IT 中间件三岔路:买、用开源,还是自研
Posted on 五 26 6月 2026 in Tech
| Abstract | IT 中间件三岔路:买、用开源,还是自研 |
|---|---|
| Authors | Walter Fan |
| Category | Tech |
| Status | v0.2 |
| Updated | 2026-06-27 |
| License | CC-BY-NC-ND 4.0 |
一、又一次被“内部平台”教育
最近又被几个内部自研平台教育了一回。
不是说这些东西不能用。恰恰相反,它们往往还能用,而且确实解决了公司某个很特殊、很拧巴、外面产品不太好覆盖的问题。问题在于:太难学,太难问,也太难接手。
开源产品再复杂,好歹还有文档、issue、Stack Overflow、博客、视频教程,甚至还有一堆踩坑帖。你不会用 Vault、Keycloak、Argo CD、Harbor,搜索一下,总能搜到几个同病相怜的人。内部自研平台就不一样了。文档像考古线索,错误提示像谜语,最佳实践散落在群聊、旧 wiki、某位老同事的脑子里。你看代码,大概知道它是怎么做的;可是你不知道为什么要这样做。
这就让人很郁闷。
更折磨的是,你还得找人问。对外向型同学来说,拉个会、发个消息、追着人问,也许不是大事。对我这种 I 人来说,就有点像让后端工程师穿着西装去路演,能做,但每一分钟都在消耗生命值。你还得看别人有没有时间、心情好不好、记不记得当年的设计背景。问得多了,自己不好意思;不问吧,系统又在那里冷冷地看着你。
所以我对“自研平台”这四个字,一直有点复杂感情。程序员听到“自研”,难免手痒。自己做身份管理、自己做密钥管理、自己做工件仓库、自己做部署系统,听起来多有控制感。就像年轻时买了一堆木板和电钻,觉得周末可以亲手打一套柜子。等到周日晚上,客厅里只剩下歪歪扭扭的木板、半盒螺丝和一位怀疑人生的中年男子。
我也见过不少企业里的自研中间件,最后做成了“四不像”:像产品,却没有产品经理;像平台,却没有平台团队;像基础设施,却没有 SLO 和 on-call;像工程项目,却没有像样的文档、示例和迁移路线。用起来难用,改起来费劲,停又不敢停,继续投又心疼。
这类系统最尴尬的地方在于:它不是完全没用。完全没用倒好办,关掉就是。它往往有三五个关键业务在用,有几位老员工懂,有几段祖传脚本能跑。食之无味,弃之可惜。鸡肋系统,大抵如此。
所以这篇想聊一个很实际的问题:企业里的中间件,到底该买商业软件、采用开源,还是自研?如果真要自研,需要满足哪些条件?怎么做才不至于把热情做成债务?
先把结论放前面:自研不是原罪,但自研必须被当成一项长期产品投资,而不是一个“顺手写一下”的工程任务。
二、中间件不是业务系统,它是企业的“水电煤”
身份管理、密钥管理、工件仓库、CI/CD、部署系统、配置中心、日志平台、监控告警,这些东西有个共同特点:平时没人夸,出事人人骂。
身份系统挂了,用户登录不了;密钥系统挂了,服务拿不到凭证;工件仓库慢了,构建排队;部署系统抽风,发布窗口就变成大型心理素质测试。它们不像一个漂亮的业务页面,用户看得见,也不像一个新算法,能在大会上讲得眉飞色舞。它们更像办公室里的电、水、网络。你不太会因为灯亮着而感谢电工,可灯一灭,电工电话就被打爆。
这也是为什么中间件选型不能只看“我们能不能写出来”。能写出来,是最低门槛。真正的问题是:写出来之后,别人能不能学会,能不能用对,能不能在原作者不在场的时候继续往前走。
- 能不能稳定运行三五年?
- 能不能支撑组织规模变大?
- 能不能让新团队低成本接入?
- 能不能让一个新同事靠文档和示例独立跑通,而不是靠“认识谁”?
- 能不能在安全审计、合规检查、事故复盘时拿得出证据?
- 能不能有人持续修 bug、补文档、做迁移、处理边界场景?
