
ICE Score = Impact × Confidence × Ease
三个维度:
| 维度 | 含义 | 怎么打分 |
|---|---|---|
| I — Impact(影响) | 如果做成了,对目标指标的影响有多大? | 1-10 分 |
| C — Confidence(信心) | 你对"做成"这件事有多大把握? | 1-10 分 |
| E — Ease(容易度) | 实现起来有多容易? | 1-10 分(10=最容易) |
注意:ICE 里的 E 是 Ease(容易度),不是 Effort(投入)。方向是反的——Ease 越高越好,Effort 越低越好。别搞混了。
算一个例子:
- Impact = 8
- Confidence = 6
- Ease = 4
ICE = 8 × 6 × 4 = 192
同样,这个数字只有在跟其他候选项放在一起时才有意义。
2.3 RICE vs ICE:什么时候用哪个?
| 对比维度 | RICE | ICE |
|---|---|---|
| 维度数 | 4 个(Reach / Impact / Confidence / Effort) | 3 个(Impact / Confidence / Ease) |
| 复杂度 | 中等,需要估算 Reach 和 Effort 的具体数字 | 低,全部用 1-10 打分 |
| 适合场景 | 产品需求排序、季度规划、有用户数据支撑时 | 增长实验、快速迭代、早期探索、技术债评估 |
| 优势 | Reach 维度让你不会忽略"影响面";Effort 用具体数字更客观 | 上手快、5 分钟能打完一轮分;适合团队快速对齐 |
| 劣势 | Reach 和 Effort 估不准时,公式会放大误差 | 全靠主观打分,容易"用公式掩盖拍脑袋" |
| 谁发明的 | Intercom | Sean Ellis(增长黑客) |
我的经验法则:
- 需求 > 10 条、有用户数据、要跟老板汇报 → 用 RICE(更严谨,数字更有说服力)
- 需求 < 10 条、团队内部快速对齐、增长实验 → 用 ICE(更快,5 分钟搞定)
- 不确定用哪个 → 先用 ICE 快速过一遍,争议大的再用 RICE 细算
3. Why:为什么需要量化优先级?
你可能会说:"打分不也是拍脑袋吗?Impact 给 8 分还是 7 分,不还是主观的?"
没错。但这里有一个关键区别:
拍脑袋是"我觉得 A 比 B 重要"——你不知道他在哪个维度上觉得重要。
打分是"我在 Impact 上给 A 打 8 分、给 B 打 6 分"——你知道他在哪个维度上有分歧,可以针对性地讨论。
这就是量化的真正价值:不是为了精确,是为了"可讨论"。
3.1 锚定效应:谁先开口,谁就定了基调
心理学里有个概念叫锚定效应(Anchoring Effect):人在做判断时,会不自觉地被最先接收到的信息"锚住"。
小白提示:锚定效应 就是"先入为主"的学术版。比如你去买衣服,店员先说"原价 2000",再说"打折 800",你就觉得 800 很便宜——但如果他一开口就说 800,你可能觉得贵。那个"2000"就是锚。
在需求排序会上,锚定效应无处不在:
- 老板先说了一句"国际化很重要",后面所有人都不好意思把国际化排到后面
- PM 先说了"用户反馈最多的是 X",大家就默认 X 是最重要的
- 工程师先说了"技术债要炸了",气氛瞬间紧张,其他需求都显得不那么急
谁先开口,谁就设了锚。 后面的讨论不是在"独立判断",而是在"围绕锚点微调"。
RICE/ICE 的打分机制可以部分对抗锚定效应:每个人先独立打分,再一起看分数。 这样至少能避免"谁先开口谁赢"的局面。
3.2 声音大 ≠ 价值大
这是职场里最常见的认知偏差之一。
有些人天生表达能力强、善于讲故事、情绪感染力强——他说"这个需求很重要"的时候,你会不自觉地被说服。但"说得好"和"真的重要"是两回事。
我见过一个经典案例:某次季度规划会上,一个 PM 用了 15 分钟讲了一个客户故事,声情并茂,全场动容。最后大家一致同意把这个需求排到 P0。
三个月后复盘:这个需求上线后,日活用户只有 23 个。
如果当时用 RICE 打过分,Reach 那一栏就会暴露问题:这个需求的触达面极小。 故事再感人,也改变不了"只有 23 个人用"这个事实。
3.3 量化是"翻译器",不是"计算器"
我特别想强调这一点:RICE/ICE 不是为了算出一个"唯一正确答案"。
它的真正作用是当一个翻译器——把不同人脑子里模糊的"我觉得重要"翻译成可以对比的维度和数字。
- PM 说"用户反馈多" → 翻译成 Reach = 5000
- 工程师说"技术债要炸" → 翻译成 Impact = 3(巨大)+ Confidence = 50%(不确定什么时候炸)
- 老板说"战略方向" → 翻译成 Impact = 2 + Reach = ?(到底影响多少用户?)
