职场工具箱之 MOP/SOP:AI 时代更需要"清单革命"
Posted on 五 13 3月 2026 in Method
| Abstract | 职场工具箱之 MOP/SOP:AI 时代更需要"清单革命" |
|---|---|
| Authors | Walter Fan |
| Category | Method |
| Version | v1.0 |
| Updated | 2026-03-13 |
| License | CC-BY-NC-ND 4.0 |
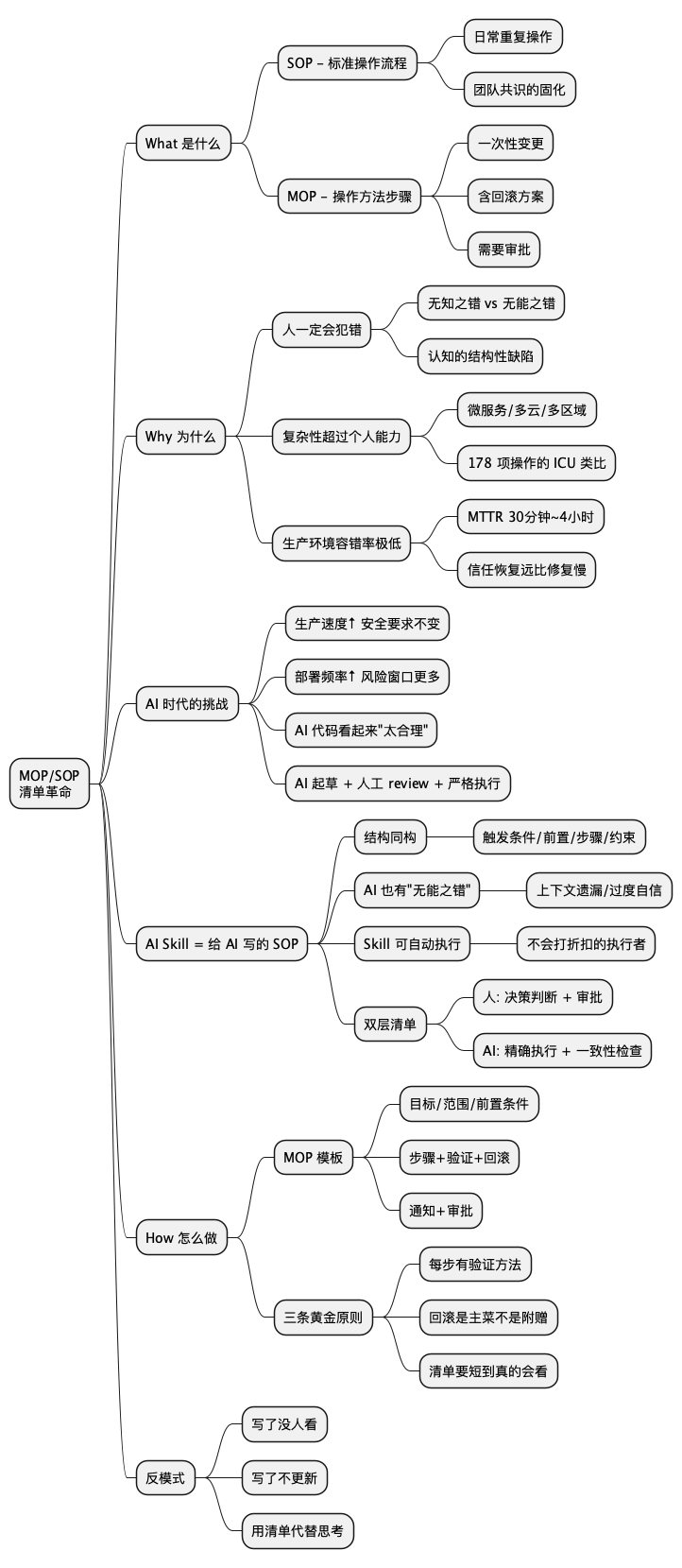
简短大纲
展开看看
- **扎心场景**:凌晨两点,一条命令把生产数据库删了 - **What**:MOP(Method of Procedure)和 SOP(Standard Operating Procedure)分别是什么?有什么区别? - **Why**:为什么需要清单——从《清单革命》的核心洞察说起,复杂性超过了人脑的工作记忆 - **AI 时代的新挑战**:代码生成更快、部署更频、变更更密集,但出错的代价一点没降 - **AI Skill = 给 AI 写的 SOP**:AI Agent 的 Skill 机制与人类 MOP/SOP 的深层同构 - **How**:MOP/SOP 怎么写?一个部署 MOP 模板 + 三条黄金原则 - **常见反模式**:写了没人看、写了不更新、清单太长反而成负担 - **总结 + 行动清单 + 思维导图 + 扩展阅读**1. 扎心场景:凌晨两点,一条命令的代价
这不是编的。
某天凌晨两点,我收到一条告警——线上某个关键服务全部 502。爬起来一看,是一位同事在执行数据库迁移时,手滑把 DROP TABLE 跑到了生产环境。他的终端里开了两个 tab,一个连测试库,一个连生产库。在困意和肾上腺素的双重加持下,他选错了 tab。
修复用了四个小时。事后复盘时大家围坐一圈,每个人都在想同一件事:这个错误本不该发生。
不是因为他技术差。他是组里最好的 DBA 之一。是因为那天没有人执行 MOP,没有人 double-check 目标环境,没有人要求他在操作前念一遍"我现在连的是哪个库"。
人一定会犯错,这不是态度问题,这是生理限制。