很多自研项目栽就栽在这里。第一版写出来不难,尤其是现在有开源库、有云服务、有 AI 帮忙生成代码。难的是第二年、第三年、第十年。中间件的成本,不在“写出来”,在“活下去”。
三、三条路各有账本:商业、开源、自研
企业做中间件,大体有三条路。没有哪条路天然高贵,关键看你要解决什么问题,愿意付哪种代价。
1. 购买商业软件:花钱买成熟度,也买约束
商业软件最大的好处,是成熟。身份管理可以买成熟的 IAM / SSO 产品,密钥管理可以买云厂商 KMS 或专业密钥平台,工件仓库可以买 Artifactory 这类产品,部署系统也有成熟的 SaaS 或企业版工具。
花钱买的不是那几行代码,而是产品化能力:文档、权限模型、审计日志、支持渠道、升级路径、安全公告、兼容性测试。更现实一点说,你买的是“让普通工程师少受点罪”。一个新人照着 quick start 能跑通,遇到错误能查文档,遇到边界能找 support,这些都是真成本。只是它们平时不在报价单上,事故发生时才从墙里钻出来。
尤其是身份和密钥这类系统,很多坑商业产品已经替你踩过了。咱们自己写一遍,等于拿生产环境当练功房,这事听起来就有点刺激。
当然,商业软件也有代价。许可证费用可能不低,定制能力受限,供应商路线会影响你,遇到深度集成时也可能被绑住手脚。买商业软件像请装修公司,省心,但你不能一边要求套餐价,一边要求每块瓷砖都按你梦里的纹路贴。
适合购买的场景很清楚:行业标准成熟,企业需求没有太多特殊性,安全和合规要求高,内部没有长期平台团队,或者这个能力不是你的核心竞争力。
2. 采用开源软件:别把“免费”误会成“不要钱”
开源软件是很多企业的第二选择。Keycloak、Vault、Harbor、Argo CD、Tekton、Jenkins、Nexus、Prometheus、Grafana,这些工具在各自领域都很能打。
开源的优点是透明、可控、生态丰富,遇到问题可以读源码,也可以根据标准接口做集成。更重要的是,它有“公共知识”。你踩的坑,大概率别人踩过;你遇到的报错,大概率有人在 issue 里骂过;你想不通的设计,大概率能在文档、proposal 或 mailing list 里找到来龙去脉。
这点对使用体验太重要了。学习一个复杂系统,本来就像爬山。开源项目至少有路标、有游记、有前人留下的“此处有坑”。内部自研平台很多时候像夜爬,手电筒还快没电了。
不过开源不是免费午餐。你省下的是 license,买回来的是运维责任。版本升级谁做?安全漏洞谁跟?插件冲突谁查?数据备份谁管?社区路线变了怎么办?一个开源系统放进企业里,就像领养了一只看起来很乖的猫,猫粮、疫苗、绝育、半夜打翻杯子,都是你的。
适合采用开源的场景是:需求与社区主线接近,团队有运维和二次开发能力,愿意跟随上游版本,能接受用配置和插件解决大部分差异,而不是一上来就 fork 一份源码改到亲妈都不认识。
3. 自研软件:最自由,也最容易欠债
自研最大的诱惑,是“完全符合我们的需求”。每个按钮、每个流程、每个权限点都可以按内部习惯来。听上去很美。
可是软件工程里有个朴素规律:越自由,越需要纪律。 商业软件用价格约束你,开源软件用社区主线约束你,自研软件如果没有清晰边界,就会被每个业务方的“顺便加一下”撕成碎片。
身份管理自研到一半,发现还要支持 OIDC、SAML、SCIM、MFA、审计、生命周期管理;密钥管理自研到一半,发现还要支持轮转、租户隔离、审批流、HSM、灾备、泄露响应;部署系统自研到一半,发现还要支持灰度、回滚、权限、审计、环境差异、变更冻结。每个词拆开都是一条长路。
还有一条路更隐蔽:知识债。为什么这里要多一次审批?为什么这个字段不能改?为什么 staging 和 prod 的流程不一样?为什么这个错误码看起来像乱码?如果答案只存在某几个人脑子里,那系统表面上是平台,实际上是“人肉 API”。调用方式很简单:找对人,等回复。
所以自研最怕的不是技术难,而是低估了“产品全生命周期”。一个能跑的 demo,只是婴儿学会翻身,不是可以去跑马拉松。
四、AI 时代,判断要变,但底线没变
讲到这里,可能有人会说:老兄,你这个判断是不是有点保守?AI 时代不一样了。以前做一个平台要十个人干半年,现在两三个人加上 AI coding agent,几周就能做出像模像样的版本。那我们是不是应该更大胆一点?