一旦翻译成数字,你就能问出真正有价值的问题:
- "你说 Reach 是 5000,这个数据从哪来的?"
- "你给 Confidence 打了 50%,是因为缺什么数据?能不能花半天补上?"
- "你说 Effort 是 3 人月,这个估算包含联调和测试吗?"
这些问题,比"你觉得重要不重要"有用一万倍。
4. How:实战怎么用
光讲理论没用,下面我用三个真实场景演示:拍脑袋版 vs RICE/ICE 版,你直接抄。
场景 1:需求排序会——12 条需求怎么排?
❌ 拍脑袋版
白板上列了 12 条需求,每条后面标着"高/中/低"。讨论了 90 分钟,最后:
- 6 条标"高"
- 4 条标"中"
- 2 条标"低"
然后 PM 说:"高优先级的都做吧。"工程师说:"做不完。"PM 说:"那你们评估一下哪些能砍。"
又开了一个会。
✅ RICE 版
会前 30 分钟,PM 把 12 条需求填进一张表,每条需求的 Reach 和 Effort 先估一个初始值(不用精确,量级对就行)。会上,团队一起校准 Impact 和 Confidence。
| 需求 | Reach(用户/月) | Impact(1-3) | Confidence | Effort(人月) | RICE Score | 排名 |
|---|---|---|---|---|---|---|
| 导出功能 | 5000 | 2 | 80% | 1.5 | 5333 | 1 |
| 国际化-日语 | 2000 | 2 | 60% | 3 | 800 | 4 |
| 大客户定制 | 50 | 3 | 90% | 2 | 68 | 6 |
| 搜索优化 | 8000 | 1 | 70% | 0.5 | 11200 | ★ |
| 技术债-DB 迁移 | 10000 | 2 | 50% | 4 | 2500 | 2 |
| 新手引导 | 3000 | 1 | 40% | 1 | 1200 | 3 |
看到了吗?
- 搜索优化分数最高——Reach 大、Effort 小,性价比极高。但在拍脑袋版里,它可能被"国际化是战略方向"压下去了。
- 大客户定制分数很低——虽然 Impact 高、Confidence 高,但 Reach 只有 50 个用户。"合同都签了"是商务压力,不是产品优先级。
- 技术债的 Confidence 只有 50%——说明团队对"什么时候会炸"没有把握。这时候正确的做法不是"赌一把先不还",而是花半天时间把 Confidence 提上去(比如跑一次压测、查一下历史故障率)。
关键点:分数不是结论,分数是讨论的起点。
你可以说"大客户定制虽然 RICE 分低,但合同违约有法律风险,需要单独评估"——这完全合理。但至少你现在知道:你是在"例外处理",不是在"拍脑袋"。
场景 2:技术债评估——还是不还?