Atul Gawande 在《清单革命》(The Checklist Manifesto)里讲了一个让我印象深刻的数字:在 ICU 里,一个病人平均每天需要 178 项护理操作,即使护士的正确率高达 99%,每天仍有近 2 项操作被遗漏。放到生产运维里也一样——一次上线涉及的检查点可能有 20-50 个,每个环节 99% 的正确率听上去很高,但全流程走下来,出错的概率会让你出一身冷汗。
小白提示:MOP 是 Method of Procedure 的缩写,指"操作方法步骤",通常用于一次性或低频的变更操作。SOP 是 Standard Operating Procedure 的缩写,指"标准操作流程",用于日常重复性的操作。两者都是"清单",但场景不同。
2. What:MOP 和 SOP 到底是什么?
2.1 SOP:日常操作的"标准动作"
SOP 是你每天都在做的事情的"最佳实践冻结版"。它不是教程,不是文档,而是一套经过验证的、step-by-step 的操作流程,任何一个合格的工程师照着做,都能得到一致的结果。
举几个例子:
| 场景 | SOP 内容 |
|---|---|
| 服务日常部署 | 代码合入 → CI 通过 → staging 验证 → 灰度发布 → 全量 → 冒烟测试 → 确认 |
| 日常备份检查 | 登录备份系统 → 检查最近一次备份时间 → 验证备份可恢复性 → 记录结果 |
| 告警响应 | 收到告警 → 确认影响范围 → 判断等级 → 拉群/上报 → 止血 → 复盘 |
SOP 的精髓在于:把"这件事应该怎么做"从个人经验变成团队共识。 新人来了不用跟老员工"师傅带徒弟",照着 SOP 就能上手。老员工走了,知识不会跟着人走。
2.2 MOP:一次性变更的"施工图纸"
MOP 和 SOP 的区别,有点像"装修施工图"和"日常保洁流程"的区别。
SOP 管的是天天做的事,MOP 管的是"这次要做一件以前没做过的事(或者做过但风险很高的事)"。
一个典型的 MOP 包含以下部分:
1. 变更目标(Objective)
- 做什么、为什么做
2. 影响范围(Impact Scope)
- 受影响的服务、数据、用户
3. 前置条件(Prerequisites)
- 需要提前准备什么
4. 操作步骤(Procedure)
- 每一步的具体命令/操作
- 每一步的预期结果
- 每一步的验证方法
5. 回滚方案(Rollback Plan)
- 如果第 N 步出错,怎么退回去
6. 通知计划(Communication Plan)
- 操作前通知谁
- 操作后通知谁
7. 审批签字(Approval)
- 谁审批、谁执行、谁监督
关键区别总结:
| 维度 | SOP | MOP |
|---|---|---|
| 频率 | 高频、重复 | 低频、一次性或偶发 |
| 目的 | 标准化日常操作 | 控制特定变更的风险 |
| 审批 | 通常不需要每次审批 | 通常需要评审和签字 |
| 回滚 | 内建在流程中 | 必须单独写回滚方案 |
| 谁写 | 团队共同维护 | 变更负责人编写 |
2.3 两者的关系
MOP 和 SOP 不是互斥的,而是互补的。
日常部署走 SOP,因为流程成熟、风险可控。但如果这次部署涉及数据库 schema 变更、跨区域迁移、或者第一次上线的新服务,就需要单独写 MOP。
你可以把 SOP 理解为"日常行驶规则",MOP 理解为"施工路段的临时交通管制方案"。平时按规则开,遇到施工区域就得看专门的引导标识。
3. Why:为什么"高手"也需要清单?
3.1 《清单革命》的核心洞察
Atul Gawande 不是程序员,他是外科医生。但他在《清单革命》里总结的两个核心观点,放到运维和部署里一字不用改:
观点一:人类犯错有两种——"无知之错"和"无能之错"。
"无知之错"是你不知道该怎么做,这可以靠学习解决。但更可怕的是"无能之错"——你明明知道该怎么做,但在执行时遗漏了、搞反了、跳过了。你知道要检查目标环境,但你就是忘了。这不是技术问题,是人类认知的结构性缺陷。
观点二:复杂性已经超过了任何个人的能力边界。
一个现代微服务系统的上线,涉及代码、配置、数据库、缓存、负载均衡、DNS、CDN、监控、告警、灰度策略……没有谁能在脑子里同时装下所有这些检查点。
Gawande 的解决方案不是"找更聪明的人",而是"给聪明人一张清单"。
3.2 生产环境的容错率有多低?
聊聊数字吧。
- 一次线上事故的平均修复时间(MTTR)在 30 分钟到 4 小时之间
- 一次 P1 级别事故的直接成本(按收入损失 + 工程师时间)可以轻松达到几十万
- 用户信任的损失?无法量化,但恢复周期远比修复时间长
生产环境不是考试,不是 80 分就算过。它更像走钢丝——你可以走 999 步都很稳,但第 1000 步摔下去,前面 999 步就全白费了。
在这种容错率极低的场景下,依赖"经验"和"小心"是最危险的策略。 因为经验会有盲区,小心会有松懈。清单不会。
3.3 "我经验丰富,不需要清单"
这是我听过最危险的一句话。
航空业早就想明白了这件事。飞行员是经过严格训练的专业人员,但波音公司在 1935 年就引入了飞行前检查清单——正是因为一位经验丰富的试飞员在 Model 299 的首飞中忘记释放升降舵锁,导致飞机坠毁。
从那以后,航空业的安全记录持续提升。不是因为飞行员变聪明了,而是因为有了清单。
同样的道理,在运维和部署里:
- 你连过 500 次生产数据库,不代表第 501 次不会连错
- 你部署过 200 次,不代表第 201 次不会漏掉一个配置项
- 你半夜被叫醒过 100 次,不代表第 101 次你的判断力不会打折
经验越丰富,越容易进入"自动驾驶"模式——手在动,脑子已经在想别的事了。清单的价值恰恰在于:它强制你从"自动模式"切回"手动确认模式"。
4. AI 时代的新挑战:更快、更频、更危险
4.1 AI 加速了"生产",但没降低"风险"
这两年的变化大家都看到了。GitHub Copilot、ChatGPT、Claude、Cursor……AI 让写代码和改代码的速度提升了好几倍。但这里有一个容易被忽视的问题:
代码的生产速度提升了,但部署的安全要求一点都没降低。
你用 AI 一天写完了以前一周的代码量,很好。但这些代码还是要经过 review、测试、灰度、监控、回滚准备——这些环节不会因为代码是 AI 写的就可以省掉。
如果你因为"AI 写的代码质量高"就跳过了某些检查步骤……好吧,让我提醒你一下,AI 写的代码也会有 bug,而且它的 bug 有时候比人写的更隐蔽——因为 AI 生成的代码看上去非常"合理"和"完整",让你放松了警惕。