这个问题问得好。我的答案是:可以更大胆地做 PoC,更谨慎地进生产;可以更多自研“胶水层”,更少自研“命根子”。
AI 确实改变了成本结构。写 CRUD、接 API、做页面、补测试、生成 SDK、整理文档、写迁移脚本,这些事情的成本都降了。以前一个内部工具因为人手不够做不起来,现在可能一个工程师带着 AI 就能搭出第一版。这个变化很大,不能装作没看见。
可是 AI 降低的是“制造第一版”的成本,不是“承担平台责任”的成本。
AI 也能帮你补 README,可是它补不出当年那次事故为什么改变了权限模型;它能解释一段代码在做什么,却未必知道这个奇怪分支背后是哪位客户、哪次审计、哪场半夜发布留下来的疤。平台里最要命的,常常不是代码本身,而是代码背后的上下文。
身份管理出错,AI 不会替你面对全公司登录失败;密钥管理泄露,AI 不会替你向安全团队解释;部署系统误发,AI 不会替你把生产环境回滚;工件系统被污染,AI 不会替你重建供应链信任。出了事故,最后按按钮的人还是你,背责任的还是组织。
所以 AI 时代的考量,应该有几处变化。
1. PoC 门槛降低了,生产门槛不能降
以前评估商业软件或开源软件,做 PoC 很贵,很多团队干脆跳过,凭感觉拍板。现在不该这样了。AI 可以帮你快速搭测试环境、写接入代码、生成压测脚本、整理对比表。买不买、用不用开源、自不自研,都应该先用真实场景跑一遍。
AI 让“认真评估”变便宜了。那就更没有理由懒。
不过 PoC 跑通,不等于生产可用。PoC 里最容易被忽略的,恰恰是平台最要命的部分:权限边界、审计日志、升级路径、灾备恢复、异常处理、支持机制、容量规划、SLO。AI 很擅长把 happy path 写得顺滑,也很擅长把你没问到的坑留在地板下面。
2. 更适合自研薄层,不适合一激动重造底座
AI 最适合帮我们做什么?我觉得是内部差异化的薄层。
比如你用 Vault 或云 KMS 做密钥底座,再自研审批流、租户模型、审计报表、SDK 包装和开发者门户。你用 Kubernetes、Argo CD 做部署底座,再自研企业内部的发布规则、冻结窗口、变更审批、风险提示和统一入口。你用 Okta、Entra ID、Keycloak 做身份底座,再自研员工生命周期、内部权限申请、应用接入向导和可视化审计。
这些地方 AI 很有用,因为它们是“拼接、适配、体验优化、自动化”。它们贴近企业内部流程,外部产品很难完全满足,自己做也不会一口吞下全部底层复杂度。
反过来,自己从零写密码学、密钥存储、身份协议、制品签名、容器调度、分布式部署引擎,这就要谨慎。AI 可以生成代码,但它不会天然生成安全模型、威胁建模和十年运维经验。让 AI 给你写一个“看起来像 Vault 的东西”,这事技术上可能不难,工程上却很吓人。
3. AI 让“半拉子工程”更容易出现
过去半拉子工程还有个天然限制:人少,写不快。现在不一样,AI 会让半拉子工程长得很快。页面有了,接口有了,README 有了,甚至测试覆盖率也能刷到一个好看的数字。看上去像产品,其实没有产品纪律;看上去像平台,其实没有运营责任。
这就像给一间毛坯房贴上精装修壁纸。远看不错,近看插座没接地,水管没试压,消防通道还被柜子挡着。
AI 时代更要问几个冷问题:
- 这套系统的威胁模型是谁写的?
- 哪些路径必须人工审批,哪些可以自动化?
- 出事故时怎么降级、回滚、冻结、吊销?
- 每个关键操作有没有审计证据?
- 备份是否真的恢复过?
- 代码和配置是否能被新同事接手?
- 那些“为什么”的解释,是否写在文档和 ADR 里,而不是只在某几个人脑子里?
- AI 生成代码的安全扫描、依赖扫描、review 闸门在哪里?
如果这些问题答不上来,AI 写得越快,技术债来得越密。
4. 自研决策里要多一项:AI 能不能把长期维护也变便宜
AI 不是只能写代码,它还能帮助写文档、生成 SDK、解释日志、生成迁移脚本、做变更影响分析、整理事故复盘。这些能力确实会降低长期维护成本。
所以新的自研判断,不该只问“AI 能不能帮我们写出来”,还要问“AI 能不能帮我们持续养得起”。如果你能把 ADR、接口契约、测试用例、Runbook、监控告警、变更流程都放进一套工程 harness 里,让 AI 每次改动都读得到、跑得动、验得过,那自研的胜率会变高。
如果没有这些,AI 只是把你推上高速公路,刹车系统还没装。
一句话:AI 让自研的入场券便宜了,但没有替你买保险。
五、什么时候才值得自研:六道门槛
我倾向于把自研当成最后一张牌,而不是第一反应。真要打这张牌,至少过六道门槛。
1. 这是战略能力,不是工程师的兴趣项目
第一个问题是:这个中间件能力,对公司有没有战略意义?