技术债是工程师心里永远的痛。你知道它在那里,你知道它迟早要炸,但你说不清"到底有多紧急"。
❌ 拍脑袋版
工程师:"这个技术债必须还了,不然迟早出事。" PM:"'迟早'是什么时候?下个月?明年?" 工程师:"……说不准。" PM:"那先做业务需求吧。"
三个月后,线上故障,P0 事故,全员加班。
✅ ICE 版
技术债不像产品需求那样有明确的 Reach 数据,所以用 ICE 更合适——快、轻、够用。
| 技术债 | Impact(1-10) | Confidence(1-10) | Ease(1-10) | ICE Score | 排名 |
|---|---|---|---|---|---|
| DB 慢查询优化 | 8 | 7 | 6 | 336 | 1 |
| 日志系统升级 | 5 | 8 | 7 | 280 | 2 |
| 老 API 下线 | 7 | 4 | 3 | 84 | 4 |
| 依赖库升级 | 6 | 6 | 8 | 288 | ★ |
| 单元测试补全 | 4 | 9 | 5 | 180 | 3 |
几个有意思的发现:
- 依赖库升级分数意外地高——因为 Ease 很高(大部分是机械性工作),而且 Confidence 也不错(升级路径清晰)。这种"低风险高确定性"的技术债,最适合见缝插针地还。
- 老 API 下线分数最低——不是因为不重要,而是 Confidence 和 Ease 都很低(不知道还有谁在调、下线影响面不清楚)。正确的做法是:先花时间把 Confidence 提上去(比如加调用监控、统计下游依赖),再决定要不要动。
- DB 慢查询优化排第一——Impact 高(直接影响用户体验)、Confidence 高(瓶颈已经定位到了)、Ease 中等(需要改索引和查询逻辑,但不涉及架构变更)。
小白提示:技术债(Technical Debt) 就像信用卡欠款——你为了赶进度走了捷径(比如硬编码、跳过测试、用临时方案),短期省了时间,但长期要还"利息"(维护成本越来越高、bug 越来越多、新功能越来越难加)。
场景 3:季度规划——老板要你排 Top 5
季度规划是 RICE 最能发挥价值的场景,因为你需要跟老板、跟其他团队"讲道理"。
❌ 拍脑袋版
你:"我们 Q2 打算做这 5 件事。" 老板:"为什么是这 5 件?" 你:"……因为我们觉得这些最重要。" 老板:"'觉得'?"
✅ RICE 版
你把所有候选需求(假设 20 条)都用 RICE 打了分,然后按分数排序,取 Top 5。汇报的时候你可以这么说:
"我们用 RICE 模型对 20 条候选需求做了评分。这是完整的打分表(附件)。Top 5 如下:
- 搜索优化(RICE: 11200)——Reach 最大、Effort 最小,性价比最高
- 导出功能(RICE: 5333)——用户反馈 Top 1,Confidence 有调研数据支撑
- DB 迁移(RICE: 2500)——Confidence 只有 50%,但一旦出事影响全站;我们计划先花 2 天做压测把 Confidence 提到 80%,再决定排期
- 新手引导(RICE: 1200)——Reach 中等,但对新用户转化率影响大
- 国际化-日语(RICE: 800)——战略方向,但 Confidence 偏低(日本市场数据不足),建议先做用户调研再投入
被排到 Top 5 之外的需求里,有两条需要特别说明: - 大客户定制(RICE: 68):分数低是因为 Reach 只有 50 人,但有合同约束,建议单独立项、不占主线排期 - 老 API 下线(ICE: 84):Confidence 太低,本季度先做调用监控,下季度再决定"
看到了吗?你不是在"汇报结论",你是在"展示思考过程"。 老板看到的不是"你觉得",而是"你怎么想的、数据从哪来的、哪些地方你自己也不确定"。
这比任何 PPT 都有说服力。
5. 打分实战:一张表搞定
下面是一个完整的 RICE + ICE 混合打分表模板,你可以直接复制到 Google Sheets 或飞书表格里用:
| # | 需求/任务 | 类型 | Reach | Impact | Confidence | Effort/Ease | Score | 模型 | 备注 |
|---|---|---|---|---|---|---|---|---|---|
| 1 | 搜索优化 | 产品 | 8000 | 1 | 70% | 0.5 人月 | 11200 | RICE | 性价比最高 |
| 2 | 导出功能 | 产品 | 5000 | 2 | 80% | 1.5 人月 | 5333 | RICE | 用户调研支撑 |
| 3 | DB 迁移 | 技术债 | — | 8 | 5 | 4 | 160 | ICE | 先做压测提 Confidence |
| 4 | 依赖库升级 | 技术债 | — | 6 | 6 | 8 | 288 | ICE | 见缝插针 |
| 5 | 国际化-日语 | 产品 | 2000 | 2 | 60% | 3 人月 | 800 | RICE | 需补市场数据 |
使用建议:
- 产品需求用 RICE(因为通常有 Reach 数据)
- 技术债/内部改进用 ICE(因为 Reach 不好量化)
- 两种分数不要直接比较(量纲不同),分开排序后再合并讨论
- 每次打分前先对齐"Impact 的 10 分到底长什么样"——否则有人的 8 分是别人的 5 分
6. 技术人常踩的坑(别问我怎么知道的)
坑 1:过度精确——"Impact 到底是 7.3 还是 7.5?"