4.2 变更频率更高,出错窗口更大
传统模式下,一个团队可能两周部署一次。有充足的时间准备 MOP、执行 review、安排操作窗口。
现在呢?CI/CD 管线每天可能触发几十次部署。每一次都是一个潜在的风险窗口。
这不是说我们应该减慢部署速度——持续部署是好事。但它对自动化检查和标准化流程的要求更高了,而不是更低了。
你可以类比高速公路:车速从 60 提到 120,不是说可以不系安全带了,而是说安全带、ABS、气囊、车道保持这些安全措施必须更到位。
4.3 AI 是工具,清单是安全网
有人会问:AI 这么强了,能不能让 AI 来生成 MOP?
可以。AI 确实擅长根据你的描述生成操作步骤。但问题来了:AI 生成的 MOP 谁来 review?
如果你觉得"AI 生成的肯定没问题",那你犯了和"我经验丰富不需要清单"一样的错误——只不过把过度信任从自己转移到了 AI 身上。
正确的姿势是:
- AI 帮你起草 MOP/SOP(节省时间)
- 人工 review 并补充特定环境的上下文(AI 不知道你的线上网络拓扑长什么样)
- 执行时严格按清单操作(不管清单是谁写的)
- 事后把实际执行情况反馈到清单里(持续改进)
AI 是效率工具,清单是安全网。两者不是替代关系,而是叠加关系。
5. AI Skill:给 AI Agent 写的 SOP
5.1 一个有趣的发现
如果你用过 Cursor、Claude Code 或者类似的 AI 编程助手,你可能见过一种叫 "Skill" 的东西。
拿 Cursor 的 AI Skill 举例,一个 Skill 文件(SKILL.md)长这样:
# 部署前检查 Skill
## When to Use
当用户要求执行生产部署时触发。
## Prerequisites
- 用户已确认目标环境
- CI/CD 管线已通过
## Steps
1. 读取部署配置文件,确认版本号
2. 检查目标环境的健康状态
3. 确认回滚版本可用
4. 执行灰度部署
5. 监控错误率 10 分钟
6. 如果错误率 > 1%,自动回滚
7. 全量发布并通知相关方
## Constraints
- 绝不跳过灰度步骤
- 回滚方案必须在执行前确认
你有没有觉得这个结构似曾相识?
对,这就是一份 SOP。 只不过执行者不是人,是 AI Agent。
5.2 同构:人的 SOP 和 AI 的 Skill
把人类的 MOP/SOP 和 AI Agent 的 Skill 放在一起比较,你会发现它们在结构上几乎是同构的:
| 要素 | 人类 SOP/MOP | AI Skill |
|---|---|---|
| 触发条件 | "当需要执行数据库迁移时" | When to Use: 当用户要求执行... |
| 前置条件 | 备份完成、审批通过 | Prerequisites: CI 通过、配置已确认 |
| 操作步骤 | Step 1, 2, 3… 带验证方法 | Steps: 1. 读取配置 2. 检查状态... |
| 约束条件 | 不得跳过灰度、必须有回滚 | Constraints: 绝不跳过灰度步骤 |
| 回滚/异常处理 | 回滚方案表格 | 错误处理逻辑、fallback 策略 |
| 输出/交付物 | 操作记录、监控截图 | 执行结果、日志、确认信息 |
这不是巧合。AI Skill 和人类 SOP 解决的是同一个问题:如何让执行者(不管是人还是 AI)在复杂任务中保持一致性,减少遗漏和错误。
人会疲劳、会走神、会"自动驾驶"跳步骤——所以需要 SOP。AI 会幻觉、会丢上下文、会对模糊指令做出错误假设——所以需要 Skill。
5.3 AI 也有"无能之错"
你可能觉得奇怪:AI 不是应该严格按指令执行吗?它怎么也会犯"无能之错"?