如果它只是“我们也需要一个”,那大概率不该自研。身份、密钥、工件、部署这些领域,外面已有成熟方案。你要自研,必须说清楚外部方案为什么不能满足你:是监管要求,是数据主权,是超大规模,是极端集成,是成本曲线压不住,还是它直接影响你的核心交付能力。
“我们想更灵活一点”不是理由。灵活这词太危险,像一块万能创可贴,哪里没想清楚就贴哪里。
2. 买和开源都认真评估过,而不是被一句“太贵”打发了
我见过一些决策会,商业软件报价一出来,大家倒吸一口凉气,然后拍板自研。这个动作很像看见健身房年卡贵,于是决定自己造一台跑步机。
正确姿势不是只看报价,而是算总账:许可证费用、运维人力、升级成本、事故风险、合规成本、迁移成本、机会成本。自研团队三五个人,一年成本并不低,还不算后续接入、支持和事故处理。
开源也要认真 PoC。拿真实用例跑一遍,别只看 README。能不能接入现有身份体系?权限模型够不够?高可用怎么做?升级能不能平滑?遇到漏洞多久能修?这些答案,比“GitHub star 很多”有用。
3. 有长期 owner,而不是“先做出来再说”
中间件没有 owner,就像无人值守的锅炉房。平时看着没事,一旦出事,大家才发现钥匙在三年前离职的同事抽屉里。
自研前必须明确:谁是产品 owner,谁是技术 owner,谁值班,谁写文档,谁做支持,谁决定需求优先级,谁有权拒绝不合理定制。最好还有预算和编制,而不是靠几位热心工程师下班后“顺手维护”。
靠热情维护平台,前半年很感人,后两年很感冒。
这里的 owner 不是名义上的联系人,而是要为“别人能学会”负责的人。内部平台最怕的是 owner 只会说“有问题找我”。这话听着热情,实际上是在把知识继续锁在人身上。真正负责的 owner,要把常见问题、设计取舍、迁移步骤、失败案例都沉淀下来,让后来的人少走几趟弯路。
4. 有规模收益,能摊薄成本
自研平台要有规模收益。服务数量、团队数量、构建次数、部署频率、密钥数量、审计要求,这些数字要撑得住决策。
如果公司只有十几个服务,部署频率也不高,搞一个自研部署平台,很可能不如把现有工具用好。反过来,如果有几千个服务、上百个团队、严格的变更窗口和审计要求,买不到合适方案,自研控制面就可能有价值。
一句话:规模不够,自研就是手工艺品;规模到了,自研才可能变成基础设施。
5. 能接受“只做差异化部分”,不试图重造宇宙
自研不等于全栈重写。很多时候,最好的自研是“薄薄一层”:底层用成熟开源或商业能力,上面做统一入口、权限、流程、审计、体验和内部集成。
比如密钥管理,不一定要自己写加密存储和密钥派生,可以用云 KMS、Vault 或 HSM 做底座,自研审批、租户模型、审计报表和 SDK 接入。部署系统也不一定要替代 Kubernetes、Argo CD 或 Spinnaker,可以自研控制面,把企业内部的审批、冻结、灰度策略和审计串起来。
这就像装修房子,水泥钢筋没必要自己烧,真正要做的是户型、动线和日常使用体验。
6. 有退出路线,敢给自己留后门
好平台要有退出路线。数据怎么导出?API 有没有标准协议?客户端 SDK 能不能替换?接入方如何迁移?如果将来商业产品降价、开源方案成熟,或者团队不再投入,能不能体面地下车?
很多自研系统最后变成“祖传平台”,不是因为它优秀,而是因为没人知道怎么离开。没有退出路线的自研,本质上是在给未来的自己挖坑。坑挖得很深,姿势还很专业。
六、真要自研,按产品来做,不要按项目来糊
如果六道门槛都过了,自研也不是不能做。关键是别把它当成一次交付项目,而要当成一个内部产品。
1. 先写决策记录,把“为什么不买、不用开源”说清楚
开工前写一份 ADR(Architecture Decision Record),把问题、约束、备选方案、PoC 结果、成本估算、风险和退出路线写明白。
这份文档的价值,不是给领导看的漂亮材料,而是给半年后的自己看的。等需求开始膨胀、团队开始换人、某位同事说“当初为什么不直接买”时,至少还有一份记录能把大家拉回现实。