我见过有人在 ICE 打分时纠结"这个到底是 7 分还是 8 分",讨论了 10 分钟。
兄弟,这是 1-10 的主观打分,不是高考数学。差 1 分不影响排序的话,就别纠结了。 RICE/ICE 的精度是"量级对"就够了——你要区分的是"这个需求是 Top 3 还是 Bottom 3",不是"它到底排第 4 还是第 5"。
一个实用的技巧:先用"高/中/低"三档粗排,再在同一档内用分数细排。 这样能避免在不重要的分数差异上浪费时间。
坑 2:忽略 Confidence——"我觉得 Impact 很大"
Confidence 是 RICE/ICE 里最容易被忽略、但最有价值的维度。
为什么?因为它逼你回答一个灵魂拷问:"你凭什么这么说?"
- Impact = 9,Confidence = 90% → 你有数据、有案例、有用户调研 → 靠谱
- Impact = 9,Confidence = 30% → 你在猜 → 不靠谱
同样是 Impact 9 分,乘上 Confidence 之后,前者是 8.1,后者是 2.7。差了 3 倍。
Confidence 低不是坏事,它是一个信号:你需要先投入时间去验证,而不是直接投入资源去开发。
我见过最聪明的用法是:把 Confidence < 50% 的需求单独拎出来,不排优先级,而是排"验证优先级"——先花最小的成本把 Confidence 提上去,再决定做不做。
这就像写代码:你不会在没跑过测试的情况下直接部署到生产环境。Confidence 就是你的测试覆盖率。
坑 3:Effort 估不准——"2 周还是 2 个月?"
Effort 是 RICE 公式里的分母,估不准的话,整个分数都会失真。
几个常见的估算陷阱:
- 只算开发时间,不算联调/测试/上线:实际 Effort 通常是"纯开发时间"的 1.5-2 倍
- 没考虑上下文切换成本:一个人同时做 3 个需求,每个需求的实际 Effort 都会膨胀
- 乐观偏差:工程师天生倾向于低估 Effort("应该不难吧")
小白提示:乐观偏差(Optimism Bias) 是人类的一种认知偏差——我们倾向于高估好事发生的概率、低估坏事发生的概率。在估算工期时,这种偏差尤其明显:你总觉得"这次不会出意外",但意外从来不会缺席。
我的做法是:Effort 估完之后,乘以 1.5 作为"现实系数"。 如果你的团队历史上经常延期,乘以 2 也不过分。
另一个技巧:用历史数据校准。 上个季度类似规模的需求实际花了多久?把这个数字拿出来,比"拍脑袋估"靠谱得多。
坑 4:用公式掩盖拍脑袋
这是最隐蔽的坑。
有些人学了 RICE/ICE 之后,会先在心里定好"我想做 A",然后反过来调分数,让 A 的 RICE 分数恰好最高。
这叫"结论先行,数据配合"——本质上还是拍脑袋,只不过穿了一件数学外衣。
怎么防?两个办法:
- 多人独立打分,取平均值。 一个人的偏见可以被其他人的判断稀释。
- 打分和排序分两步。 先让所有人打完分、锁定分数,再一起看排序结果。不允许"看到排序不满意就回去改分"。
坑 5:打完分就完事了
RICE/ICE 打分不是一次性的。
需求的 Reach 会变(用户增长了)、Impact 会变(市场环境变了)、Confidence 会变(拿到了新数据)、Effort 会变(技术方案调整了)。
建议每个季度重新打一次分。 上个季度的 Top 1,这个季度可能已经不是了。
7. RICE/ICE 与 MoSCoW 的关系
如果你读过这个系列的上一篇 MoSCoW 优先级,你可能会问:MoSCoW 和 RICE/ICE 有什么区别?能一起用吗?