实际上,AI Agent 在执行复杂任务时的失败模式,和人类惊人地相似:
-
上下文遗漏:对话太长,AI 忘了前面说过的约束——就像工程师操作到第 15 步时忘了第 3 步的前提条件。
-
过度自信:AI 对自己生成的内容有一种"看上去很对"的倾向,不会主动质疑自己——就像经验丰富的工程师觉得"这个操作我做过 500 遍了,不用看清单"。
-
模糊指令导致偏差:"帮我部署一下"——部署到哪个环境?用什么策略?灰度比例多少?如果你不说清楚,AI 会按它的"常识"做,而它的常识可能和你的生产环境不一样。
-
步骤跳跃:在没有 Skill 约束的情况下,AI 为了"效率"可能会合并或跳过某些步骤——就像赶工期的工程师跳过冒烟测试"先上了再说"。
Skill 对 AI 做的事,和 SOP 对人做的事一模一样:把隐性的规则变成显性的约束,把"应该做"变成"必须做"。
5.4 从 SOP 到 Skill 的进化
不过 AI Skill 比人类 SOP 有一个质的飞跃:Skill 可以自动执行。
人类 SOP 写得再好,最终还是要靠人去遵守。人可以选择不看、选择跳过、选择"这次特殊情况特殊处理"。SOP 的执行完全依赖人的自律和团队文化。
但 AI Skill 不一样。一旦 Skill 被加载,AI Agent 就会按 Skill 的流程执行。它不会因为"赶时间"而跳步骤,不会因为"这次应该没问题"而省掉检查。
这意味着什么?
你可以把团队最好的 SOP 转化成 AI Skill,让 AI Agent 成为"不会打折扣的执行者"。
举个例子,你团队的部署 SOP 里有一条:"部署前必须确认数据库备份时间在 2 小时以内。" 人可能会忘记检查。但如果这条规则写进 AI Skill,AI 每次部署前都会自动查询备份状态,不满足就拒绝继续——比任何人都可靠。
5.5 双层清单:Human SOP + AI Skill
到这里,一个更完整的图景出现了:
┌──────────────────────────────────────────────┐
│ 生产变更流程 │
│ │
│ ┌──────────────┐ ┌──────────────────┐ │
│ │ 人类层 │ │ AI Agent 层 │ │
│ │ │ │ │ │
│ │ MOP/SOP │◄──►│ AI Skill │ │
│ │ - 决策判断 │ │ - 自动化执行 │ │
│ │ - 异常处理 │ │ - 一致性检查 │ │
│ │ - 审批签字 │ │ - 实时监控 │ │
│ │ - 沟通协调 │ │ - 报告生成 │ │
│ └──────────────┘ └──────────────────┘ │
│ ▲ ▲ │
│ │ 反馈闭环 │ │
│ └─────────────────-─┘ │
└──────────────────────────────────────────────┘
人负责"决定做什么",AI 负责"精确地执行"。人的 SOP 保证决策质量,AI 的 Skill 保证执行质量。
这两层清单互相补充:
- 人的 SOP 告诉你"这个变更该不该做、什么时候做、谁来批准"
- AI 的 Skill 告诉 Agent "怎么做、每一步怎么验证、出错了怎么回滚"
- 执行结果反馈回来,同时更新 SOP 和 Skill
不是说有了 AI Skill 就不需要人的 SOP 了。恰恰相反——AI 越强大,人的 SOP 就越重要,因为你需要更清晰地定义"AI 在什么边界内可以自动执行,什么情况下必须等人确认"。