2. API 和协议优先,界面其次
中间件的核心不是页面,而是契约。身份管理要尊重 OIDC、SAML、SCIM 这类标准;密钥管理要有清晰的访问控制、审计和轮转协议;工件系统要尽量贴近 OCI、Maven、npm、PyPI 这些生态;部署系统要尊重 Kubernetes、GitOps、OpenTelemetry、审计日志这些事实标准。
界面可以丑一点,契约不能乱。页面改版最多被吐槽,协议乱了会拖死一堆接入方。
3. 文档、SDK、示例和迁移指南,一起算进交付物
很多内部平台只交付服务端,却不交付使用体验。文档散在聊天记录里,SDK 只有一位同事会用,示例代码过期,迁移指南靠口口相传。这样的系统再先进,也会被业务团队骂。
一个像样的中间件交付物,至少包括:快速开始、概念说明、API 文档、SDK 示例、错误码、常见问题、迁移指南、权限模型、运维手册、事故处理流程。别嫌啰嗦,水电煤的说明书就该写清楚。
我现在越来越看重 quick start。别一上来给我十几个概念、几十个配置项、三套历史方案。先让我用最小权限、最小样例、最短路径跑通一次。跑通之后,再慢慢解释架构、边界和高级能力。学习曲线不是越陡越显得专业,很多时候只是作者没站在使用者那边想过问题。
还有一类文档尤其要补:设计背景。代码告诉你“这里做了什么”,ADR 和 runbook 要告诉你“当年为什么这么做”。没有这个,后来的人只能对着代码猜心思,猜错了还要背锅。咱们写代码已经够累了,没必要再搞软件考古。
4. 安全和审计从第一天进设计,不要等上线后补
身份和密钥系统尤其如此。权限模型、最小权限、审批记录、审计日志、敏感信息脱敏、密钥轮转、应急吊销、备份恢复,这些不是上线前加几张表就能补上的。
部署和工件系统也一样。谁能发布?发布了什么?工件从哪里来?是否有签名?是否能追到源码和构建流水线?出了事故能不能还原当时的变更?这些问题如果第一版没想,后面补起来像给飞行中的飞机换发动机。
5. 建立 SLO 和支持机制,别让用户靠吼解决问题
内部平台也要有服务承诺。可用性目标是什么?响应时间目标是什么?故障多久响应?升级多久通知?重大变更怎么公告?用户从哪里提问题?谁来判断优先级?
没有支持机制的平台,会逼用户发私信、拉群、找熟人。时间久了,平台团队被打扰得疲惫,用户也觉得不专业。最后大家都很委屈:平台方觉得“我已经很努力了”,业务方觉得“我只是想发个版”。
对 I 人用户来说,这种模式尤其不友好。一个系统如果把“会不会用”建立在“敢不敢问人”上,就已经输了半局。好的内部平台应该让用户优先通过文档、示例、错误提示、自助诊断解决 80% 的问题;剩下 20% 再走工单和支持渠道。不要把每个用户都逼成社交达人。
6. 拒绝无限定制,把“铺好的路”修宽
平台的价值不是满足每个团队的特殊癖好,而是提供一条 paved road,一条铺好的路。大多数团队走这条路可以更快、更安全、更省心。少数特殊场景可以有 escape hatch,但要登记、审计、有到期时间。
每接受一次无原则定制,平台就多一个隐形分支。分支多了,平台会从“基础设施”退化成“定制外包队”。这时再谈复用,多少有点自欺欺人。
七、几个常见陷阱,见到就该警觉
陷阱一:把 demo 当产品
demo 可以证明“能做”,不能证明“值得做”。一个 demo 里没有高可用、没有审计、没有权限边界、没有升级和回滚、没有灾备,也没有真实用户的脾气。用 demo 去承诺平台能力,就像拿一张儿童画去申请施工许可。
陷阱二:为了省钱而自研,最后更贵
省钱是结果,不该是唯一动机。自研如果只为躲 license,最后常常变成另一种昂贵:人力贵、事故贵、迁移贵、机会成本贵。尤其是安全和身份领域,便宜的错,可能很贵。
陷阱三:fork 开源后越走越远
开源软件可以改,但 fork 是大事。小补丁最好 upstream,大改动最好做插件或扩展。长期私有 fork 会让升级变成噩梦。上游每发一个安全修复,你都要先在心里默念一遍:我改过哪儿来着?