简单说:
- MoSCoW 是"分类"——把需求分成 Must/Should/Could/Won't 四个桶
- RICE/ICE 是"排序"——在同一个桶里,谁排前面谁排后面
它们是互补的,不是互斥的。
一个常见的组合用法:
- 先用 MoSCoW 做粗分类:哪些是 Must(必须做),哪些是 Should(应该做),哪些是 Could(可以做)
- 再用 RICE/ICE 在 Should 和 Could 里做细排序:资源有限时,Should 里先做哪个?Could 里哪个性价比最高?
Must 通常不需要排序(因为"必须做"就是必须做),Won't 也不需要(因为不做)。真正需要 RICE/ICE 的,是 Should 和 Could 这两个"灰色地带"。
总结:RICE/ICE 不是答案,是对话的起点
一句话:RICE/ICE 的价值不在于算出一个数字,而在于让"我觉得"变成"我们来看看"。
它解决的不是"谁对谁错",而是"我们在哪个维度上有分歧"。
- 你觉得 Impact 高,我觉得低 → 我们来看数据
- 你觉得 Effort 小,我觉得大 → 我们来看历史工期
- 你的 Confidence 是 90%,我的是 40% → 我们来看证据
分歧被定位到具体维度之后,讨论的效率会提升一个数量级。
行动清单(下次排优先级前 5 分钟)
- [ ] 确认用 RICE 还是 ICE(有 Reach 数据 → RICE;没有 → ICE)
- [ ] 对齐打分标准(Impact 的 10 分到底长什么样?Effort 包不包含测试?)
- [ ] 每个人独立打分,不要互相看
- [ ] 打完分再看排序,不允许"看到结果不满意就改分"
- [ ] Confidence < 50% 的需求,先排"验证优先级"而不是"开发优先级"
- [ ] Effort 估完乘以 1.5 作为现实系数
- [ ] 分数是讨论的起点,不是结论——允许"例外处理",但要说清楚为什么
- [ ] 每季度重新打一次分
一句话金句
量化不是为了精确,是为了让分歧从"我觉得"变成"我们来看看哪个维度不一样"。
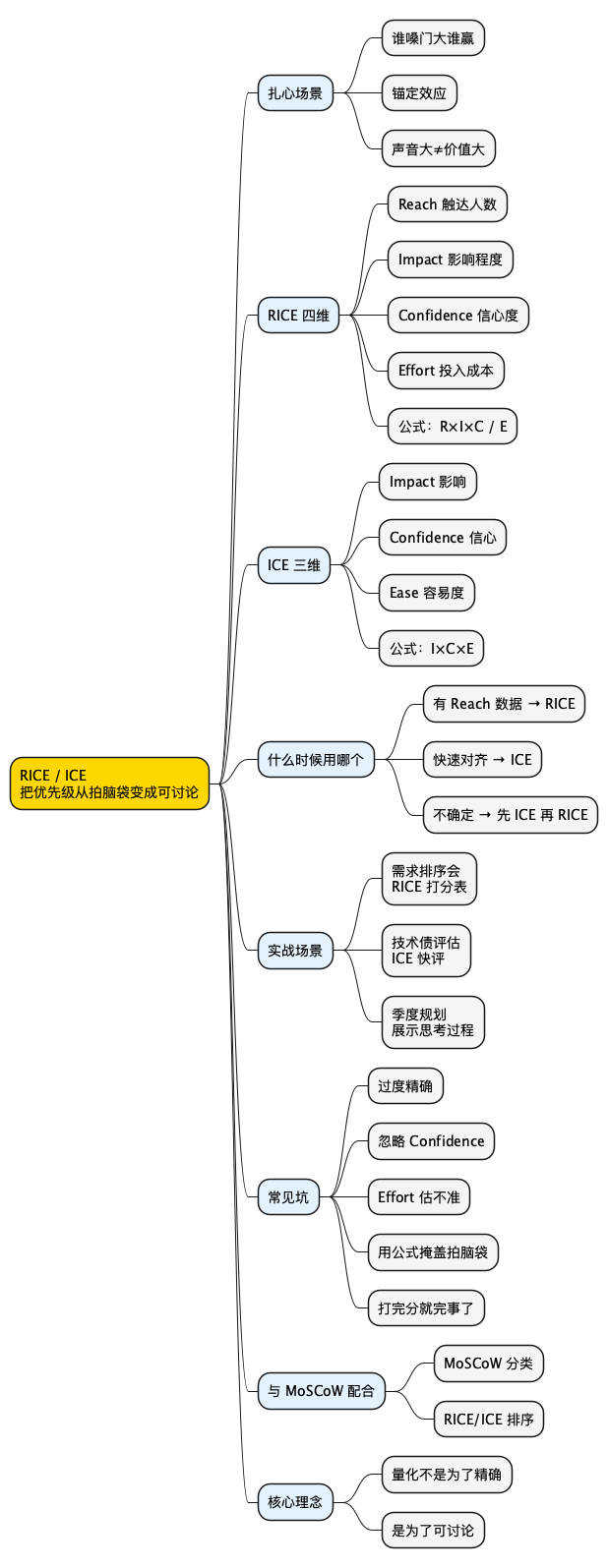
思维导图
@startmindmap
<style>
mindmapDiagram {
node { BackgroundColor #FAFAFA }
:depth(0) { BackgroundColor #FFD700 }
:depth(1) { BackgroundColor #E3F2FD }
:depth(2) { BackgroundColor #F5F5F5 }
}
</style>
* RICE / ICE\n把优先级从拍脑袋变成可讨论