这就像自动驾驶和交通法规的关系:自动驾驶技术越先进,交通法规对"人机责任边界"的定义就越关键。
6. How:怎么写一个好用的 MOP?
6.1 一个最小化的部署 MOP 模板
下面是一个经过实战检验的 MOP 模板,你可以直接拿去用:
# MOP: [变更标题]
## 1. 基本信息
- **变更编号**: CHG-2026-XXXX
- **日期**: YYYY-MM-DD
- **执行人**: @xxx
- **审批人**: @xxx
- **监控人**: @xxx
## 2. 变更目标
[一句话说清楚这次变更要做什么、为什么做]
## 3. 影响范围
- **受影响服务**: service-a, service-b
- **受影响用户**: 所有用户 / xx 地区用户 / 内部用户
- **预计停机时间**: 0 分钟 / 5 分钟 / ...
## 4. 前置条件
- [ ] 数据库备份已完成(备份 ID: xxx)
- [ ] 新版本已通过 staging 验证
- [ ] 灰度策略已配置
- [ ] 监控大盘已打开
- [ ] 回滚版本已确认(v1.2.3)
## 5. 操作步骤
| 步骤 | 操作 | 预期结果 | 验证方法 | 完成 |
|------|------|----------|----------|------|
| 1 | 通知相关方变更开始 | 收到确认 | 群内回复"收到" | [ ] |
| 2 | 确认当前连接的环境 | 显示 prod-db-01 | `SELECT @@hostname` | [ ] |
| 3 | 执行数据库迁移脚本 | 迁移成功 | 脚本输出 "OK" | [ ] |
| 4 | 部署新版本到 canary | canary 健康 | 健康检查 200 | [ ] |
| 5 | 观察 10 分钟 | 错误率无上升 | 监控大盘截图 | [ ] |
| 6 | 全量发布 | 所有实例健康 | K8s rollout status | [ ] |
| 7 | 冒烟测试 | 核心功能正常 | 自动化冒烟脚本 | [ ] |
| 8 | 通知相关方变更完成 | 收到确认 | 群内回复"收到" | [ ] |
## 6. 回滚方案
| 触发条件 | 回滚操作 | 预计耗时 |
|----------|----------|----------|
| 步骤 3 失败 | 执行回滚脚本 rollback.sql | 5 分钟 |
| 步骤 4-7 异常 | kubectl rollout undo | 2 分钟 |
| 全量后发现问题 | 回滚到 v1.2.3 + 数据修复 | 15 分钟 |
## 7. 通知计划
- **变更前**: 在 #ops-channel 通知,@on-call 确认
- **变更后**: 在 #ops-channel 通知完成,附监控截图
- **异常时**: 拉 #incident 频道,@team-lead + @on-call
6.2 三条黄金原则
写 MOP/SOP 不难,写出"真的有人用"的 MOP/SOP 才难。三条原则:
原则一:每一步都有"验证方法"
"执行数据库迁移"不是一个好步骤。"执行数据库迁移,预期输出 'Migration completed: 3 tables altered',如果输出包含 ERROR 则立即停止"——这才是一个好步骤。
没有验证方法的步骤就是一句空话。你怎么知道这一步成功了?靠感觉吗?
原则二:回滚方案不是"附赠品",是"主菜"
我见过太多 MOP,操作步骤写了三页,回滚方案写了一行:"回滚到上一个版本。" 这不叫回滚方案,这叫安慰自己。
好的回滚方案应该和操作步骤一样详细:在什么条件下触发回滚、回滚的具体命令是什么、回滚后怎么验证、回滚预计需要多长时间。
原则三:清单要短到"真的会看"
这是《清单革命》里的关键教训:清单太长了没人看。Gawande 建议一个检查清单不要超过 5-9 个关键检查点。如果你的 MOP 有 50 个步骤,试着分成几个阶段,每个阶段有自己的检查点。
清单的目标不是"覆盖所有可能",而是"确保关键步骤不被遗漏"。如果你试图用清单替代培训,那清单注定会失败。
7. 常见反模式
7.1 "写了清单,但没人看"
根本原因通常有三个:
-
清单不在工作流里。如果清单是一个 Confluence 页面,但部署操作是在终端里执行的,那工程师不会专门切到浏览器去翻清单。解法:把关键检查点嵌入 CI/CD 管线或者部署脚本里,用自动化强制执行。
-
清单太长、太细。一个 30 步的清单让人看了就烦。精简到关键检查点,非关键的步骤靠自动化或者培训覆盖。
-
清单和实际操作脱节。上次写的,环境早变了,步骤对不上。没人愿意看一份"大概率过时"的文档。
7.2 "写了清单,但不更新"
SOP 不是写完就锁进柜子的东西。每次操作后,应该有一个"回顾"环节:
- 这次有没有跳过某个步骤?为什么?