陷阱四:平台没有产品思维
内部平台不是“给自己人用,所以将就一下”。越是给自己人用,越要珍惜同事时间。一个不好用的平台,会把复杂性摊派给几百个工程师。平台团队省下的一小时,可能让全公司多花一百小时。
陷阱五:把人当文档
有些内部平台,真正的文档不是 wiki,而是某几位老同事。权限怎么配,失败怎么查,哪些参数不能动,为什么要绕这么一圈,全在他们脑子里。新人接入时,先问 A,A 让问 B,B 说当年是 C 定的,C 正在开会。绕一圈下来,需求没做完,人先老了三岁。
这不是协作,这是知识没有落盘。平台越关键,越不能靠“活文档”续命。人会转岗,会休假,会离职,也会忘。代码能留下来,原因也要留下来。
陷阱六:没有度量,全靠感觉争论
平台好不好,别只靠会议室里嗓门大小。看接入时长、构建耗时、部署成功率、回滚时间、事故数量、支持工单、满意度、漏洞修复时间、审计通过率。没有度量,平台改进就像夜里摸黑搬家具,听见“哐当”才知道撞墙了。
八、几个公开案例:成也平台,败也平台
原则说多了,容易像架构师端着茶杯聊天。咱们看几个公开案例,都是能查到资料的,不靠“我有个朋友”。
成功案例一:Netflix Spinnaker,自研后开源,但它不是周末项目
Netflix 的 Spinnaker 是自研平台成功的经典案例。它解决的是 Netflix 自己的核心问题:如何在云上快速、稳定、可重复地发布大量服务。Netflix Tech Blog 介绍过,Spinnaker 在 Netflix 用于部署超过 95% 的 AWS 基础设施,支撑数百个微服务和每天数千次部署;它还沉淀了红黑发布、自动金丝雀分析和内部工具集成等能力。资料可见 Netflix Tech Blog 和 CD Foundation case study。
这个案例的关键,不是“Netflix 自研了,所以我们也自研”。恰恰相反,它说明自研要满足前面那几道门槛:规模足够大,问题足够核心,有长期 owner,有清晰产品边界,还愿意把平台做成可扩展的系统。Spinnaker 后来能开源,是因为它不是一次内部定制外包,而是一套经过生产验证的交付模型。
我从这个案例里得到的提醒是:自研可以,但要从真实规模和真实痛点里长出来。 为了“我们也想有个部署平台”而开工,和 Netflix 的故事不是一回事。
成功案例二:Spotify Backstage,把内部混乱收敛成开发者门户
Spotify 的 Backstage 也很有代表性。它最早是 Spotify 内部的软件目录,用来解决服务、文档、owner、工具入口分散的问题,后来扩展成内部开发者门户,再开源并捐给 CNCF。Spotify 在工程博客里提到,Backstage 频繁用户相比其他开发者,在 GitHub 上活跃度更高,代码变更更多,cycle time 更短,部署也更频繁。资料可见 Spotify Engineering 和 CNCF 的介绍。
Backstage 的高明之处在于,它没有试图替代所有工具,而是做一层统一入口和插件框架。CI/CD、Kubernetes、文档、安全扫描、服务目录,都可以挂进去。它更像一个“开发者工作台”,不是一个吞掉全公司的巨无霸。
这也是我喜欢 Backstage 这个思路的地方:自研平台最好的形态,常常不是重造底层,而是把碎片化体验收敛起来。 底层能力可以是开源、商业或云服务,内部平台负责把路铺平。
成功案例三:Kubernetes,从 Borg 经验里抽象出标准
Kubernetes 也可以算一个“自研经验外化”的成功案例。Google 内部早有 Borg 和 Omega 这类集群管理系统,Kubernetes 不是简单把 Borg 代码扔出来,而是把多年容器编排经验抽象成一个更适合社区协作的开源系统。Google Cloud 的 Kubernetes 起源故事里说得很清楚:团队想把 Google 在容器管理上的经验带到外部世界,并通过开源获得快速反馈。资料可见 Google Cloud Blog 和 Kubernetes 十周年文章。
这事对企业自研也有启发。真正值钱的,未必是某个内部系统的代码,而是你从业务规模、运维事故和工程实践里总结出来的模型。能不能把模型抽象得足够干净,能不能把接口做得足够标准,决定了它是平台,还是一堆内部脚手架。
失败案例一:Knight Capital,部署缺口烧掉四亿多美元