** 扎心场景
*** 谁嗓门大谁赢
*** 锚定效应
*** 声音大≠价值大
** RICE 四维
*** Reach 触达人数
*** Impact 影响程度
*** Confidence 信心度
*** Effort 投入成本
*** 公式:R×I×C / E
** ICE 三维
*** Impact 影响
*** Confidence 信心
*** Ease 容易度
*** 公式:I×C×E
** 什么时候用哪个
*** 有 Reach 数据 → RICE
*** 快速对齐 → ICE
*** 不确定 → 先 ICE 再 RICE
** 实战场景
*** 需求排序会\nRICE 打分表
*** 技术债评估\nICE 快评
*** 季度规划\n展示思考过程
** 常见坑
*** 过度精确
*** 忽略 Confidence
*** Effort 估不准
*** 用公式掩盖拍脑袋
*** 打完分就完事了
** 与 MoSCoW 配合
*** MoSCoW 分类
*** RICE/ICE 排序
** 核心理念
*** 量化不是为了精确
*** 是为了可讨论
@endmindmap
系列回顾
- 4D 总结法
- 黄金圈法则
- TNB 表达模型
- FAB 提案法
- STAR 面试法
- 同理心三方法
- 5W1H + 8C1D
- 艾森豪威尔矩阵
- PDCA 循环
- SMART 原则
- 领导力
- 逻辑树
- 解决问题五步法
- 5 个 Why
- 沟通四要素 CARE
- 金字塔原理
- 三点法
- DACI
- 四线复盘法
- RAPID
- 5S 问题处理法
- SWOT 自我定位
- AARRR 漏斗
- 第一性原理
- RACI
- 非暴力沟通
- SCAMPER
- MVP 思维
- ABC 情绪理论
- AI Agent 学职场英语
- 向上管理
- OODA 循环
- OKR
- MoSCoW 优先级
- RICE / ICE 评分(本篇)
- 里程碑计划
- 验收标准 DoD
- 范围管理
扩展阅读
- Intercom: RICE: Simple prioritization for product managers(RICE 的原始出处)
- Sean Ellis: ICE Score for Growth Experiments(ICE 的来源)
- Itamar Gilad: Why I Stopped Using ICE Score(ICE 的局限性反思)
- Daniel Kahneman: Thinking, Fast and Slow(锚定效应、乐观偏差等认知偏差的经典著作)
- Frederick Brooks: The Mythical Man-Month(人月神话——为什么 Effort 估不准)
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。