- 这次有没有发现清单没覆盖到的情况?
- 这次的实际耗时和预期差多少?
把这些反馈写回清单里。SOP 应该是一个"活文档",有版本号、有更新记录、有 owner。
7.3 "用清单代替思考"
清单是"防遗漏"的工具,不是"防蠢"的工具。
如果一个工程师照着清单执行,但完全不理解每一步在做什么,那他只是一个人形脚本——而且还是一个不如真正的脚本可靠的人形脚本。
清单的正确用法是:你已经理解了整个操作,清单帮你确认没有遗漏。而不是:你不理解整个操作,但清单告诉你每一步怎么做。
前者叫"安全网",后者叫"拐杖"。安全网让高手更安全,拐杖让新手更危险。
8. 实战场景:三个"有清单 vs 没清单"的对比
场景一:数据库 schema 变更
没清单的版本:
"我跑一下迁移脚本,应该几秒钟就好。" (20 分钟后) "呃……好像锁表了,线上请求全超时了。"
有 MOP 的版本:
步骤 1: 确认目标库 hostname(✅ prod-db-01) 步骤 2: 确认表大小(users 表 1200 万行 → 需要用 pt-online-schema-change) 步骤 3: 在低峰期执行(UTC 06:00,北京时间 14:00) 步骤 4: 监控锁等待时间,超过 5 秒自动暂停 步骤 5: 完成后验证——新列存在、旧数据无损
场景二:新服务首次上线
没清单的版本:
"代码 ready 了,CI 过了,直接上吧。" (上线后发现:没配监控告警、没配日志采集、健康检查路径写错了、域名 DNS 没切)
有 MOP 的版本:
前置检查: - [ ] 健康检查端点 /healthz 返回 200 - [ ] Prometheus metrics 端点 /metrics 可访问 - [ ] 日志已接入 ELK - [ ] 告警规则已配置(P99 延迟 > 500ms、错误率 > 1%) - [ ] DNS 记录已创建(灰度域名 + 正式域名) - [ ] 回滚版本:N/A(首次上线,回滚 = 下线)
场景三:AI 生成的代码部署
没清单的版本:
"Copilot 写的代码,看上去挺好的,merge 了直接发。" (上线后发现:AI 生成的 SQL 查询没有加索引条件,全表扫描拖垮了数据库)
有 SOP 的版本:
AI 辅助代码的额外检查项: - [ ] 是否有未经 review 的 SQL 查询? - [ ] 是否引入了新依赖?版本是否固定? - [ ] 是否有硬编码的配置值? - [ ] 性能测试是否覆盖了 AI 生成的关键路径?
9. 总结:不要赌你的运气
让我们回到最开头的问题:为什么 AI 时代更需要 MOP/SOP?
三个理由:
-
复杂性在涨。微服务、多云、多区域、多团队……系统的复杂度已经远超个人认知能力。清单是用 O(n) 的成本对抗 O(n²) 复杂度的唯一可行方案。
-
速度在涨。AI 让开发更快、部署更频繁。但速度越快,安全措施就越不能打折。高速公路的限速比城市道路高,但安全标准也更高。
-
容错率没变。不管你的代码是人写的还是 AI 写的,一旦上了生产环境,一条错误的命令就是一条错误的命令。用户不关心你的代码是谁写的,他们只关心服务是否正常。
《清单革命》里有一句话我特别喜欢:
"The volume and complexity of what we know has exceeded our individual ability to deliver its benefits correctly, safely, or reliably. Knowledge has both saved us and burdened us."