Knight Capital 的 2012 年事故,是部署和变更控制领域的反面教材。SEC 的公告写得很直接:Knight 在自动股票路由系统里保留了旧功能代码,又在新业务上线时错误部署新代码,导致某些订单触发了失效逻辑;45 分钟内发送了超过 400 万个错误订单,交易了超过 3.97 亿股,最终损失超过 4.6 亿美元,还被 SEC 罚款 1200 万美元。资料见 SEC press release。
这个事故常被讲成“程序 bug”,但它更像平台工程失败:部署不一致,遗留代码未清理,告警没有被当成告警,风险控制挡不住异常订单,回滚也没有把配置和代码一起处理。一个服务器没更新,竟然能把公司拖到生死线上。
这件事给部署平台提了个醒:核心不是按钮好不好看,而是能不能保证一致性、可验证、可回滚、可熔断。 没有这些,部署系统越自动,事故跑得越快。
失败案例二:Code Spaces,控制面和备份一起丢,企业直接关门
Code Spaces 是另一个令人后背发凉的案例。2014 年,攻击者拿到其 AWS EC2 控制面访问权限,在勒索失败后删除了 EBS snapshots、S3 buckets、AMIs 和多台机器。Code Spaces 当时公告说,大部分数据、备份、机器配置和异地备份都被部分或完全删除,公司无法继续经营,只能停止服务。资料见 Public Cloud Security Breaches 和 The Hacker News。
这不是简单的“云没用好”。它说明控制面、身份、权限、备份、灾备不能被放在同一个篮子里。尤其是备份,不能只存在于同一个账号、同一个权限域、同一个控制面下面。攻击者拿到控制面,就等于拿到橡皮擦。
这事提醒我们:密钥管理、云账号、备份和灾备,是企业平台里的命根子。 它们之间必须有隔离,有只读或不可变备份,有演练过的恢复流程。
失败案例三:GitLab 2017 数据库事故,备份不是“有”,而是“能恢复”
GitLab 2017 年的数据库事故也很适合平台团队反复阅读。GitLab 的 postmortem 说,事故起因是生产数据库目录被误删;恢复时发现 pg_dump 备份因为版本不匹配一直失败,S3 bucket 为空,cron 邮件也因为 DMARC 问题没有送达。最后只能使用约 6 小时前的 LVM snapshot 恢复,造成数据丢失。资料见 GitLab postmortem。
这个案例最值钱的地方,是它把“我们有备份”这句话拆穿了。备份脚本存在,不等于备份有效;备份文件存在,不等于能恢复;恢复流程写在文档里,不等于值班工程师在凌晨能跑通。
它给平台团队的一记耳光是:平台可靠性不靠信念,靠演练。 备份必须监控,恢复必须定期演练,脚本必须像正式软件一样测试和管理。
失败案例四:SolarWinds 和 Okta,买商业软件也要管供应链风险
商业软件不是免死金牌。SolarWinds Orion 事件里,攻击者把恶意代码注入软件构建流程,受污染更新被正常签名和分发。Mandiant / Google Cloud 的分析提到,受污染的 SolarWinds Orion 组件通过合法更新传播,影响范围覆盖政府和企业组织。资料见 Mandiant / Google Cloud analysis 和 SolarWinds 调查更新。
Okta 2023 年支持系统事件也说明,身份供应商本身就是高价值目标。Okta 的根因说明里提到,攻击者在 2023 年 9 月到 10 月期间未授权访问客户支持系统中的文件,涉及 134 个客户;部分 HAR 文件含 session tokens,攻击者用这些 token 劫持了 5 个客户的合法 Okta session。资料见 Okta security article。
这两个案例并不是说“别买商业软件”。我的理解正好相反:买商业软件仍然可能是正确选择,但你不能把风险一起外包掉。供应商要做审查,权限要最小化,日志要接入自己的监控,关键系统要有隔离和应急预案。把身份、监控、构建、部署这类软件买回来以后,就当它永远不会出事,这是另一种天真。
案例背后的共同教训
把这些案例放在一起看,有几条线很清楚:
- 成功的平台,往往有真实规模、清晰 owner、标准接口、长期运营和社区/生态意识。
- 失败的平台,常常败在部署不一致、权限过大、备份未验证、告警无人处理、文档和脚本不靠谱。
- 自研、开源、商业都会出事,区别只在于你把哪部分风险留给自己。
- 平台不是“上线就完”,平台是在事故、迁移、升级、审计和用户抱怨里慢慢长结实的。
所以我不反对自研。我反对的是:只看见 Netflix 的光鲜,没看见它背后的规模和纪律;只羡慕 Spotify 的门户,没看见它先解决了内部混乱;只相信商业产品的品牌,没准备好供应链和身份侧的兜底方案。
九、一张可抄的决策清单
下次再遇到“这个平台我们要不要自研”,不妨把下面这张表拿出来。不要急着表态,先把问题问完。
| 问题 | 偏向商业软件 | 偏向开源 | 偏向自研 |
|---|---|---|---|
| 需求是否行业通用 | 高度通用 | 基本通用,可配置 | 高度特殊,外部方案难覆盖 |
| 安全合规压力 | 需要成熟认证和支持 | 团队能承担安全运营 | 有特殊合规或数据主权要求 |
| 内部团队能力 | 缺少平台团队 | 有运维和二次开发能力 | 有长期产品、研发、运维 owner |
| 规模收益 | 规模不足,买更划算 | 中等规模,开源可摊薄 | 大规模使用,自研能显著降本或提效 |
| 定制需求 | 少量配置即可 | 插件和扩展可解决 | 差异化部分是核心竞争力 |
| 学习曲线 | 文档、培训、支持成熟 | 社区资料多,问题可搜索 | 自己要补 quick start、示例、ADR、FAQ |
| 退出路线 | 供应商支持迁移 | 社区生态和标准协议可迁移 | 自己设计标准 API 和导出机制 |
| 生命周期投入 | 希望少维护 | 愿意跟上游 | 愿意投入三五年甚至更久 |
我的个人倾向可以浓缩成三句话:
- 能买就买,尤其是身份、密钥、安全审计这类高风险领域。
- 能用开源主线就别 fork,能做插件就别改核心。
- 真要自研,就只自研差异化的那一层,并把它当产品养,文档、示例、支持、退出路线都算产品的一部分。
还有一句更朴素的判断:如果一个内部平台不能让普通工程师少花时间,反而让大家到处问人、到处猜、到处试,那它就算功能再“贴合内部需求”,也不能算真正成功。
十、附:一个简化决策图
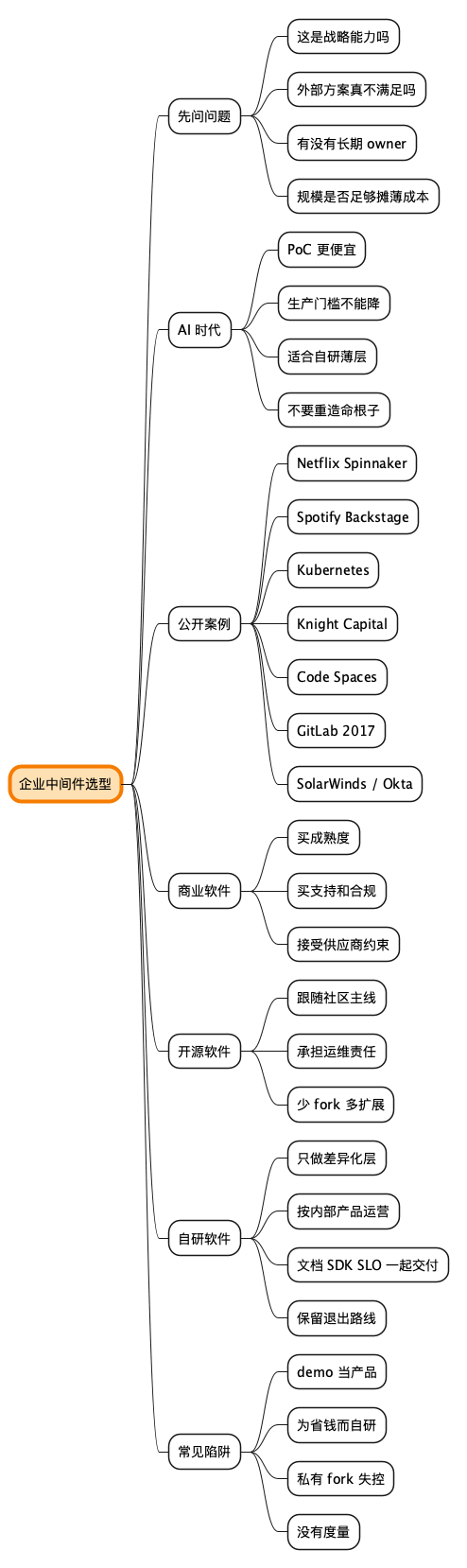
@startmindmap
<style>
node {
BackgroundColor White
}
rootNode {
BackgroundColor #ffe0b2
LineColor #f57c00
LineThickness 4
}
</style>
* 企业中间件选型
** 先问问题
*** 这是战略能力吗
*** 外部方案真不满足吗
*** 有没有长期 owner
*** 规模是否足够摊薄成本
** AI 时代
*** PoC 更便宜
*** 生产门槛不能降
*** 适合自研薄层
*** 不要重造命根子
** 公开案例
*** Netflix Spinnaker
*** Spotify Backstage
*** Kubernetes
*** Knight Capital
*** Code Spaces
*** GitLab 2017
*** SolarWinds / Okta
** 商业软件
*** 买成熟度
*** 买支持和合规
*** 接受供应商约束
** 开源软件
*** 跟随社区主线
*** 承担运维责任
*** 少 fork 多扩展
** 自研软件
*** 只做差异化层
*** 按内部产品运营
*** 文档 SDK SLO 一起交付
*** 保留退出路线
** 常见陷阱
*** demo 当产品
*** 为省钱而自研
*** 私有 fork 失控
*** 没有度量
@endmindmap
十一、最后一句不中听但有用的话
自研平台最迷人的地方,是它让我们觉得自己掌握了命运;自研平台最危险的地方,也是它让我们误以为自己掌握了命运。
真正的掌控,不是每一行代码都自己写,而是知道哪些东西该买,哪些东西该借,哪些东西必须自己做,哪些东西做了以后要负责到底。工程师的成熟,有时不是“我能造”,而是“我知道不该造”。这话听着有点怂,其实不怂,是对长期成本有敬畏。
如果非要自研,我希望它至少像一个开源项目那样对后来者友好:有 quick start,有清楚的概念,有能跑的示例,有设计取舍,有错误排查,有升级路径。不要让下一个接手的人,只能在代码里翻遗迹,在群聊里找传说,在会议室里等某位“活文档”有空。
古人说“图难于其易,为大于其细”。做中间件尤其如此。大系统不是靠一腔热血撑起来的,是靠边界、纪律、文档、运营和长期责任一点点垒出来的。
一句话:自研可以,但别凭冲动开工;一旦开工,就别只当项目做,要当产品养。 无他,少给未来的自己添堵,也少折磨后来那些和我一样不太爱到处问人的工程师。