("我们所掌握的知识的数量和复杂度,已经超过了个人正确、安全、可靠地运用它的能力。知识既拯救了我们,也成了我们的负担。")
清单不是因为你"不行"才需要的。清单是因为事情太复杂而人太容易犯错才需要的。
写一份 MOP,花半小时。不写 MOP 翻一次车,花半天到半个月修复,外加一份事后复盘报告和若干个失眠的夜晚。
这笔账,谁都算得清。
行动清单
明天就可以做的 5 件事:
- [ ] 盘点:列出你团队最近 3 个月的所有生产变更,哪些有 MOP/SOP,哪些是"口头通知就上了"
- [ ] 模板:用本文的 MOP 模板,给下一次部署写一份——哪怕只是一个简单的版本升级
- [ ] 自动化:把至少 3 个检查项嵌入你的 CI/CD 管线(比如:是否有回滚方案、是否有监控告警、是否通过 staging 验证)
- [ ] Review:找一位同事互相 review 彼此的 MOP,就像 code review 一样
- [ ] 复盘:下次变更后花 15 分钟回顾 MOP,把实际发生的和预期不一致的地方更新进去
思维导图
@startmindmap
* MOP/SOP\n清单革命
** What 是什么
*** SOP - 标准操作流程
**** 日常重复操作
**** 团队共识的固化
*** MOP - 操作方法步骤
**** 一次性变更
**** 含回滚方案
**** 需要审批
** Why 为什么
*** 人一定会犯错
**** 无知之错 vs 无能之错
**** 认知的结构性缺陷
*** 复杂性超过个人能力
**** 微服务/多云/多区域
**** 178 项操作的 ICU 类比
*** 生产环境容错率极低
**** MTTR 30分钟~4小时
**** 信任恢复远比修复慢
** AI 时代的挑战
*** 生产速度↑ 安全要求不变
*** 部署频率↑ 风险窗口更多
*** AI 代码看起来"太合理"
*** AI 起草 + 人工 review + 严格执行
** AI Skill = 给 AI 写的 SOP
*** 结构同构
**** 触发条件/前置/步骤/约束
*** AI 也有"无能之错"
**** 上下文遗漏/过度自信
*** Skill 可自动执行
**** 不会打折扣的执行者
*** 双层清单
**** 人: 决策判断 + 审批
**** AI: 精确执行 + 一致性检查
** How 怎么做
*** MOP 模板
**** 目标/范围/前置条件
**** 步骤+验证+回滚
**** 通知+审批
*** 三条黄金原则
**** 每步有验证方法
**** 回滚是主菜不是附赠
**** 清单要短到真的会看
** 反模式
*** 写了没人看
*** 写了不更新
*** 用清单代替思考
@endmindmap
系列回顾
本文是"职场工具箱"系列的一篇。这个系列试图把那些听起来很"方法论"的工具,写成你下周一就能用上的实战指南。
- RICE / ICE:把优先级从拍脑袋变成可讨论
- MoSCoW:需求太多做不完时的减法艺术
- PgVector RAG:用 PostgreSQL 做检索增强生成
- DoD:为什么交付后争议才开始?
- MOP/SOP:AI 时代更需要"清单革命" ← 本文
扩展阅读
- Atul Gawande, The Checklist Manifesto, 2009 — 清单革命的经典之作
- Google SRE Book, Chapter 14: Managing Incidents — 事故管理的标准流程
- PagerDuty Incident Response Documentation — 开源的事故响应文档模板
- AWS Well-Architected Framework, Operational Excellence Pillar — 运维卓越最佳实践
本作品采用知识共享署名-非商业性使用-禁止演绎 4.0 国际许可协议进行许可。